< назад до батьківської сторінки
Оновлення таблиці шаблонів
Таблиця шаблонів в діалозі індексації DocFetcher Pro і таблиця шаблонів на панелі індексації DocFetcher Server відрізняються від тієї, що в DocFetcher, наступним чином:
- На додаток до регулярних виразів, ви можете використовувати менш потужні, але також значно простіші маски * і ? для написання правил відповідності. Маска * є заповнювачем для нуля або більше символів, тоді як маска ? є заповнювачем для рівно одного символу.
- Нова дія «Включити» на додаток до дії «Виключити».
- Дія «Визначення типу mime» зникла. Якщо ви хочете індексувати файли без розширення як текстові файли, використовуйте прапорець з тим же описом під таблицею шаблонів.
- Пошук відповідностей може бути як чутливим до регістру, так і нечутливим до регістру. У DocFetcher, з іншого боку, пошук відповідностей завжди чутливий до регістру.
- Пошук відповідностей можна виконувати не тільки для звичайних файлів, але й для тек і архівних файлів.
- У Windows, коли правила порівнюються з шляхами файлів, останні використовуватимуть символ \ як розділювач шляху, а не символ /. Приклад: C:\Шлях\До\Файл.docx, замість C:/Шлях/До/Файл.docx.
В результаті, ось як виглядає таблиця шаблонів у DocFetcher Pro:
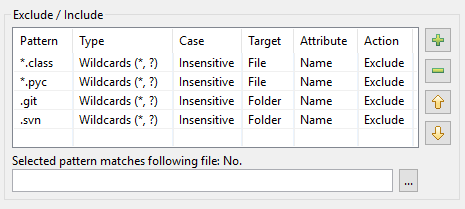
Таблиця шаблонів у DocFetcher Server виглядає так само, але тестовий віджет «Обраний шаблон відповідає наступному файлу» під таблицею наразі недоступний. Server Not available in DocFetcher Server
Натисніть тут для детального обговорення таблиці шаблонів у DocFetcher, DocFetcher Pro та DocFetcher Server.
Ось як відбулося оновлення таблиці шаблонів у DocFetcher Pro та DocFetcher Server. Почнемо з самого початку: У діалозі індексації DocFetcher є таблиця шаблонів для виконання певних дій над файлами, які відповідають певним шаблонам під час індексації:
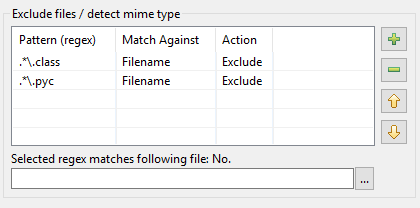
Шаблони повинні бути так званими регулярними виразами, а щодо дій, то у DocFetcher доступні дві: виключення відповідного файлу з індексації та «визначення типу mime», тобто спроба вгадати правильний спосіб розбору відповідного файлу на основі вмісту файлу, а не на основі його імені. Поки що все добре. Однак на практиці виявляється, що вищезазначена реалізація має ряд проблем:
- Дуже мало людей знають, як писати регулярні вирази.
- Іноді потрібно індексувати лише певні файли, а не марно витрачати час індексації на щось інше. Наприклад, індексувати лише файли «txt» і нічого іншого. DocFetcher фактично може це зробити, але це вимагає досить складної роботи з регулярними виразами.
- Іноді потрібно виключити з індексації всі файли, що відповідають певному шаблону, за винятком всіх файлів, що відповідають певному іншому шаблону. Наприклад, виключити з індексації всі PDF-файли, за винятком PDF-файлів, імена яких починаються з «звіт_». Знову ж таки, у DocFetcher це вимагає складного використання регулярних виразів.
- Загалом, визначення типу mime є досить марним через те, що: (1) Розширення файлу майже завжди правильне і тому в більшості випадків це все, що потрібно для визначення формату файлу. (2) Коли розширення файлу неправильне і потрібне визначення типу mime, останнє виявляється не особливо надійним. (3) Ніхто не турбується і/або не знає, як писати правила відповідності для тих рідкісних випадків, коли визначення типу mime дійсно потрібне. Однак, у контексті DocFetcher виявляється, що визначення типу mime все ж має один важливий випадок використання: змушення програми трактувати файли без розширення як звичайні текстові файли, наприклад, файли з назвою README. Однак однак, щоб це зробити, потрібно написати цей незрозумілий регулярний вираз: [^.]*
- Визначення типу mime може не змогти ідентифікувати файл як звичайний текст, якщо файл містить деякі двійкові дані.
- Через те, що переносна версія DocFetcher повинна працювати на всіх підтримуваних платформах, при зіставленні правил із шляхами файлів, останні завжди використовують символ / як розділювач шляху, навіть у Windows, що досить неінтуїтивно для більшості користувачів Windows.
Коротко кажучи, таблиця шаблонів DocFetcher - це повний безлад, і переписування, яке прийшло з DocFetcher Pro, було гарною можливістю все це прибрати:
- Маски були додані і встановлені як типові, так що тепер навіть прості смертні можуть писати правила відповідності.
- Дія «Включити» охоплює як випадок, коли потрібно індексувати лише певний тип файлу, так і випадок, коли потрібно визначити винятки для правил відповідності. Тепер навіть винятки-до-винятків можливі.
- Загалом марна дія «Визначення типу mime» зникла, а її основний випадок використання, індексація файлів без розширення як текстових файлів, покривається простим прапорцем під таблицею шаблонів. І цей прапорець працює навіть якщо файл містить деякі двійкові дані.
- Проблема розділювача шляхів Windows виправлена.
- І деякі інші речі (чутливість до регістру і відповідність файлам/текам/архівам) були додані для повноти.
Завантаження та збереження налаштувань індексації
Примітка: Ця функція наразі доступна лише в DocFetcher Pro, а не в DocFetcher Server. Server Not available in DocFetcher Server
Проблема: У DocFetcher, кожного разу коли ви створюєте новий індекс, ви повинні вводити всі правила в таблиці шаблонів по одному. Це стає досить втомливим, якщо у вас багато таких правил. Просто немає способу завантажити і зберегти їх.
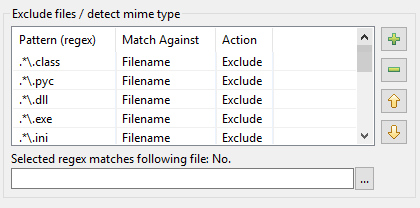
У DocFetcher Pro вищезазначена проблема вирішується наступним чином: У верхньому правому куті діалогу індексації DocFetcher Pro знаходиться непомітна маленька кнопка «банка з документом». Клацання цієї кнопки відкриває меню, що містить різні дії для завантаження та збереження налаштувань індексації:
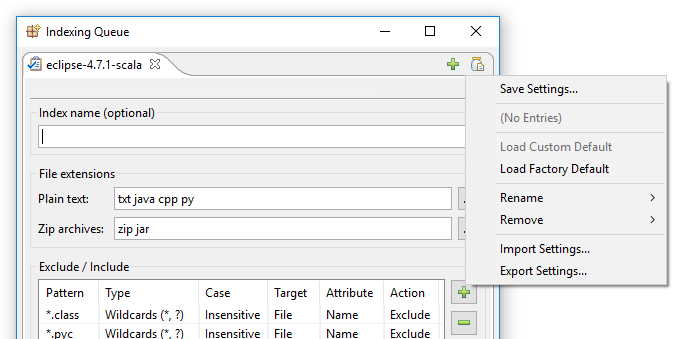
Клацання на «Зберегти налаштування» відкриває цей діалог:
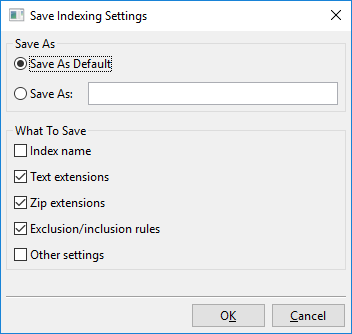
По суті, що ви можете робити з цим діалогом, це або зберегти поточно видимі налаштування індексації у новий іменований слот, наприклад, «Мої нові налаштування індексації», або зберегти поточно видимі налаштування індексації як новий типовий.
Цей типовий називається «Користувацькі налаштування» і буде завантажуватися автоматично при створенні нових індексів. Також є «Заводські налаштування», який є типовим, що DocFetcher Pro використовує з коробки. Іменовані налаштування, які ви створили, а саме «Користувацькі налаштування» і «Заводські налаштування», можуть всі завантажуватися через меню, показане вище.
Для завершення, меню також дозволяє імпортувати та експортувати всі ваші налаштування індексації, щоб ви могли повторно використовувати їх при налаштуванні DocFetcher Pro в новому середовищі.
Інші помітні покращення
Підтримка FB2: DocFetcher Pro і DocFetcher Server мають підтримку формату електронних книг FB2. Zip-стиснені FB2 файли з розширенням fb2.zip або fbz підтримуються «нативно», тобто DocFetcher Pro і DocFetcher Server бачать кожен такий файл як окремий файл, а не як файл, обернений у zip-архів.
Експериментальна підтримка Mobipocket: DocFetcher Pro і DocFetcher Server мають підтримку формату електронних книг Mobipocket з розширенням «mobi». Однак зауважте, що хоча DocFetcher Pro і DocFetcher Server загалом досить добре справляються з витягуванням тексту з mobi файлів, вони наразі або не можуть витягти невелику частину тексту в кінці файлу, або в деяких випадках повністю зазнають невдачі. Тому підтримка Mobipocket поки що позначена як експериментальна.
Підтримка 7z архівів для поточного формату v0.4: DocFetcher може читати 7z архіви до v0.3 формату 7z архіву. DocFetcher Pro і DocFetcher Server також можуть читати 7z архіви в поточному форматі v0.4. Цей формат v0.4 був представлений з 7-Zip 9.34, випущений 2014-11-23.
Розширена підтримка tar архівів: DocFetcher підтримує наступні розширення tar архівів: tar, tar.gz, tgz, tar.bz2, tb2, tbz. DocFetcher Pro і DocFetcher Server додатково підтримують наступні розширення tar архівів: tbz2, tar.lzma, tlz, tar.xz, txz, tar.z, tz
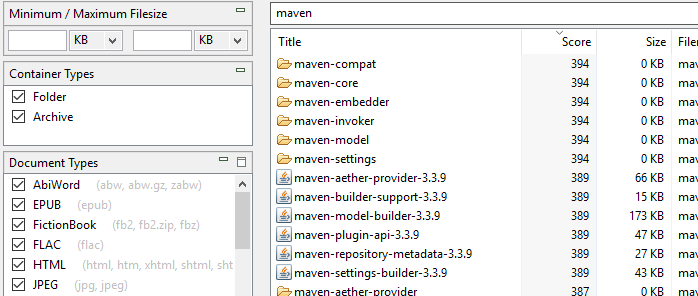
Індексація імен тек і архівів: На відміну від DocFetcher, DocFetcher Pro і DocFetcher Server індексують не лише звичайні файли, але й теки та архівні файли — або точніше, імена тек і архівних файлів. Таким чином, теки та архівні файли з’являтимуться у результатах пошуку DocFetcher Pro і DocFetcher Server. Також є панель Типи контейнерів в лівій частині головного вікна додатка для виключення тек і/або архівів з результатів пошуку.
MacOS: Демон для автоматичного оновлення індексу: DocFetcher і DocFetcher Pro здатні на автоматичне оновлення індексу, тобто замість того, щоб запускати оновлення індексу вручну, оновлення індексу запускається програмою, як тільки виявляються зміни файлів. Однак ця функціональність доступна лише тоді, коли дві програми фактично працюють. Коли вони не працюють, потрібен окремий процес демону для заповнення прогалини. У DocFetcher демон доступний лише на Windows і Linux, тоді як у DocFetcher Pro він також доступний на macOS. Що стосується DocFetcher Server, демон не потрібен, оскільки сервер призначений для безперервної роботи. Server Not available in DocFetcher Server
Розумніша індексація імен файлів: Індексація імен файлів у DocFetcher Pro і DocFetcher Server розумніша, ніж у DocFetcher. Наприклад, якщо DocFetcher зустрічає файл з назвою знайти_цей_файл.pdf, він бачить «знайти_цей_файл» як одне слово, а не як три окремі слова, з’єднані разом. Таким чином, DocFetcher знайде цей файл лише якщо ви буквально введете «знайти_цей_файл» в поле пошуку DocFetcher. DocFetcher Pro і DocFetcher Server, з іншого боку, знайдуть файл, якщо ви введете «знайти_цей_файл» або будь-яке з трьох окремих слів. Загалом кажучи, те, що роблять DocFetcher Pro і DocFetcher Server, це розпізнавання символів, таких як підкреслення, як потенційних розділювачів слів.

Індексація імен файлів у випадку помилок: Якщо DocFetcher Pro і DocFetcher Server не вдається прочитати вміст файлу через якусь помилку або через захист паролем, ім’я файлу все одно індексується. У DocFetcher, з іншого боку, файл повністю пропускається.
Жодних помилок з глибоко вкладеними структурами тек: При спробі індексувати глибоко вкладені структури тек, такі як C:\тека1\тека2\...\тека99\тека100, DocFetcher схильний до збою з помилкою «Ієрархія тек занадто глибока». У програмістському жаргоні це називається «переповненням стека». DocFetcher Pro і DocFetcher Server, з іншого боку, повністю захищені від такого роду помилок.
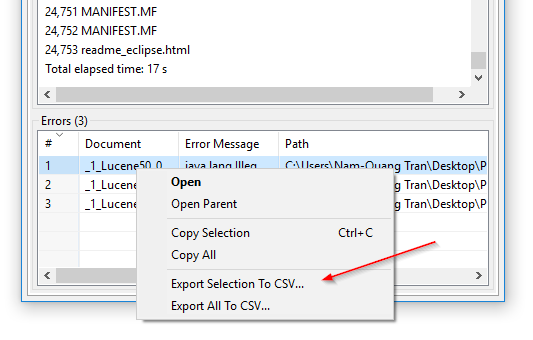
CSV експорт помилок індексації: У DocFetcher Pro ви можете експортувати таблицю файлів, які програма не змогла прочитати під час індексації, у CSV файл. Це можна зробити через контекстне меню таблиці помилок, як показано на наступному скріншоті. Ця функція наразі недоступна в DocFetcher Server. Server Not available in DocFetcher Server
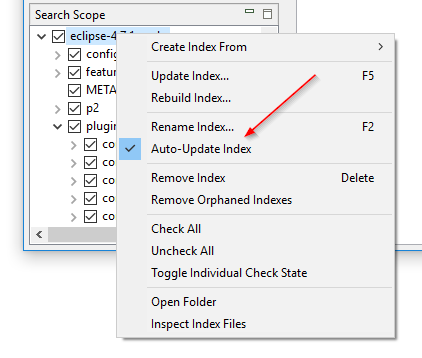
Увімкнення та вимкнення відстеження тек без перестворення індексу: Налаштування «Переглянути теки на зміни файлів» DocFetcher, також відоме як відстеження тек, є налаштуванням для кожного індексу, яке при увімкненні змушує програму автоматично оновлювати індекс при виявленні змін файлів у проіндексованій теці. Проблема полягає в тому, що якщо ви хочете увімкнути чи вимкнути це налаштування для конкретного індексу, ви повинні перестворити весь індекс. У DocFetcher Pro ви можете увімкнути чи вимкнути це налаштування без перестворення індексу через контекстне меню панелі Search Scope. Крім того, налаштування було перейменовано на «Автоматично оновити індекс». Подібна функціональність існує в DocFetcher Server.
Одночасний пошук і перестворення індексу: У DocFetcher, якщо ви вирішите перестворити індекс, цей індекс стає недоступним для пошуку під час перестворення. У DocFetcher Pro і DocFetcher Server, з іншого боку, індекс залишається доступним для пошуку під час перестворення. (Точніше, стара копія індексу залишається доступною для пошуку, поки фактичний індекс перестворюється у фоновому режимі.)
Windows: Виправлене обробка UNC шляхів: У DocFetcher обробка UNC шляхів на Windows дуже погано працює і була перероблена з нуля в DocFetcher Pro. Потім переробка була перенесена в DocFetcher Server.
Немодальний діалог індексації: На відміну від діалогу індексації DocFetcher, діалог у DocFetcher Pro є «немодальним», що означає, що він не прикріплений до головного вікна програми і не блокує введення в головне вікно програми, поки він відкритий. Основною перевагою цього є те, що поки працюють процеси індексації, ви можете мінімізувати головне вікно програми, але залишити діалог індексації видимим і розмістити його збоку. Це дозволяє стежити за процесами індексації під час роботи в інших додатках. Ця функція не застосовується до DocFetcher Server. Server Not available in DocFetcher Server
Відтворення звуку після індексації: За замовчуванням DocFetcher Pro відтворює звук «завершення» після індексації. Це можна вимкнути в налаштуваннях. Ця функція наразі недоступна в DocFetcher Server. Server Not available in DocFetcher Server
Індексація японського тексту: DocFetcher має так звану опцію «сегментації слів» для отримання корисних результатів пошуку при індексації китайського тексту. DocFetcher Pro має додаткову опцію сегментації слів для обробки японського тексту. Сегментація слів китайською та японською мовами наразі недоступна в DocFetcher Server. Server Not available in DocFetcher Server