Mintatábla átdolgozása
A DocFetcher Pro indexelő ablakának mintatáblája és a DocFetcher Server indexelési területének mintatáblája az alábbi módokon tér el a DocFetcher mintatáblájától:
- A reguláris kifejezések mellett használhatja a kevésbé hatékony, de sokkal egyszerűbb * és ? helyettesítő karaktereket is illeszkedési szabályok írásához. A * helyettesítő karakter nulla vagy több karakter helyettesítője, míg a ? helyettesítő karakter pontosan egy karakter helyettesítője.
- Új “Belefoglal” művelet a “Kizár” művelet mellett.
- A “Mime típus felismerése” művelet eltűnt. Ha fájlkiterjesztés nélküli fájlokat szeretne szövegfájlként indexelni, használja a mintatábla alatt található, ugyanilyen leírású jelölőnégyzetet.
- Az illeszkedés lehet kis- és nagybetű-érzékeny vagy nem érzékeny. A DocFetcherben ezzel szemben az illeszkedés mindig kis- és nagybetű-érzékeny.
- Az illeszkedés nemcsak normál fájlokra, hanem mappákra és archív fájlokra is elvégezhető.
- Windows rendszeren, amikor szabályokat illesztenek fájlútvonalakra, az utóbbiak a \ karaktert használják elválasztóként, nem a / karaktert. Példa: C:\Útvonal\Célhoz\Fájl.docx, a C:/Útvonal/Célhoz/Fájl.docx helyett.
Ennek eredményeként így néz ki a DocFetcher Pro mintatáblája:
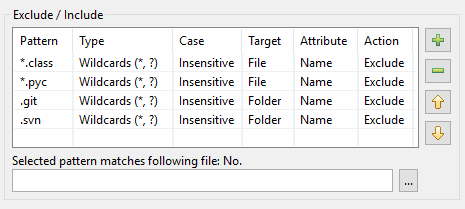
A DocFetcher Server mintatáblája ugyanúgy néz ki, de a tábla alatti “A kiválasztott mintázat illeszkedik a következő fájlra” tesztelő widget jelenleg nem elérhető. Server Not available in DocFetcher Server
Kattintson ide a DocFetcher, DocFetcher Pro és DocFetcher Server mintatáblájának részletes tárgyalásához.
Itt van, hogyan jött létre a DocFetcher Pro és DocFetcher Server mintatáblájának átdolgozása. Kezdjük az elejétől: A DocFetcher indexelő ablakában van egy mintatábla, amely bizonyos műveleteket hajt végre az indexelés során bizonyos mintázatokra illeszkedő fájlokon:
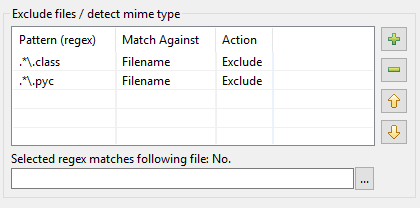
A mintázatoknak úgynevezett reguláris kifejezéseknek kell lenniük, és a műveletek tekintetében kettő érhető el a DocFetcherben: Az illeszkedő fájl kizárása az indexelésből, és a “mime-típus felismerés”, azaz megpróbálni kitalálni a helyes módját az illeszkedő fájl feldolgozásának a fájl tartalma alapján, nem a fájlneve alapján. Eddig rendben. A gyakorlatban azonban kiderül, hogy a fenti megvalósításnak számos problémája van:
- Nagyon kevés ember tudja, hogyan kell reguláris kifejezéseket írni.
- Néha az ember csak bizonyos fájlokat szeretne indexelni, és nem akar feleslegesen indexelési időt pazarolni minden másra. Például csak “txt” fájlokat indexelni és semmi mást. A DocFetcher valójában képes erre, de ez meglehetősen fejlett reguláris kifejezés-trükköket igényel.
- Néha az ember ki akar zárni az indexelésből minden fájlt, amely egy bizonyos mintázatra illeszkedik, kivéve az összes fájlt, amely egy bizonyos másik mintázatra illeszkedik. Például kizárni az indexelésből az összes PDF fájlt, kivéve azokat a PDF fájlokat, amelyek neve “jelentés_”-sel kezdődik. Ismét, a DocFetcherben ez a reguláris kifejezések fejlett használatát igényli.
- Általában a mime-típus felismerés meglehetősen haszontalan, mert: (1) A fájlkiterjesztés szinte mindig helyes, ezért a legtöbb esetben ez minden, ami szükséges a fájlformátum meghatározásához. (2) Amikor a fájlkiterjesztés nem helyes és mime-típus felismerésre van szükség, az utóbbi nem különösebben megbízható. (3) Senki sem veszi a fáradságot és/vagy tudja, hogyan kell illeszkedési szabályokat írni azokra a ritka esetekre, ahol a mime-típus felismerés valójában szükséges lenne. Azonban a DocFetcher kontextusában kiderül, hogy a mime-típus felismerésnek van egy fontos felhasználási esete: A program fájlkiterjesztés nélküli fájlokat egyszerű szövegfájlként kezeljen, például README nevű fájlokat. Azonban azonban, ennek eléréséhez ezt a homályos reguláris kifejezést kell írni: [^.]*
- A mime-típus felismerés nem biztos, hogy egyszerű szövegként azonosít egy fájlt, ha a fájl tartalmaz némi bináris adatot.
- Annak köszönhetően, hogy a DocFetcher hordozható verziójának minden támogatott platformon futnia kell, amikor szabályokat illesztenek fájlútvonalakra, az utóbbiak mindig a / karaktert használják elválasztóként, még Windows rendszeren is, ami meglehetősen ellentmond az intuíciónak a legtöbb Windows felhasználó számára.
Hosszú történet röviden: a DocFetcher mintatáblája egy nagy zűrzavar, és a DocFetcher Pro-val együtt jött átírás jó lehetőség volt az egész rendbetételére:
- Helyettesítő karakterek kerültek hozzáadásra és ezek vannak alapértelmezettként beállítva, hogy most már a közönséges halandók is tudjanak illeszkedési szabályokat írni.
- A “Belefoglal” művelet lefedi mind azt az esetet, amikor az ember csak egy bizonyos fájltípust szeretne indexelni, mind azt az esetet, amikor az ember kivételeket szeretne definiálni az illeszkedési szabályokhoz. Még kivételek-kivételei is lehetségesek.
- Az általában haszontalan “Mime típus felismerése” művelet eltűnt, és fő felhasználási esete, a fájlkiterjesztés nélküli fájlok szövegfájlként való indexelése, egy egyszerű jelölőnégyzet fedez le a mintatábla alatt. És ez a jelölőnégyzet még akkor is működik, ha a fájl tartalmaz némi bináris adatot.
- A Windows útvonal-elválasztó probléma megoldva.
- És néhány más dolog (kis- és nagybetű-érzékenység és illeszkedés fájlokra/mappákra/archívumokra) is hozzá lett adva a teljesség kedvéért.
Indexelési beállítások betöltése és mentése
Megjegyzés: Ez a funkció jelenleg csak a DocFetcher Pro-ban elérhető, a DocFetcher Serverben nem. Server Not available in DocFetcher Server
A probléma: A DocFetcherben minden új index létrehozásánál egyenként kell beírni az összes szabályt a mintatáblába. Ez meglehetősen unalmassá válik, ha sok ilyen szabály van. Egyszerűen nincs mód betölteni és menteni őket.
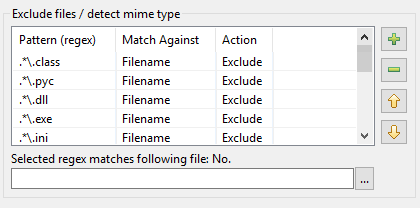
A DocFetcher Pro-ban a fenti probléma így kerül megoldásra: A DocFetcher Pro indexelő ablakának jobb felső sarkában van egy feltunésmentes kis “dokumentumos üveg” gomb. Erre a gombra kattintva megnyit egy menüt, amely különböző műveleteket tartalmaz indexelési beállítások betöltéséhez és mentéséhez:
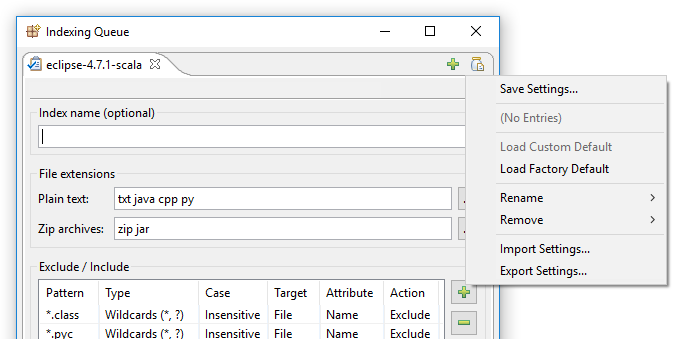
A “Beállítások mentése” gombra kattintva megnyit ez az ablak:
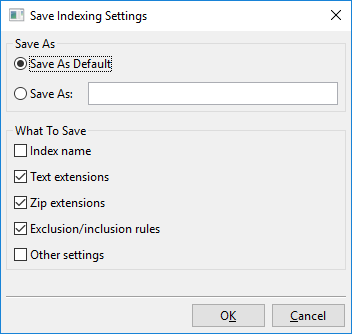
Lényegében ezzel az ablakkal két dolgot tehet: vagy új névvel ellsott helyre menti az aktuálisan látható indexelési beállításokat, például “Új indexelési beállításaim”, vagy az aktuálisan látható indexelési beállításokat új alapértelmezésként menti.
Ez az alapértelmezés “Egyéni alapértelmezett” néven fut és automatikusan betöltődik új indexek létrehozásánál. Van egy “Gyári alapértelmezett” is, amely a DocFetcher Pro alapértelmezett beállítása. A létrehozott névvel ellsott beállítások, azaz a “Egyéni alapértelmezett” és a “Gyári alapértelmezett”, mind betölthetők a fent látható menün keresztül.
A teljesség kedvéért a menü lehetővé teszi az összes indexelési beállítás importálását és exportálását is, hogy újra felhasználhassa őket, amikor új környezetben állítja be a DocFetcher Pro-t.
Más figyelemre méltó fejlesztések
FB2 támogatás: A DocFetcher Pro és DocFetcher Server támogatja az FB2 e-könyv formátumot. A zip-pel tömörített FB2 fájlok, fb2.zip vagy fbz fájlkiterjesztéssel, “natívan” támogatottak, azaz a DocFetcher Pro és DocFetcher Server minden ilyen fájlt egyetlen fájlként lát, nem pedig zip archívumba csomagolt fájlként.
Kísérleti Mobipocket támogatás: A DocFetcher Pro és DocFetcher Server támogatja a Mobipocket e-könyv formátumot “mobi” fájlkiterjesztéssel. Azonban jegyezze meg, hogy bár a DocFetcher Pro és DocFetcher Server általában meglehetősen jól kinyeri a szöveget a mobi fájlokból, jelenleg vagy nem sikerül a fájl végén levő szöveg kis részét kinyerni, vagy néhány esetben teljesen meghiúsul. Ezért a Mobipocket támogatás egyelore kísérleti jelzéssel van ellátva.
7z archív támogatás a jelenlegi v0.4 formátumhoz: A DocFetcher képes 7z archívumok olvasására a 7z archív formátum v0.3 verziójáig. A DocFetcher Pro és DocFetcher Server a jelenlegi v0.4 formátumú 7z archívumokat is képes olvasni. Ez a v0.4 formátum a 7-Zip 9.34-gyel került bevezetésre, amely 2014-11-23-án jelent meg.
Bővített tar archív támogatás: A DocFetcher a következő tar archív kiterjesztéseket támogatja: tar, tar.gz, tgz, tar.bz2, tb2, tbz. A DocFetcher Pro és DocFetcher Server továbbá támogatja a következő tar archív kiterjesztéseket: tbz2, tar.lzma, tlz, tar.xz, txz, tar.z, tz
Mappa- és archív nevek indexelése: A DocFetchertől eltérően a DocFetcher Pro és DocFetcher Server nem csak normál fájlokat indexel, hanem mappákat és archív fájlokat is — vagy pontosabban, a mappák és archív fájlok neveit. Ezért a mappák és archív fájlok meg fognak jelenni a DocFetcher Pro és DocFetcher Server keresési eredményeiben. Van egy Konténertípusok terület is a fő alkalmazás ablak bal oldalán, hogy kizárja a mappákat és/vagy archívumokat a keresési eredményekből.
MacOS: Démon automatikus index frissítéshez: A DocFetcher és DocFetcher Pro képes automatikus index frissítésre, azaz ahelyett, hogy manuálisan kellene elindítani az index frissítéseket, a program elindítja az index frissítéseket, amint fájl változásokat észlel. Azonban ez a funkció csak akkor érhető el, amíg a két program valójában fut. Amikor nem futnak, egy külön démon folyamatra van szükség az űr kitöltéséhez. A DocFetcherben a démon csak Windows és Linux rendszereken érhető el, míg a DocFetcher Pro-ban macOS rendszeren is elérhető. A DocFetcher Server esetében nincs szükség démonra, mivel a szerver folyamatosan futásra van tervezve. Server Not available in DocFetcher Server
Okosabb fájlnév indexelés: A fájlnevek indexelése a DocFetcher Pro és DocFetcher Server-ben okosabb, mint a DocFetcherben. Például, ha a DocFetcher találkozik egy ez_a_fájl_megtalálható.pdf nevű fájllal, akkor az “ez_a_fájl_megtalálható” részt egyetlen szóként látja, nem három külön összefűzött szóként. Így a DocFetcher csak akkor találja meg ezt a fájlt, ha szoról szóra beírja az “ez_a_fájl_megtalálható” szöveget a DocFetcher keresőmezőjébe. A DocFetcher Pro és DocFetcher Server viszont megtalálja a fájlt, ha beírja az “ez_a_fájl_megtalálható” szöveget vagy a három egyedi szó bármelyikét. Általánosan elmondva, amit a DocFetcher Pro és DocFetcher Server tesz, az hogy felismeri a karaktereket, mint például az aláhúzást, mint lehetőséges szóelválasztókat.

Fájlnév indexelés hibák esetén: Ha a DocFetcher Pro és DocFetcher Server nem tudja olvasni egy fájl tartalmát valamilyen hiba miatt vagy jelszóvédelem miatt, a fájlnév még mindig indexelve lesz. A DocFetcherben ezzel szemben a fájl teljesen kimarad.
Nincsenek hibák mélyen ágyazott mappastruktúrákkal: Amikor mélyen ágyazott mappastruktúrákat próbál indexelni, mint például C:\mappa1\mappa2\...\mappa99\mappa100, a DocFetcher hajlamos meghiúsulni egy “Mappastruktúra túl mély” hibával. Programozói zsargonban ezt “stack overflow”-nak hívják. A DocFetcher Pro és DocFetcher Server viszont teljesen immunis az ilyen típusú hibákra.
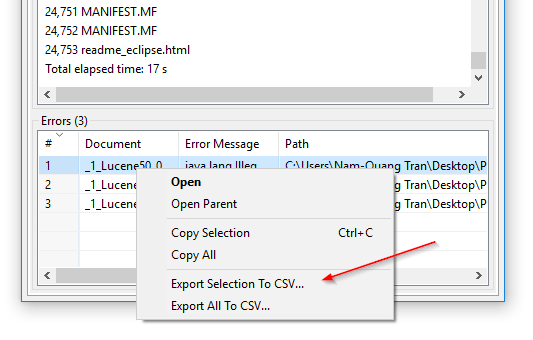
Indexelési hibák CSV exportálása: A DocFetcher Pro-ban exportálhatja azon fájlok tábláját, amelyeket a program nem tudott olvasni az indexelés során, egy CSV fájlba. Ez a hibatábla környezeti menüjén keresztül teheti meg, ahogy a következő képernyőképen látja. Ez a funkció jelenleg nem érhető el a DocFetcher Serverben. Server Not available in DocFetcher Server
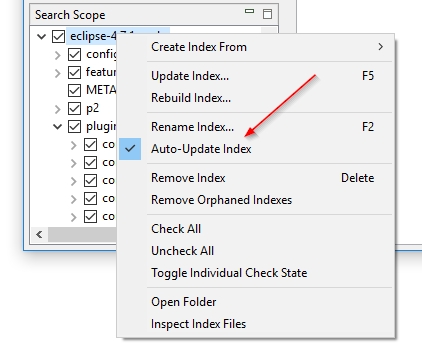
Mappa figyelés be- és kikapcsolása az index újraépítése nélkül: A DocFetcher “Mappák figyelése, állomány változásokért” beállítása, másnéven mappa figyelés, egy index-specifikus beállítás, amely bekapcsolva automatikusan frissíti az indexet, amikor fájlváltozásokat észlel az indexelt mappában. A probléma az, hogy ha ezt a beállítást egy adott indexnél be vagy ki akarja kapcsolni, akkor az egész indexet újra kell építenie. A DocFetcher Pro-ban ezt a beállítást be és ki tudja kapcsolni az index újraépítése nélkül, a Keresési Hatókör terület környezeti menüjén keresztül. A beállítást átnevezették “Index automatikus frissítése”-re is. Hasonló funkció létezik a DocFetcher Serverben is.
Egyidejű keresés és index újraépítés: A DocFetcherben, ha újraépíteni választ egy indexet, az az index elérhetetlenné válik keresésre, amíg az újraépítés folyamatban van. A DocFetcher Pro és DocFetcher Server-ben viszont az index keresésre elérhető marad az újraépítés alatt. (Pontosabban, az index egy régi másolata marad keresésre elérhető, míg a valódi index a háttérben újraépül.)
Windows: UNC útvonalak kezelésének javítása: A DocFetcherben az UNC útvonalak kezelése Windows rendszeren súlyosan hibás volt és a DocFetcher Pro-ban a nulláról tervezték újra. Az újratervezés azután átkerült a DocFetcher Serverbe is.
Nem-modális indexelő ablak: A DocFetcher indexelő ablakával ellentétben a DocFetcher Pro-ban levő “nem-modális”, ami azt jelenti, hogy nincs a fő program ablakhoz kapcsolva és nem blokkolja a fő program ablakba való bemenetet, amíg nyitva van. Ennek fő előnye, hogy amíg indexelési folyamatok futnak, minimalálhatja a fő program ablakot, de az indexelő ablakot láthatóva teheti és oldalt parkoltán hagyhatja. Ez lehetővé teszi, hogy szemügyre vegye az indexelési folyamatokat, míg más alkalmazásokban dolgozik. Ez a funkció a DocFetcher Server-re nem vonatkozik. Server Not available in DocFetcher Server
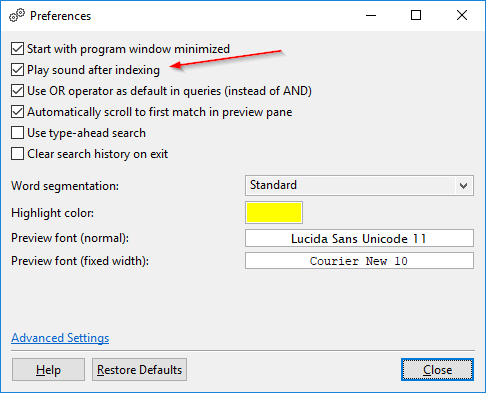
Hang lejátszása indexelés után: Alapértelmezés szerint a DocFetcher Pro egy “befejezve” hangot játszik le az indexelés után. Ez kikapcsolható a beállításokban. Ez a funkció jelenleg nem elérhető a DocFetcher Serverben. Server Not available in DocFetcher Server
Japán szöveg indexelése: A DocFetchernek van egy úgynevezett “Szószegmentálás” opciója, hogy használható keresési eredményeket kapjon kínai szöveg indexelésekor. A DocFetcher Pro-nak van egy további szószegmentálási opciója japán szöveg kezeléséhez. Mind a kínai, mind a japán szószegmentálás jelenleg nem elérhető a DocFetcher Serverben. Server Not available in DocFetcher Server