This page is an overview of all the major features of DocFetcher Pro and DocFetcher Server, intended for those who are not familiar with DocFetcher. If you are, you may find the Comparison page and its subpages more helpful.
All screenshots below show the user interface of DocFetcher Pro. The web interface of DocFetcher Server looks similar and is nested inside a browser window.
The User Interface
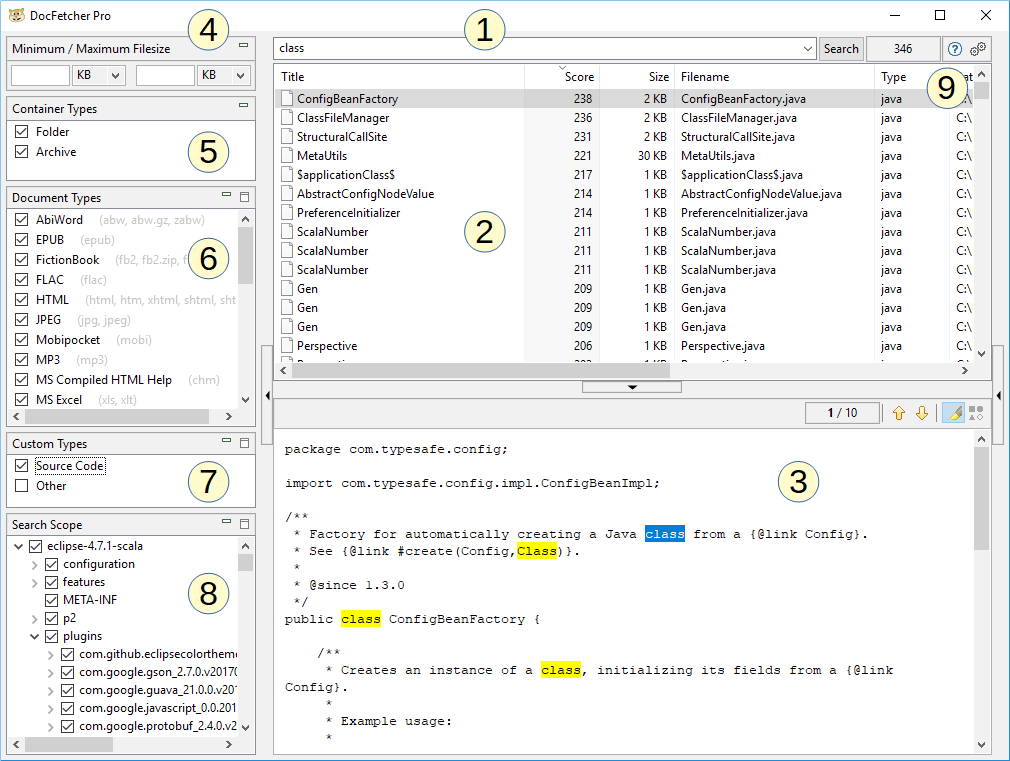
As shown in the screenshot above, the main window of DocFetcher Pro consists of the following parts:
- Search field: Enter the words to search for here.
- Result pane: The search results are displayed here. These are the files, folders or Outlook emails containing the words you entered in the search field.
- Preview pane: Shows a text-only preview of the file or Outlook email currently selected in the result pane. Matches in the text are highlighted.
- Minimum / Maximum File Size filter: The search results can be filtered by minimum and/or maximum filesize here. Free Available in the free DocFetcher Pro Available in DocFetcher Pro Server Not available in DocFetcher Server
- Container Types pane: Set here whether folders and archives should be included in the search results. In DocFetcher, folders and archives are not included in the search results, only files and Outlook emails. Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Available in DocFetcher Server
- Document Types pane: The search results can be filtered by file type here.
- Custom Types pane: An alternative to the Document Types pane. Here you can define your own file types to filter the search results by. The definitions are based on matching wildcard patterns or regular expressions against filenames. Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Not available in DocFetcher Server
- Search Scope pane: This pane has two purposes: Filtering the search results by location, and managing your “indexes”, which are explained below. Indexes can be added, updated and removed. Each index corresponds to some searchable location on your computer.
- Various controls: The three controls on the right of the Search button are: the number of currently visible search results, a button to open the user manual, and a button to open the program preferences.
Powerful Query Syntax

The above screenshot shows an example of the kinds of complex search queries you can enter in DocFetcher, DocFetcher Pro and DocFetcher Server. The example query means: Find all documents containing (1) the phrase “reproduction or redistribution”, and (2) the words “documentation” and “agreement” at most three words apart.
The query syntax is powered by the underlying search engine Apache Lucene. Here’s a quick rundown of its major features:
- Boolean operators: (dog OR cat) AND mouse NOT horse
- Phrase search, i.e., finding words in a specific order: "dog cat mouse"
- Required terms: +dog +cat
- Wildcards: Placeholder characters * and ? to match ‘zero or more’ characters and ‘exactly one’ character, respectively. Examples:
- luc? matches lucy, luca, …
- luc* matches luc, lucy, luck, lucene, …
- *ene* matches lucene, energy, generator, …
- Fuzzy search, i.e., finding words that are similar to a given word. For example, searching for roam~ will turn up documents containing words like foam and roams.
- Proximity search, i.e., finding words that are not more than a certain number of words apart. Example: "documentation agreement"~3
Index-based Search
Index-based search: DocFetcher, DocFetcher Pro and DocFetcher Server search for words in the filename and file contents of files, as well as in the fields and body of Outlook emails. However, for the sake of efficiency, the search runs on so-called indexes, rather than on the files and emails directly. An index is essentially a dictionary where the program can quickly look up for any given word which files or emails contain that word.
Trade-off: fast search and index creation: Index-based search is a great idea because it is by orders of magnitude faster than searching without indexes: DocFetcher, DocFetcher Pro and DocFetcher Server can typically find thousands of matching files in less than a second. The main downside is that the indexes have to be created first — a process known as indexing — and this can take some time depending on the total number of files and emails, and their individual sizes.
Fast indexing and “index only what you need” philosophy: The downside of having to create an index is alleviated by the fact that indexing in DocFetcher, DocFetcher Pro and DocFetcher Server is quite fast: 200 files per minute is a pretty normal indexing speed. In addition, the three programs follow an “index only what you need” philosophy: Out of the box, nothing on your computer is indexed, and it is entirely up to you to decide what gets indexed. This is in contrast to other pieces of search software that out of the box waste a ton of time and computer power to index basically everything, since they don’t trust you to decide on your own. Not to mention the privacy implications of this “index everything” approach…
Index creation vs. index update: Last but not least, indexing a particular folder is usually only time-consuming the first time around, if at all. Afterwards, whenever you run a so-called index update, the program will be smart enough to index only new and modified files, skipping everything else. In practice, usually only a relatively small number of files will have been added or modified, so an index update usually takes little time.
Creating Indexes
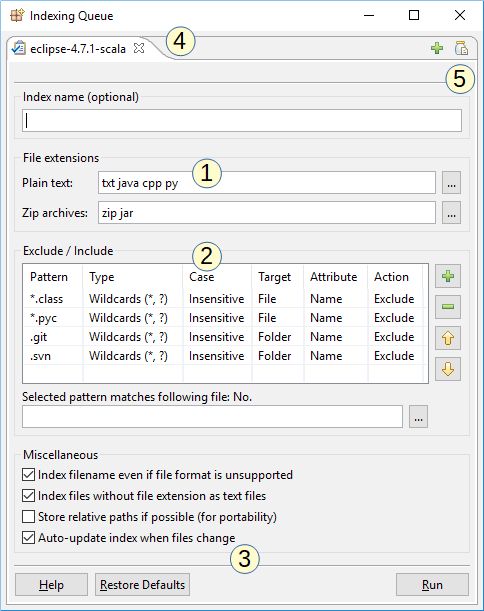
The above screenshot shows the indexing dialog of DocFetcher Pro. This is the configuration dialog you see when creating a new index. Notable features:
- Customizable plain text and zip extensions: The file extensions by which the program recognizes plain text files and zip archives can be customized. Customizing plain text file extensions is useful when dealing with source code.
- Inclusion and exclusion rules: You can define rules to include or exclude certain files based on wildcard or regular expression matching. This table also exists in DocFetcher, but wildcards and the inclusion rule are only available in DocFetcher Pro and DocFetcher Server. Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Available in DocFetcher Server
- Automatic updating of indexes: If the “Auto-Update Index” box is checked, the program will watch the indexed folder for file changes and update the index automatically when a change is detected.
- Indexing queue: Multiple indexing jobs can be queued, which each job on a separate tab.
- Saving and loading indexing settings: This “jar” button opens a menu for saving and loading indexing settings. This comes in handy if you need to define a lot of inclusion and exclusion rules. Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Not available in DocFetcher Server
Supported Document Formats
- AbiWord (abw, abw.gz, zabw)
- EPUB (epub)
- FictionBook (fb2, fbz, fb2.zip) Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Available in DocFetcher Server
- FLAC metadata (flac)
- HTML (html, xhtml, …)
- JPEG Exif metadata (jpg, jpeg)
- MP3 metadata (mp3)
- Microsoft Compiled HTML Help (chm)
- Microsoft Office pre-2007 (doc, xls, ppt, …)
- Microsoft Office 2007 and newer (docx, xlsx, pptx, …)
- Microsoft Outlook OST (ost) * Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Available in DocFetcher Server
- Microsoft Outlook PST (pst) *
- Microsoft Visio (vsd, vss, vst, vsw)
- Mobipocket (mobi) — support is currently experimental Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Available in DocFetcher Server
- OpenDocument (odt, ods, odg, odp, …)
- Portable Document Format (pdf)
- Plain Text (customizable extensions)
- Rich Text Format (rtf)
- Scalable Vector Graphics (svg)
For any file format not included in the above list, at least the filename can be indexed. Also, any file format identifiable by a specific file extension can be forcibly indexed as plain text, as the plain text file extensions are customizable.
* Limitations of PST and OST file support
No email preview: For technical reasons, neither DocFetcher nor DocFetcher Pro nor DocFetcher Server can open emails in the search results with Outlook. The emails can only be shown in the program’s text-only preview pane. The ability to open emails in Outlook may be added in a future major release of DocFetcher Pro (v2.0 or later). It cannot be implemented in DocFetcher Server since the user’s Outlook instance and the PST or OST file containing the email reside on potentially different computers.
Prefer PST to OST: While DocFetcher Pro and DocFetcher Server can read OST files to some extent, be warned that OST files are actually just cache files where Outlook temporarily stores some portion of the data from an online account for offline use. Thus, if you index OST files, you will find that many emails and email attachments you would expect to see are simply not there. PST files are what Outlook uses for complete, long-term storage of emails, so always prefer indexing PST files to indexing OST files where possible. For more info on PST and OST files, and instructions on how to export to PST files, see this page from Microsoft.
Large PST and OST files: To index a PST or OST file, the application has to load the entire file into RAM. Thus, indexing PST or OST files that are larger than the available amount of RAM (e.g., 30 GB PST file vs. 16 GB RAM) is not supported, and attempts to do so will crash the application. To deal with this problem, you can either exclude the large PST or OST file from indexing, or upgrade your RAM. In case of RAM upgrade, note that the total amount of RAM needed is bigger than the PST or OST file, due to the fact that the operating system and other processes take up some of that RAM.
Disclaimer about best-effort indexing
Like virtually all search software, DocFetcher, DocFetcher Pro and DocFetcher Server support the various file formats listed above on a best-effort basis. This means, for example, if you try to index 10,000 files, then the software may successfully index only 9,500 files (i.e., 95%), while failing on the remaining 500 files. Of course the actual success rate depends on your dataset.
Furthermore, even if a particular file is successfully indexed, the software may fail to extract some text in it, especially when dealing with old file formats like “doc” or “xls”. For example, it may fail to extract some cell comments or metadata from ancient Excel files.
In any case, DocFetcher Pro and DocFetcher Server will most likely do a better job of indexing files than the older DocFetcher.
If you see a particularly high failure rate during indexing, by all means report the issue, with some test files attached. However, there’s no guarantee that the issue can be resolved.
Supported Archive Formats
- 7z archives (7z), up to version v0.3 of the 7z format
- 7z archives (7z), up to version v0.4 of the 7z format (since 7-Zip 9.34, from 2014-11-23) Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Available in DocFetcher Server
- Rar archives (rar) — RAR 5.0 format not supported
- Tar and Tar.* archives:
- tar, tar.gz, tgz, tar.bz2, tb2, tbz
- tbz2, tar.lzma, tlz, tar.xz, txz, tar.z, tz Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Available in DocFetcher Server
- Zip archives (customizable extensions)
Other Notable Features
Cross-platform: DocFetcher, DocFetcher Pro and DocFetcher Server can be run on Windows, Linux and macOS. In addition, DocFetcher Server can be accessed from any desktop computer with an up-to-date version of Chrome, Firefox, Safari or Edge installed.
Portable version: The DocFetcher Pro packages for Windows, Linux and macOS each come in a portable and non-portable version. The portable version is useful in that it allows you to bundle up portable DocFetcher Pro, its indexes and the indexed documents, to be used in a variety of ways:
- You can carry this bundle around on a USB drive.
- You can archive it on some backup medium.
- You can put it in an encrypted volume.
- You can put it in a cloud drive and synchronize it across computers.
Please note that redistributing such portable bundles to other users is not permitted with DocFetcher Pro, as each purchased copy is tied to a single user. (Every receiving user would have to buy their own copy.) Redistribution is permitted with the open-source DocFetcher, however.
Unicode support: DocFetcher, DocFetcher Pro and DocFetcher Server come with rock-solid Unicode support for all major formats, including Microsoft Office, OpenDocument, PDF, HTML, RTF and plain text files.
Indexing network drives: DocFetcher, DocFetcher Pro and DocFetcher Server can index network drives as well as cloud drives. More generally, if a data structure can be mounted as something that looks like a file system in the OS, then all three programs are able to index it.
Detection of HTML pairs: During indexing, DocFetcher, DocFetcher Pro and DocFetcher Server detect pairs of HTML files (e.g., a file named foo.html and a folder named foo_files), and treat each pair as a single document. This feature may seem rather useless at first, but it turned out that this dramatically increases the quality of the search results when you’re dealing with HTML files, since all the “clutter” inside the HTML folders disappears from the results.