Rielaborazione della tabella dei modelli
La tabella dei modelli nella finestra di indicizzazione di DocFetcher Pro e la tabella dei modelli nel pannello di indicizzazione di DocFetcher Server differiscono da quella in DocFetcher nei seguenti modi:
- Oltre alle espressioni regolari, puoi utilizzare i caratteri jolly * e ?, meno potenti ma anche molto più semplici, per scrivere regole di corrispondenza. Il carattere jolly * è un segnaposto per zero o più caratteri, mentre il carattere jolly ? è un segnaposto per esattamente un carattere.
- Una nuova azione «Includi» oltre all’azione «Escludi».
- L’azione «Riconoscimento tipo di MIME» è stata rimossa. Se vuoi indicizzare file senza estensione come file di testo, usa la casella di controllo con la stessa descrizione sotto la tabella dei modelli.
- La corrispondenza può essere sensibile o insensibile alle maiuscole. In DocFetcher invece, la corrispondenza è sempre sensibile alle maiuscole.
- La corrispondenza può essere eseguita non solo sui file normali, ma anche su cartelle e file di archivio.
- Su Windows, quando le regole vengono confrontate con i percorsi dei file, questi utilizzeranno il carattere \ come separatore di percorso, non il carattere /. Esempio: C:\Percorso\A\File.docx, invece di C:/Percorso/A/File.docx.
Di conseguenza, ecco come appare la tabella dei modelli in DocFetcher Pro:
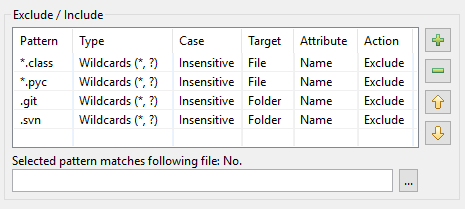
La tabella dei modelli in DocFetcher Server ha lo stesso aspetto, ma il widget di test «Il modello selezionato corrisponde al seguente file» sotto la tabella non è attualmente disponibile. Server Not available in DocFetcher Server
Clicca qui per una discussione dettagliata della tabella dei modelli in DocFetcher, DocFetcher Pro e DocFetcher Server.
Ecco come è nata la rielaborazione della tabella dei modelli in DocFetcher Pro e DocFetcher Server. Iniziamo dall’inizio: Nella finestra di indicizzazione di DocFetcher, c’è una tabella dei modelli per eseguire certe azioni sui file che corrispondono a determinati modelli durante l’indicizzazione:
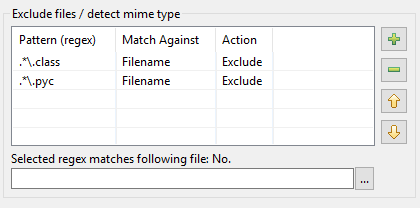
I modelli devono essere le cosiddette espressioni regolari, e per quanto riguarda le azioni, due sono disponibili in DocFetcher: Escludere il file corrispondente dall’indicizzazione, e «riconoscimento del tipo MIME», cioè, tentare di indovinare il modo corretto di analizzare il file corrispondente basandosi sul contenuto del file piuttosto che sul suo nome. Fin qui tutto bene. Tuttavia, in pratica si scopre che l’implementazione di cui sopra ha una serie di problemi:
- Pochissime persone sanno come scrivere espressioni regolari.
- A volte si vogliono indicizzare solo certi file, e non sprecare inutilmente tempo di indicizzazione su tutto il resto. Ad esempio, indicizzare solo file «txt» e nient’altro. DocFetcher può effettivamente farlo, ma richiede alcuni trucchi abbastanza avanzati con le espressioni regolari.
- A volte si vogliono escludere dall’indicizzazione tutti i file che corrispondono a un certo modello, tranne tutti i file che corrispondono a un certo altro modello. Ad esempio, escludere dall’indicizzazione tutti i file PDF, tranne i file PDF i cui nomi iniziano con «rapporto_». Anche in questo caso, in DocFetcher questo richiede un uso avanzato di espressioni regolari.
- In generale, il riconoscimento del tipo MIME è piuttosto inutile perché: (1) L’estensione del file è quasi sempre corretta e quindi nella maggior parte dei casi è tutto ciò che serve per capire il formato del file. (2) Quando l’estensione del file non è corretta e il riconoscimento del tipo MIME è necessario, quest’ultimo si rivela comunque non particolarmente affidabile. (3) Nessuno si preoccupa e/o sa come scrivere regole di corrispondenza per quei rari casi in cui il riconoscimento del tipo MIME sarebbe effettivamente necessario. Tuttavia, nel contesto di DocFetcher si scopre che il riconoscimento del tipo MIME ha effettivamente un importante caso d’uso: Far sì che il programma tratti i file senza estensione come file di testo semplice, ad esempio, file chiamati README. Tuttavia tuttavia, per riuscirci, bisogna scrivere questa oscura espressione regolare: [^.]*
- Il riconoscimento del tipo MIME può fallire nell’identificare un file come testo semplice se il file contiene alcuni dati binari.
- A causa del fatto che la versione portatile di DocFetcher deve funzionare su tutte le piattaforme supportate, quando le regole di corrispondenza vengono applicate ai percorsi dei file, questi usano sempre il carattere / come separatore di percorso, anche su Windows, il che è abbastanza controintuitivo per la maggior parte degli utenti Windows.
In breve, la tabella dei modelli di DocFetcher è un gran casino, e la riscrittura che è arrivata con DocFetcher Pro è stata una buona opportunità per sistemare tutto:
- I caratteri jolly sono stati aggiunti e impostati come predefiniti così che ora anche i comuni mortali possono scrivere regole di corrispondenza.
- L’azione «Includi» copre sia il caso in cui si vogliono indicizzare solo un tipo specifico di file, sia il caso in cui si vogliono definire eccezioni alle regole di corrispondenza. Ora sono possibili anche eccezioni-alle-eccezioni.
- L’azione «Riconoscimento tipo di MIME» generalmente inutile è scomparsa, e il suo caso d’uso principale, indicizzare file senza estensione come file di testo, è coperto da una semplice casella di controllo sotto la tabella dei modelli. E questa casella di controllo funziona anche se il file contiene alcuni dati binari.
- Il problema del separatore di percorso di Windows è risolto.
- E alcune altre cose (sensibilità alle maiuscole e corrispondenza contro file/cartelle/archivi) sono state aggiunte per buona misura.
Caricamento e salvataggio delle impostazioni di indicizzazione
Nota: Questa funzionalità è attualmente disponibile solo in DocFetcher Pro, non in DocFetcher Server. Server Not available in DocFetcher Server
Il problema: In DocFetcher, ogni volta che crei un nuovo indice, devi inserire tutte le regole nella tabella dei modelli una per una. Questo diventa piuttosto noioso se hai molte di queste regole. Non c’è proprio modo di caricarle e salvarle.
In DocFetcher Pro, il problema di cui sopra è risolto come segue: Nell’angolo in alto a destra della finestra di indicizzazione di DocFetcher Pro, si trova un piccolo pulsante poco appariscente «barattolo con documento». Cliccando questo pulsante si apre un menu contenente varie azioni per caricare e salvare le impostazioni di indicizzazione:
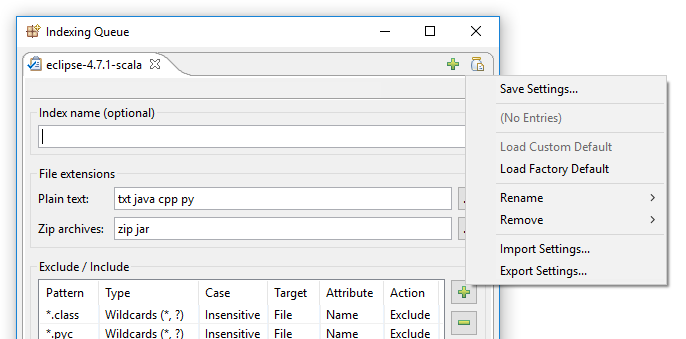
Cliccando su «Salva impostazioni» si apre questa finestra di dialogo:
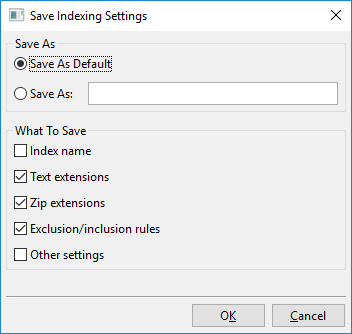
In sostanza, quello che puoi fare con questa finestra di dialogo è salvare le impostazioni di indicizzazione attualmente visibili in un nuovo slot denominato, ad esempio, «Le mie nuove impostazioni di indicizzazione», oppure salvare le impostazioni di indicizzazione attualmente visibili come nuovo predefinito.
Questo predefinito si chiama «Predefinito personalizzato» e verrà caricato automaticamente quando si creano nuovi indici. C’è anche un «Predefinito di fabbrica», che è il predefinito che DocFetcher Pro usa di base. Le impostazioni denominate che hai creato, cioè «Predefinito personalizzato» e «Predefinito di fabbrica», possono essere tutte caricate tramite il menu mostrato sopra.
Per completare il quadro, il menu consente anche di importare ed esportare tutte le tue impostazioni di indicizzazione così da poterle riutilizzare quando configuri DocFetcher Pro in un nuovo ambiente.
Altri miglioramenti degni di nota
Supporto FB2: DocFetcher Pro e DocFetcher Server hanno supporto per il formato e-book FB2. I file FB2 compressi con zip, con estensione fb2.zip o fbz, sono supportati «nativamente», cioè, DocFetcher Pro e DocFetcher Server vedono ciascun file di questo tipo come un singolo file piuttosto che come un file avvolto in un archivio zip.
Supporto sperimentale Mobipocket: DocFetcher Pro e DocFetcher Server hanno supporto per il formato e-book Mobipocket, con estensione «mobi». Tuttavia, nota che mentre DocFetcher Pro e DocFetcher Server nel complesso fanno un lavoro abbastanza solido nell’estrarre testo dai file mobi, attualmente o falliscono nell’estrarre una piccola porzione di testo alla fine del file, o in alcuni casi falliscono completamente. Quindi, il supporto Mobipocket è per ora contrassegnato come sperimentale.
Supporto archivi 7z per l’attuale formato v0.4: DocFetcher può leggere archivi 7z fino alla v0.3 del formato archivio 7z. DocFetcher Pro e DocFetcher Server possono anche leggere archivi 7z nell’attuale formato v0.4. Questo formato v0.4 è stato introdotto con 7-Zip 9.34, rilasciato il 23-11-2014.
Supporto espanso per archivi tar: DocFetcher supporta le seguenti estensioni di archivi tar: tar, tar.gz, tgz, tar.bz2, tb2, tbz. DocFetcher Pro e DocFetcher Server supportano inoltre le seguenti estensioni di archivi tar: tbz2, tar.lzma, tlz, tar.xz, txz, tar.z, tz
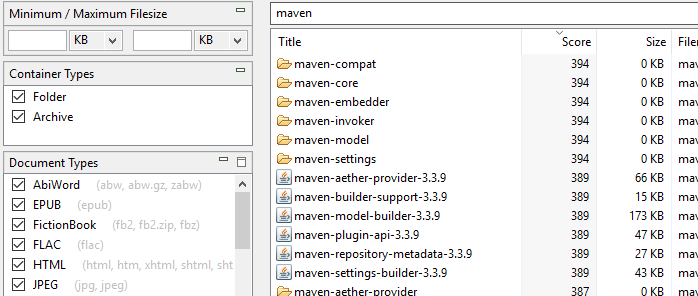
Indicizzazione dei nomi di cartelle e archivi: A differenza di DocFetcher, DocFetcher Pro e DocFetcher Server indicizzano non solo i file normali, ma anche le cartelle e i file di archivio — o più precisamente, i nomi delle cartelle e dei file di archivio. Quindi, cartelle e file di archivio appariranno nei risultati di ricerca di DocFetcher Pro e DocFetcher Server. C’è anche un pannello Tipi di contenitore sul lato sinistro della finestra principale dell’applicazione per escludere cartelle e/o archivi dai risultati di ricerca.
MacOS: Daemon per l’aggiornamento automatico dell’indice: DocFetcher e DocFetcher Pro sono capaci di aggiornamento automatico dell’indice, cioè, invece di dover avviare gli aggiornamenti dell’indice manualmente, gli aggiornamenti dell’indice vengono avviati dal programma non appena vengono rilevate modifiche ai file. Tuttavia, questa funzionalità è disponibile solo mentre i due programmi sono effettivamente in esecuzione. Quando non sono in esecuzione, è necessario un processo daemon separato per colmare il vuoto. In DocFetcher, il daemon è disponibile solo su Windows e Linux, mentre in DocFetcher Pro, è disponibile anche su macOS. Per quanto riguarda DocFetcher Server, non è necessario alcun daemon poiché il server è progettato per funzionare continuamente. Server Not available in DocFetcher Server
Indicizzazione più intelligente dei nomi di file: L’indicizzazione dei nomi di file in DocFetcher Pro e DocFetcher Server è più intelligente che in DocFetcher. Ad esempio, se DocFetcher incontra un file chiamato trova_questo_file.pdf, vede «trova_questo_file» come una singola parola, non come tre parole separate unite insieme. Quindi, DocFetcher troverà questo file solo se digiti letteralmente «trova_questo_file» nel campo di ricerca di DocFetcher. DocFetcher Pro e DocFetcher Server d’altra parte troveranno il file se digiti «trova_questo_file» o una qualsiasi delle tre parole individuali. In generale, quello che fanno DocFetcher Pro e DocFetcher Server è riconoscere caratteri come il trattino basso come potenziali separatori di parole.

Indicizzazione del nome file in caso di errori: Se DocFetcher Pro e DocFetcher Server falliscono nel leggere il contenuto di un file a causa di qualche errore o a causa della protezione con password, il nome del file viene comunque indicizzato. In DocFetcher d’altra parte, il file viene completamente saltato.
Nessun errore con strutture di cartelle profondamente annidate: Quando si cerca di indicizzare strutture di cartelle profondamente annidate, come C:\cartella1\cartella2\...\cartella99\cartella100, DocFetcher è incline a fallire con un errore «Gerarchia di cartelle troppo profonda». Nel gergo dei programmatori, questo si chiama «stack overflow». DocFetcher Pro e DocFetcher Server d’altra parte sono completamente immuni a questo tipo di errore.
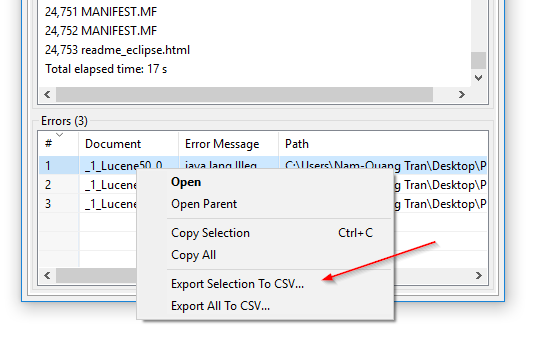
Esportazione CSV degli errori di indicizzazione: In DocFetcher Pro, puoi esportare la tabella dei file che il programma ha fallito nel leggere durante l’indicizzazione in un file CSV. Questo può essere fatto tramite il menu contestuale della tabella degli errori, come mostrato nella seguente schermata. Questa funzionalità non è attualmente disponibile in DocFetcher Server. Server Not available in DocFetcher Server
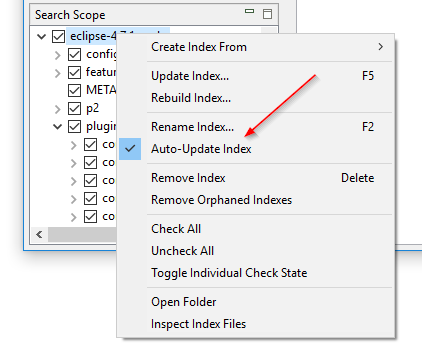
Attivare e disattivare la sorveglianza delle cartelle senza ricostruire l’indice: L’impostazione «Sorveglianza sulle cartelle per eventuali modifiche ai file» di DocFetcher, nota anche come sorveglianza delle cartelle, è un’impostazione per indice che quando attivata fa sì che il programma aggiorni automaticamente l’indice ogni volta che rileva modifiche ai file nella cartella indicizzata. Il problema è che se vuoi attivare o disattivare questa impostazione su un particolare indice, devi ricostruire l’intero indice. In DocFetcher Pro, puoi attivare e disattivare questa impostazione senza ricostruire l’indice, tramite il menu contestuale del pannello Ambito di ricerca. Inoltre, l’impostazione è stata rinominata in «Aggiorna indice automaticamente». Funzionalità simili esistono in DocFetcher Server.
Ricerca simultanea e ricostruzione dell’indice: In DocFetcher, se scegli di ricostruire un indice, quell’indice diventa non disponibile per la ricerca mentre la ricostruzione è in corso. In DocFetcher Pro e DocFetcher Server d’altra parte, l’indice rimane ricercabile durante la ricostruzione. (Più precisamente, una vecchia copia dell’indice rimane ricercabile mentre l’indice vero e proprio viene ricostruito in background.)
Windows: Gestione corretta dei percorsi UNC: In DocFetcher, la gestione dei percorsi UNC su Windows è gravemente danneggiata ed è stata riprogettata da zero in DocFetcher Pro. Il riprogetto è stato poi trasferito a DocFetcher Server.
Finestra di dialogo di indicizzazione non modale: In contrasto con la finestra di dialogo di indicizzazione di DocFetcher, quella in DocFetcher Pro è «non modale», il che significa che non è attaccata alla finestra principale del programma e non blocca l’input alla finestra principale del programma mentre è aperta. Il principale beneficio di questo è che mentre i processi di indicizzazione sono in esecuzione, puoi minimizzare la finestra principale del programma, ma mantenere la finestra di dialogo di indicizzazione visibile e parcheggiata di lato. Questo ti permette di tenere d’occhio i processi di indicizzazione mentre fai lavoro in altre applicazioni. Questa funzionalità non è applicabile a DocFetcher Server. Server Not available in DocFetcher Server
Riproduzione di un suono dopo l’indicizzazione: Per impostazione predefinita, DocFetcher Pro riproduce un suono «finito» dopo l’indicizzazione. Questo può essere disattivato nelle preferenze. Questa funzionalità non è attualmente disponibile in DocFetcher Server. Server Not available in DocFetcher Server
Indicizzazione del testo giapponese: DocFetcher ha una cosiddetta opzione «segmentazione delle parole» per ottenere risultati di ricerca utilizzabili quando si indicizza testo cinese. DocFetcher Pro ha un’opzione aggiuntiva di segmentazione delle parole per gestire il testo giapponese. Sia la segmentazione delle parole cinese che quella giapponese non sono attualmente disponibili in DocFetcher Server. Server Not available in DocFetcher Server