패턴 표 정비
DocFetcher Pro의 인덱싱 대화상자에 있는 패턴 표와 DocFetcher Server의 인덱싱 창에 있는 패턴 표는 다음과 같은 점에서 DocFetcher의 패턴 표와 다릅니다:
- 정규식 외에도, 덜 강력하지만 훨씬 간단한 와일드카드 *와 ?를 사용하여 일치 규칙을 작성할 수 있습니다. 와일드카드 *는 0개 이상의문자를 나타내는 자리 표시자이고, 와일드카드 ?는 정확히 하나의문자를 나타내는 자리 표시자입니다.
- “제외” 작업 외에 새로운 “포함” 작업이 추가되었습니다.
- “Detect mime type” 작업이 사라졌습니다. 파일 확장자가 없는 파일을 텍스트 파일로 인덱싱하려면 패턴 표 아래에 있는 동일한 설명의 체크박스를 사용하십시오.
- 일치는 대소문자를 구분하거나 구분하지 않을 수 있습니다. 반면 DocFetcher에서는 일치가 항상 대소문자를 구분합니다.
- 일치는 일반 파일뿐만 아니라 폴더 및 아카이브 파일에 대해서도 수행할 수 있습니다.
- Windows에서 규칙이 파일 경로와 일치할 때, 후자는 경로 구분자로 /문자가 아닌 \문자를 사용합니다. 예: C:\경로\대상\파일.docx대신 C:/경로/대상/파일.docx.
결과적으로 DocFetcher Pro의 패턴 표는 다음과 같습니다:
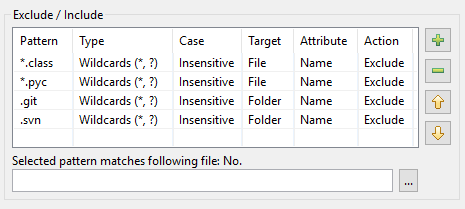
DocFetcher Server의 패턴 표도 동일하게 보이지만, 표 아래의 “선택한 패턴이 다음 파일에 일치합니다” 테스트 위젯은 현재 사용할 수 없습니다. Server Not available in DocFetcher Server
DocFetcher, DocFetcher Pro 및 DocFetcher Server의 패턴 표에 대한 자세한 설명을 보려면 여기를 클릭하십시오.
DocFetcher Pro와 DocFetcher Server에서 패턴 표가 어떻게 정비되었는지에 대한 설명입니다. 처음부터 시작하겠습니다: DocFetcher의 인덱싱 대화상자에는 인덱싱 중에 특정 패턴과 일치하는 파일에 대해 특정 작업을 수행하기 위한 패턴 표가 있습니다:
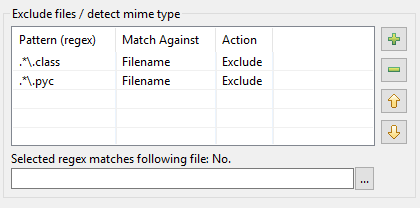
패턴은 소위 정규식이어야 하며, 작업으로는 두 가지가 DocFetcher에서 사용 가능합니다: 일치하는 파일을 인덱싱에서 제외하는 것과 “MIME 유형 감지”, 즉 파일 이름이 아닌 파일 내용을 기반으로 일치하는 파일을 구문 분석하는 올바른 방법을 추측하는 것입니다. 지금까지는 좋습니다. 그러나 실제로는 위 구현에 여러 가지 문제가 있는 것으로 나타났습니다:
- 정규식을 작성하는 방법을 아는 사람은 거의 없습니다.
- 때로는 특정 파일 만인덱싱하고 다른 파일에 불필요하게 인덱싱 시간을 낭비하고 싶지 않을 때가 있습니다. 예를 들어, “txt” 파일만 인덱싱하고 다른 것은 인덱싱하지 않는 것입니다. DocFetcher는 실제로 이 작업을 수행할 수 있지만, 상당히 고급 정규식 기법이 필요합니다.
- 때로는 특정 패턴과 일치하는 모든 파일을 인덱싱에서 제외하고 싶지만, 특정 다른패턴과 일치하는 모든 파일은 제외하고 싶을 때가 있습니다. 예를 들어, 이름이 “보고서_”로 시작하는 PDF 파일을 제외하고 모든 PDF 파일을 인덱싱에서 제외하는 것입니다. 다시 말하지만, DocFetcher에서는 고급 정규식 사용이 필요합니다.
- 일반적으로 MIME 유형 감지는 거의 쓸모가 없습니다. 왜냐하면: (1) 파일 확장자는 거의 항상 정확하므로 대부분의 경우 파일 형식을 파악하는 데 필요한 전부입니다. (2) 파일 확장자가 정확하지 않아 MIME 유형 감지가 필요한 경우, 후자는 그다지 신뢰할 수 없는 것으로 나타났습니다. (3) MIME 유형 감지가 실제로 필요한 드문 경우에 일치 규칙을 작성하는 데 신경 쓰거나 방법을 아는 사람이 없습니다. 그러나 DocFetcher의 맥락에서 MIME 유형 감지는 한 가지 중요한 사용 사례가 있는 것으로 나타났습니다: 프로그램이 README와 같이 파일 확장자가 없는 파일을 일반 텍스트 파일로 처리하도록 하는 것입니다. 하지만 하지만, 이를 해내려면 [^.]*라는 모호한 정규식을 작성해야 합니다.
- 파일에 일부 이진 데이터가 포함된 경우 MIME 유형 감지가 파일을 일반 텍스트로 식별하지 못할 수 있습니다.
- DocFetcher의 휴대용 버전은 지원되는 모든 플랫폼에서 실행되어야 하므로, 파일 경로에 대해 규칙을 일치시킬 때 후자는 Windows에서도 항상 경로 구분자로 /문자가 아닌 \문자를 사용하므로 대부분의 Windows 사용자에게는 매우 직관적이지 않습니다.
요약하자면, DocFetcher의 패턴 표는 엉망진창이었고, DocFetcher Pro와 함께 제공된 재작성은 이 모든 것을 정리할 좋은 기회였습니다:
- 와일드카드가 추가되고 기본값으로 설정되어 이제 평범한 사람들도 일치 규칙을 작성할 수 있습니다.
- “포함” 작업은 특정 종류의 파일 만인덱싱하려는 경우와 일치 규칙에 대한 예외를 정의하려는 경우를 모두 다룹니다. 예외에 대한 예외도 이제 가능합니다.
- 일반적으로 쓸모없는 “Detect mime type” 작업은 사라지고, 주요 사용 사례인 파일 확장자가 없는 파일을 텍스트 파일로 인덱싱하는 것은 패턴 표 아래의 간단한 체크박스로 처리됩니다. 그리고 이 체크박스는 파일에 일부 이진 데이터가 포함된 경우에도 작동합니다.
- Windows 경로 구분자 문제가 해결되었습니다.
- 그리고 몇 가지 다른 사항(대소문자 구분 및 파일/폴더/아카이브에 대한 일치)이 추가되었습니다.
인덱싱 설정 로드 및 저장
참고: 이 기능은 현재 DocFetcher Pro에서만 사용할 수 있으며 DocFetcher Server에서는 사용할 수 없습니다. Server Not available in DocFetcher Server
문제점: DocFetcher에서는 새 인덱스를 만들 때마다 패턴 표의 모든 규칙을 하나씩 입력해야 합니다. 이러한 규칙이 많은 경우 이 작업은 매우 지루해집니다. 규칙을 로드하고 저장할 방법이 없습니다.
DocFetcher Pro에서는 위 문제가 다음과 같이 해결됩니다: DocFetcher Pro의 인덱싱 대화상자 오른쪽 상단에는 눈에 띄지 않는 작은 “문서가 담긴 병” 버튼이 있습니다. 이 버튼을 클릭하면 인덱싱 설정을 로드하고 저장하기 위한 다양한 작업이 포함된 메뉴가 열립니다:
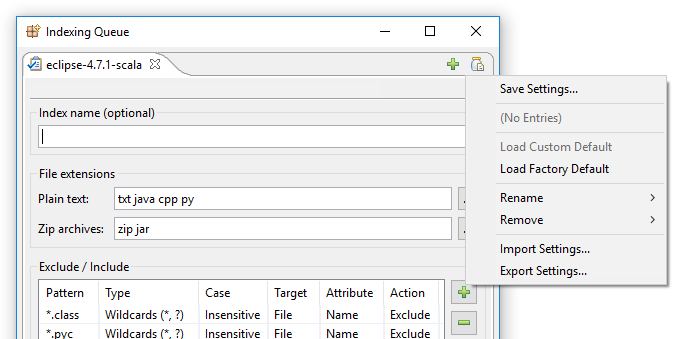
“설정 저장”을 클릭하면 다음 대화상자가 열립니다:
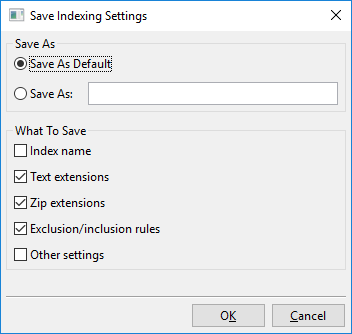
기본적으로 이 대화상스로 할 수 있는 일은 현재 보이는 인덱싱 설정을 “내 새 인덱싱 설정”과 같은 새 이름의 슬롯에 저장하거나, 현재 보이는 인덱싱 설정을 새 기본값으로 저장하는 것입니다.
이 기본값은 “사용자 기본값”라고 하며 새 인덱스를 만들 때 자동으로 로드됩니다. 또한 DocFetcher Pro가 기본적으로 사용하는 “공장 기본값”도 있습니다. 사용자가 만든 명명된 설정, 즉 “사용자 기본값” 및 “공장 기본값”는 모두 위에서 표시된 메뉴를 통해 로드할 수 있습니다.
마지막으로, 이 메뉴를 사용하면 모든 인덱싱 설정을 가져오고 내보낼 수 있으므로 새 환경에서 DocFetcher Pro를 설정할 때 재사용할 수 있습니다.
기타 주목할 만한 개선 사항
FB2 지원: DocFetcher Pro와 DocFetcher Server는 전자책 형식인 FB2를 지원합니다. 파일 확장자가 fb2.zip 또는 fbz인 Zip 압축 FB2 파일은 “기본적으로” 지원됩니다. 즉, DocFetcher Pro와 DocFetcher Server는 각 파일을 zip 아카이브에 싸인 파일이 아닌 단일 파일로 봅니다.
실험적인 Mobipocket 지원: DocFetcher Pro와 DocFetcher Server는 파일 확장자가 “mobi”인 전자책 형식 Mobipocket을 지원합니다. 그러나 DocFetcher Pro와 DocFetcher Server가 전반적으로 mobi 파일에서 텍스트를 추출하는 데 꽤 견고한 작업을 수행하지만, 현재 파일 끝에 있는 작은 텍스트 부분을 추출하지 못하거나 경우에 따라 완전히 실패합니다. 따라서 Mobipocket 지원은 현재 실험적으로 표시됩니다.
현재 v0.4 형식에 대한 7z 아카이브 지원: DocFetcher는 7z 아카이브 형식의 v0.3까지 7z 아카이브를 읽을 수 있습니다. DocFetcher Pro와 DocFetcher Server는 현재 v0.4 형식의 7z 아카이브도 읽을 수 있습니다. 이 v0.4 형식은 2014-11-23에 출시된 7-Zip 9.34와 함께 도입되었습니다.
확장된 tar 아카이브 지원: DocFetcher는 다음 tar 아카이브 확장을 지원합니다: tar, tar.gz, tgz, tar.bz2, tb2, tbz. DocFetcher Pro와 DocFetcher Server는 추가로 다음 tar 아카이브 확장을 지원합니다: tbz2, tar.lzma, tlz, tar.xz, txz, tar.z, tz
폴더 및 아카이브 이름 인덱싱: DocFetcher와 달리 DocFetcher Pro와 DocFetcher Server는 일반 파일뿐만 아니라 폴더 및 아카이브 파일, 더 정확하게는 폴더 및 아카이브 파일의 이름을 인덱싱합니다. 따라서 폴더 및 아카이브 파일은 DocFetcher Pro와 DocFetcher Server의 검색 결과에 표시됩니다. 또한 주 응용 프로그램 창 왼쪽에 있는 “컨테이너 형식” 창을 사용하여 검색 결과에서 폴더 및/또는 아카이브를 제외할 수 있습니다.
MacOS: 자동 인덱스 업데이트를 위한 데몬: DocFetcher와 DocFetcher Pro는 자동인덱스 업데이트가 가능합니다. 즉, 인덱스 업데이트를 수동으로 시작할 필요 없이 파일 변경이 감지되는 즉시 프로그램에서 인덱스 업데이트가 시작됩니다. 그러나 이 기능은 두 프로그램이 실제로 실행 중일 때만 사용할 수 있습니다. 실행 중이 아닐 때는 별도의 데몬 프로세스가 그 공백을 메워야 합니다. DocFetcher에서 데몬은 Windows와 Linux에서만 사용할 수 있지만, DocFetcher Pro에서는 macOS에서도 사용할 수 있습니다. DocFetcher Server의 경우 서버가 지속적으로 실행되도록 설계되었으므로 데몬이 필요하지 않습니다. Server Not available in DocFetcher Server
더 스마트한 파일 이름 인덱싱: DocFetcher Pro와 DocFetcher Server의 파일 이름 인덱싱은 DocFetcher보다 더 스마트합니다. 예를 들어, DocFetcher가 \ 이_파일_찾기.pdf라는 이름의 파일을 만나면 “이_파일_찾기”를 세 개의 개별 단어가 아닌 하나의 단어로 봅니다. 따라서 DocFetcher는 DocFetcher의 검색 필드에 “이_파일_찾기”를 문자 그대로 입력해야만 이 파일을 찾습니다. 반면에 DocFetcher Pro와 DocFetcher Server는 “이_파일_찾기” 또는 세 개의 개별 단어 중 하나를 입력하면 파일을 찾습니다. 일반적으로 DocFetcher Pro와 DocFetcher Server가 하는 일은 밑줄과 같은 문자를 잠재적인 단어 구분 기호로 인식하는 것입니다.

오류 발생 시 파일 이름 인덱싱: DocFetcher Pro와 DocFetcher Server가 일부 오류나 암호 보호로 인해 파일 내용을 읽지 못하는 경우에도 파일 이름은 계속 인덱싱됩니다. 반면에 DocFetcher에서는 파일이 완전히 건너뛰어집니다.
깊게 중첩된 폴더 구조에서 오류 없음: C:\폴더1\폴더2\...\폴더99\폴더100과 같이 깊게 중첩된 폴더 구조를 인덱싱하려고 할 때 DocFetcher는 “폴더 계층이 너무 깊습니다” 오류와 함께 실패하기 쉽습니다. 프로그래머 용어로는 이를 “스택 오버플로”라고 합니다. 반면에 DocFetcher Pro와 DocFetcher Server는 이러한 종류의 오류에 완전히 면역입니다.
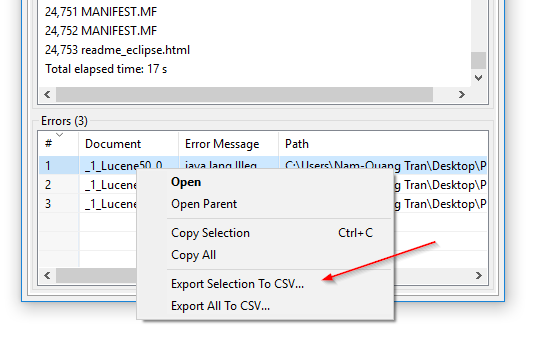
인덱싱 오류의 CSV 내보내기: DocFetcher Pro에서는 프로그램이 인덱싱 중에 읽지 못한 파일 표를 CSV 파일로 내보낼 수 있습니다. 이 작업은 다음 스크린샷과 같이 오류 표의 컨텍스트 메뉴를 통해 수행할 수 있습니다. 이 기능은 현재 DocFetcher Server에서 사용할 수 없습니다. Server Not available in DocFetcher Server
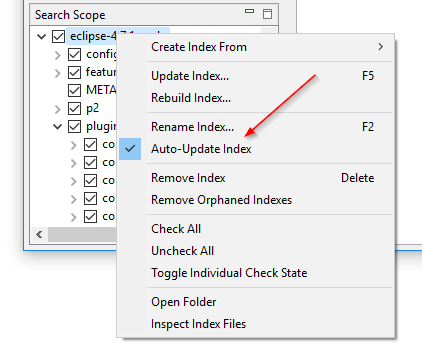
인덱스를 재구성하지 않고 폴더 감시 켜고 끄기: DocFetcher의 “Watch folders for file changes” 설정(폴더 감시라고도 함)은 켜면 프로그램이 인덱싱된 폴더에서 파일 변경을 감지할 때마다 인덱스를 자동으로 업데이트하도록 하는 인덱스별 설정입니다. 문제는 특정 인덱스에서 이 설정을 켜거나 끄려면 전체 인덱스를 재구성해야 한다는 것입니다. DocFetcher Pro에서는 검색 범위 창의 컨텍스트 메뉴를 통해 인덱스를 재구성하지 않고 이 설정을 켜고 끌 수 있습니다. 또한 이 설정의 이름이 “인덱스 자동 업데이트”로 변경되었습니다. DocFetcher Server에도 유사한 기능이 있습니다.
동시 검색 및 인덱스 재구성: DocFetcher에서는 인덱스를 재구성하기로 선택하면 재구성하는 동안 해당 인덱스를 검색할 수 없게 됩니다. 반면에 DocFetcher Pro와 DocFetcher Server에서는 재구성하는 동안 인덱스를 계속 검색할 수 있습니다. (더 정확하게는, 실제 인덱스가 백그라운드에서 재구성되는 동안 이전 버전의 인덱스를 계속 검색할 수 있습니다.)
Windows: UNC 경로 처리 수정: DocFetcher에서 Windows의 UNC 경로 처리는 심하게 손상되어 DocFetcher Pro에서 처음부터 다시 설계되었습니다. 이 재설계는 DocFetcher Server로 이어졌습니다.
비모달 인덱싱 대화상자: DocFetcher의 인덱싱 대화상자와 달리 DocFetcher Pro의 대화상자는 “비모달”입니다. 즉, 주 프로그램 창에 연결되어 있지 않으며 열려 있는 동안 주 프로그램 창으로의 입력을 차단하지 않습니다. 이것의 주된 이점은 인덱싱 프로세스가 실행되는 동안 주 프로그램 창을 최소화할 수 있지만 인덱싱 대화상자는 계속 표시하고 옆에 주차해 둘 수 있다는 것입니다. 이를 통해 다른 응용 프로그램에서 작업하는 동안 인덱싱 프로세스를 주시할 수 있습니다. 이 기능은 DocFetcher Server에는 적용되지 않습니다. Server Not available in DocFetcher Server
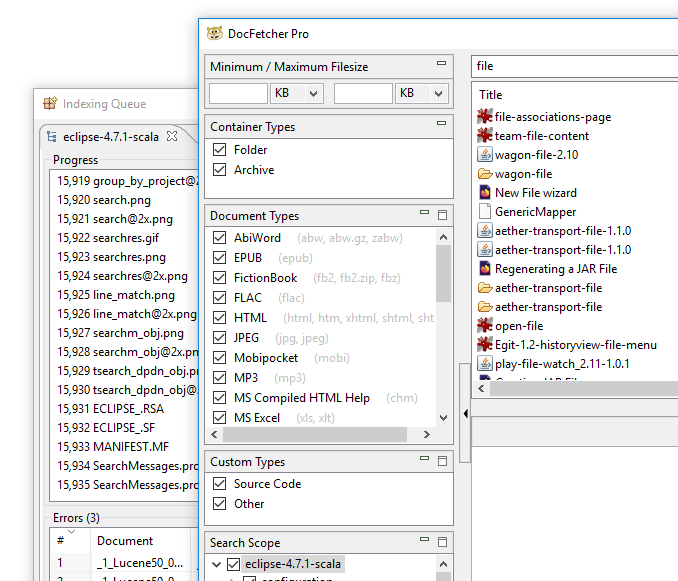
인덱싱 후 소리 재생: 기본적으로 DocFetcher Pro는 인덱싱 후 “완료” 소리를 재생합니다. 이 기능은 환경 설정에서 끌 수 있습니다. 이 기능은 현재 DocFetcher Server에서 사용할 수 없습니다. Server Not available in DocFetcher Server
일본어 텍스트 인덱싱: DocFetcher에는 중국어 텍스트를 인덱싱할 때 유용한 검색 결과를 얻기 위한 소위 “단어 분할” 옵션이 있습니다. DocFetcher Pro에는 일본어 텍스트를 처리하기 위한 추가 단어 분할 옵션이 있습니다. 중국어 및 일본어 단어 분할은 현재 DocFetcher Server에서 사용할 수 없습니다. Server Not available in DocFetcher Server