DocFetcher Pro and DocFetcher Server are two pieces of commercial software related to the free and open-source desktop search software DocFetcher.
DocFetcher Pro
DocFetcher Pro is the big brother on steroids of the free DocFetcher. Both DocFetcher and DocFetcher Pro are desktop search software that can be run on Windows, Linux and macOS.
What is desktop search? To put it simply, desktop search is to your computer what Google is to the internet: It allows you to quickly find files on your computer by typing in words contained in not just the filename, but also the file contents.
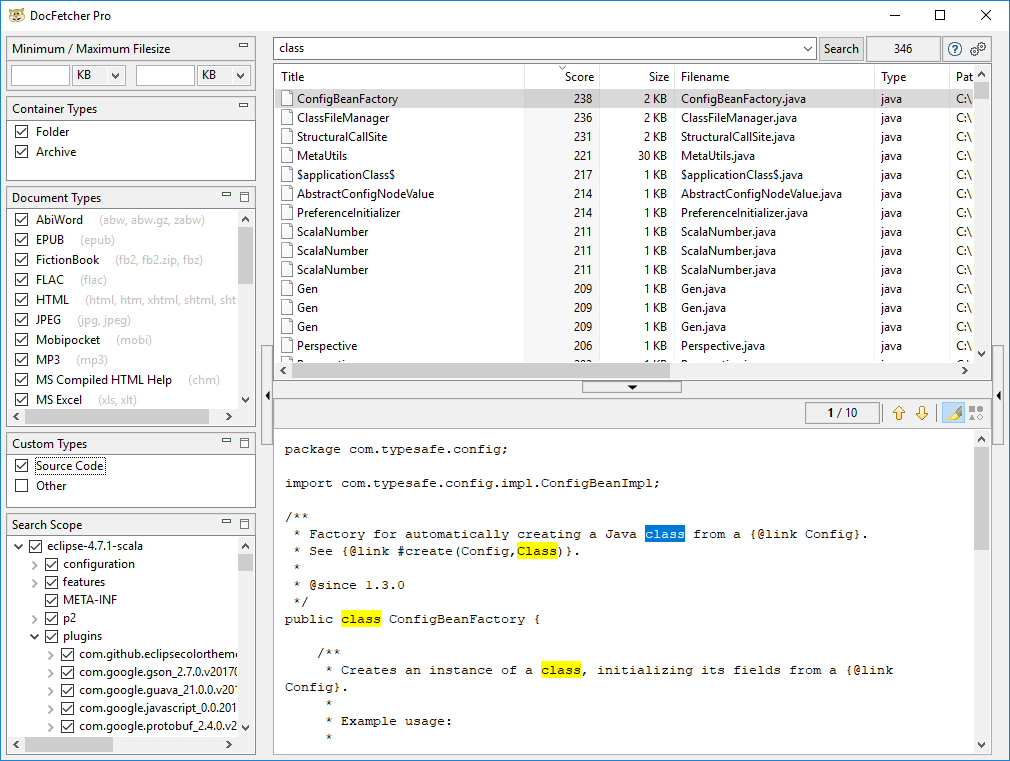
Why use desktop search software like DocFetcher Pro even though the latest iterations of Windows and other operating systems come with built-in file content search? Because unlike the built-in search, DocFetcher Pro is designed to be easy to use, and to actually find what you’re looking for, all without slowing your computer to a crawl.
DocFetcher Server
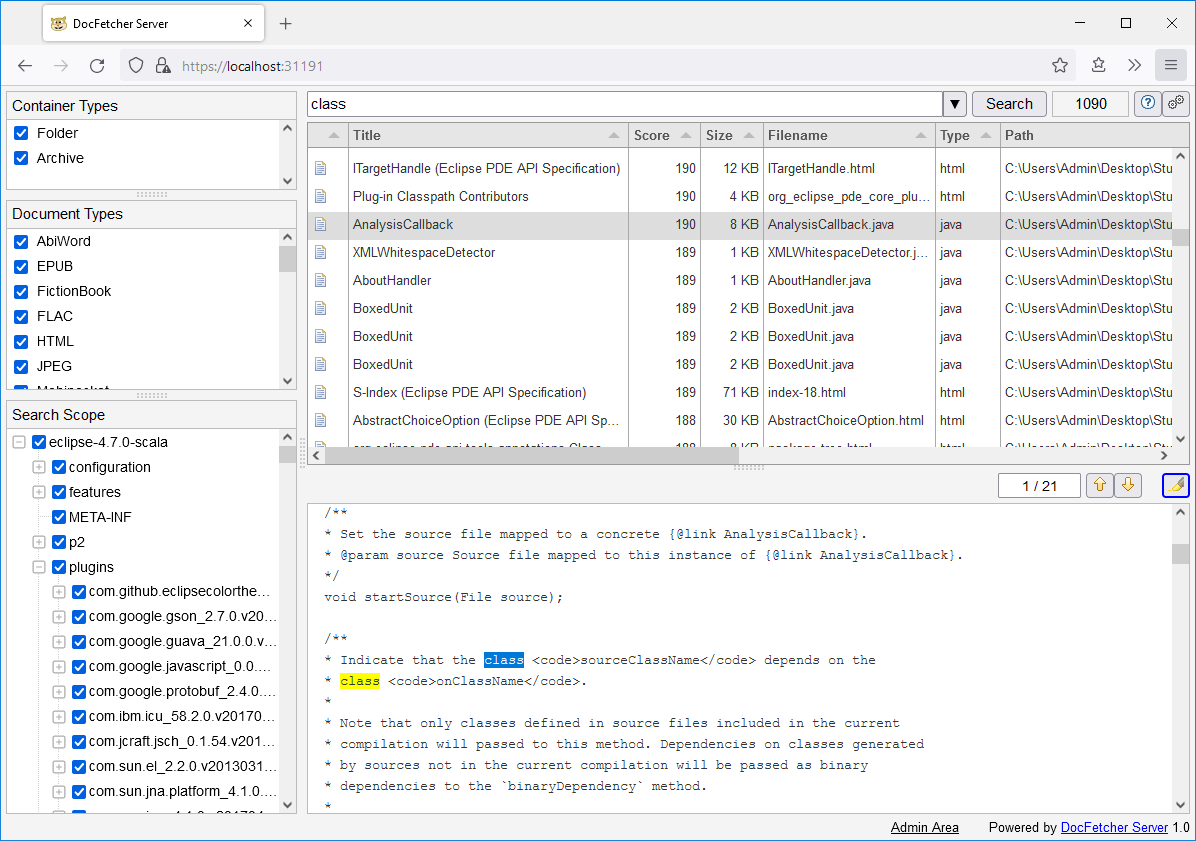
DocFetcher Server is a cousin of DocFetcher and DocFetcher Pro. It features a server-client architecture and can be accessed through the web browser, making it suitable as a search server in a private or company network, or as a search server for remote access over the internet. While DocFetcher Server can be run on Windows, Linux and macOS, it can be accessed from any desktop computer on which an up-to-date version of Chrome, Firefox, Safari or Edge is installed.
Project History
DocFetcher (2007): The free and open-source DocFetcher was first published in 2007 and is now legacy software, meaning it is no longer being actively developed. However, it will still receive bugfixes and support, funded through DocFetcher Pro and DocFetcher Server. In addition, DocFetcher’s open-source license guarantees that it will remain free forever. Thus, DocFetcher is now essentially the free, “basic” version, while DocFetcher Pro and DocFetcher Server are the paid versions with fewer bugs and more features.
DocFetcher Pro (2021): DocFetcher Pro was first published in 2021 and is a full rewrite of the old DocFetcher, incorporating much improved programming technology and over a decade of lessons learned.
DocFetcher Server (2022): DocFetcher Server was first published in 2022 and provides support for remote access and multiple users, two fundamental features that DocFetcher and DocFetcher Pro lack. Core functionality like indexing and searching was carried over from DocFetcher Pro, while the server-client architecture and web UI were written from scratch.