Indexing
Support for OST files: In addition to PST files, DocFetcher Pro and DocFetcher Server can also read OST files. However, you should know that OST files are really just cache files where Outlook temporarily stores some portion of the data from an online account for offline use. Thus, if you index OST files, you will find that many emails and email attachments you would expect to see are simply not there. PST files are what Outlook uses for complete, long-term storage of emails, so always prefer indexing PST files to indexing OST files where possible. For more info on PST and OST files, and instructions on how to export to PST files, see this page from Microsoft.
Handling of PST and OST files as archives: DocFetcher handles PST files as a special kind of data source. In contrast, DocFetcher Pro and DocFetcher Server handle PST and OST files as if they were archive files, in principle no different than zip, 7z or rar files. This has two significant advantages:
- Batch indexing of PST and OST files: In DocFetcher, the only way to index a dozen or even a hundred PST files is to select them for indexing one at a time. In DocFetcher Pro and DocFetcher Server, since PST and OST files are just archives, you can just select the parent folder containing all of these files and index them all in one go.
- Indexing compressed PST and OST files: In DocFetcher Pro and DocFetcher Server, since PST and OST files are just archives, they are fully integrated with the program’s ability to traverse archives to an arbitrary level of archive nesting. In concrete terms, that means DocFetcher Pro and DocFetcher Server can for example read a PST file inside a zip archive, which in turn is inside a 7z archive, which in turn… and so on. Something like this:
C:\...\archive1.7z\archive2.zip\Outlook.pst
This is something that’s not possible with DocFetcher; the latter can only handle uncompressed PST files.
Indexing emails with HTML or RTF bodies only: Emails usually have either a plain text body, an HTML body, an RTF body, or any combination of these. DocFetcher can only read plain text bodies, so if for example an email has only an HTML body and no plain text body, then DocFetcher fails to extract any text from the body. As a consequence, the email will likely never show up in the results. In contrast, DocFetcher Pro and DocFetcher Server will first try to read the email’s plain text body. If the plain text body is not present, the HTML body is used as fallback. If the HTML body is not present either, then the RTF body is used as fallback.
Indexing archive attachments: DocFetcher can index email attachments, with one important caveat: It cannot look inside archive files. So for example, if during indexing it sees an email to which a PDF file and a zip file are attached, the email and the PDF file are indexed, whereas whatever is inside the zip file is excluded. In DocFetcher Pro and DocFetcher Server, the contents of the zip file are indexed too, and even unlimited levels of archive nesting are supported, e.g., a 7z file inside the zip file.
Results
Icon overlay for emails with attachments: In the result pane of DocFetcher Pro and DocFetcher Server, emails with attachments have an additional overlay over their icons to indicate the presence of the attachments:
Preview
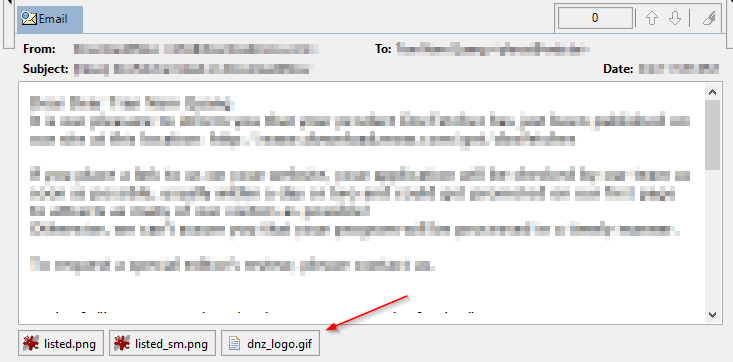
Email attachments bar: In the email preview of DocFetcher Pro, if the email in question has attachments, an attachments bar is displayed at the bottom of the preview, as shown in the following screenshot. Left-clicking an attachment opens it in the external viewer associated with the file type. Right-clicking opens a context menu with “Open”, “Save”, “Open All” and “Save All” actions. If the total width of the attachment controls is greater than the available horizontal space, you can drag the attachments bar left and right to reveal hidden attachments. DocFetcher Server currently has the same attachments bar, but with less functionality: You can only download one attachment at a time, and instead of drag support there’s a horizontal scrollbar. Server