< tillbaka till överordnad sida
Översyn av mönstertabell
Mönstertabellen i indexeringsdialogen i DocFetcher Pro och mönstertabellen i indexeringsfönstret i DocFetcher Server skiljer sig från den i DocFetcher på följande sätt:
- Utöver reguljära uttryck kan du använda de mindre kraftfulla men också mycket enklare jokertecknen * och ? för att skriva matchningsregler. Jokertecknet * är en platshållare för noll eller flera tecken, medan jokertecknet ? är en platshållare för exakt ett tecken.
- En ny ”Inkludera”-åtgärd utöver ”Undanta”-åtgärden.
- ”Detect mime type”-åtgärden är borttagen. Om du vill indexera filer utan filtillägg som textfiler, använd kryssrutan med samma beskrivning under mönstertabellen.
- Matchning kan vara antingen skiftlägeskänslig eller skiftlägesokänslig. I DocFetcher å andra sidan är matchning alltid skiftlägeskänslig.
- Matchning kan utföras inte bara mot vanliga filer, utan också mot mappar och arkivfiler.
- På Windows, när regler matchas mot filsökvägar, kommer de senare att använda tecknet \ som sökvägsavskiljare, inte tecknet /. Exempel: C:\Sökväg\Till\Fil.docx, istället för C:/Sökväg/Till/Fil.docx.
Som resultat ser mönstertabellen i DocFetcher Pro ut så här:
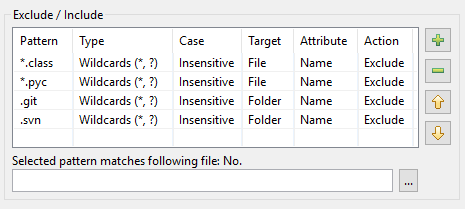
Mönstertabellen i DocFetcher Server ser likadan ut, men ”Valt mönster matchar följande fil”-testwidgeten under tabellen är för närvarande inte tillgänglig. Server Not available in DocFetcher Server
Klicka här för en detaljerad diskussion om mönstertabellen i DocFetcher, DocFetcher Pro och DocFetcher Server.
Så här kom översynen av mönstertabellen i DocFetcher Pro och DocFetcher Server till. Låt oss börja från början: I indexeringsdialogen i DocFetcher finns det en mönstertabell för att utföra vissa åtgärder på filer som matchas av vissa mönster under indexering:
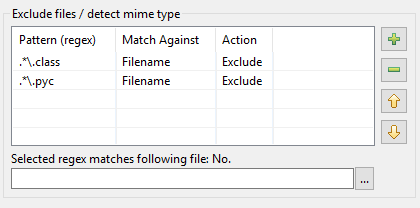
Mönstren måste vara så kallade reguljära uttryck, och vad gäller åtgärder finns två tillgängliga i DocFetcher: Att exkludera den matchade filen från indexering, och ”mime-type detection”, d.v.s. att försöka gissa det korrekta sättet att tolka den matchade filen baserat på filens innehåll snarare än baserat på dess filnamn. Hittills så gott. Men i praktiken visar det sig att ovanstående implementering har ett antal problem:
- Mycket få människor vet hur man skriver reguljära uttryck.
- Ibland vill man indexera endast vissa filer, och inte slösa indexeringstid på något annat i onödan. Till exempel, indexera endast ”txt”-filer och inget annat. DocFetcher kan faktiskt göra detta, men det innebär några ganska avancerade reguljära uttryckstrick.
- Ibland vill man utesluta från indexering alla filer som matchar ett visst mönster, utom alla filer som matchar ett visst annat mönster. Till exempel, uteslut från indexering alla PDF-filer, utom PDF-filer vars namn börjar med ”rapport_”. Återigen, i DocFetcher kräver detta avancerad användning av reguljära uttryck.
- Generellt sett är mime-type detection ganska oanvändbar eftersom: (1) Filtillägget är nästan alltid korrekt och därför i de flesta fall allt som behövs för att förstå filformatet. (2) När filtillägget inte är korrekt och mime-type detection behövs, visar sig det senare inte vara särskilt tillförlitligt ändå. (3) Ingen bryr sig om och/eller vet hur man skriver matchningsregler för de sällsynta fall där mime-type detection faktiskt skulle behövas. Dock visar det sig att mime-type detection har ett viktigt användningsfall i DocFetcher-sammanhang: Att få programmet att behandla filer utan filtillägg som vanliga textfiler, t.ex. filer som heter README. Dock dock, för att åstadkomma detta måste man skriva detta obskyra reguljära uttryck: [^.]*
- Mime-type detection kan misslyckas med att identifiera en fil som vanlig text om filen innehåller binär data.
- På grund av att den bärbara versionen av DocFetcher måste köras på alla stödda plattformar, när matchningsregler körs mot filsökvägar, använder de senare alltid tecknet / som sökvägsavskiljare, även på Windows, vilket är ganska kontraintuitivt för de flesta Windows-användare.
Kort sagt, DocFetchers mönstertabell är en enda röra, och omskrivningen som kom med DocFetcher Pro var en bra möjlighet att städa upp det hela:
- Jokertecken lades till och är inställda som standard så att nu även vanliga dödliga kan skriva matchningsregler.
- ”Inkludera”-åtgärden täcker både fallet där man vill indexera endast en specifik typ av fil, och fallet där man vill definiera undantag till matchningsregler. Även undantag-till-undantag är nu möjliga.
- Den allmänt oanvändbara ”Detect mime type”-åtgärden är borta, och dess huvudsakliga användningsfall, indexering av filer utan filtillägg som textfiler, täcks av en enkel kryssruta under mönstertabellen. Och denna kryssruta fungerar även om filen innehåller binär data.
- Windows sökvägsavskiljare-problemet är löst.
- Och några andra saker (skiftlägeskänslighet och matchning mot filer/mappar/arkiv) kastades in för att vara säker.
Ladda och spara indexeringsinställningar
Obs: Denna funktion är för närvarande endast tillgänglig i DocFetcher Pro, inte i DocFetcher Server. Server Not available in DocFetcher Server
Problemet: I DocFetcher, varje gång du skapar ett nytt index, måste du ange alla regler i mönstertabellen en efter en. Detta blir ganska tråkigt om du har många sådana regler. Det finns helt enkelt inget sätt att ladda och spara dem.

I DocFetcher Pro löses ovanstående problem på följande sätt: I det övre högra hörnet av indexeringsdialogen i DocFetcher Pro finns det en obetydlig liten ”burk med dokument”-knapp. Att klicka på denna knapp öppnar en meny som innehåller olika åtgärder för att ladda och spara indexeringsinställningar:
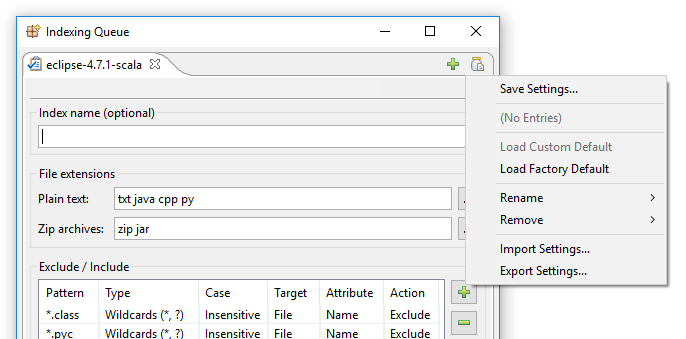
Att klicka på ”Spara inställningar” öppnar denna dialog:
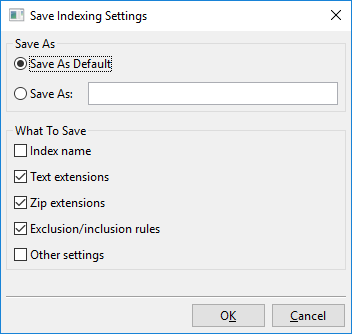
I grund och botten kan du med denna dialog antingen spara de för närvarande synliga indexeringsinställningarna till en ny namngiven plats, t.ex. ”Mina nya indexeringsinställningar”, eller spara de för närvarande synliga indexeringsinställningarna som ny standard.
Denna standard kallas ”Anpassad standardinställning” och kommer att laddas automatiskt när nya index skapas. Det finns också en ”Fabriksinställning”, som är standarden som DocFetcher Pro använder direkt ur lådan. De namngivna inställningarna du skapade, nämligen ”Anpassad standardinställning” och ”Fabriksinställning”, kan alla laddas via menyn som visas ovan.
För att avrunda saker och ting låter menyn dig också importera och exportera alla dina indexeringsinställningar så att du kan återanvända dem när du sätter upp DocFetcher Pro i en ny miljö.
Andra anmärkningsvärda förbättringar
FB2-stöd: DocFetcher Pro och DocFetcher Server har stöd för e-boksformatet FB2. Zip-komprimerade FB2-filer, med filtillägget fb2.zip eller fbz, stöds ”inbyggt”, d.v.s. DocFetcher Pro och DocFetcher Server ser varje sådan fil som en enda fil snarare än som en fil insvept i ett zip-arkiv.
Experimentellt Mobipocket-stöd: DocFetcher Pro och DocFetcher Server har stöd för e-boksformatet Mobipocket, med filtillägget ”mobi”. Observera dock att medan DocFetcher Pro och DocFetcher Server överlag gör ett ganska bra jobb med att extrahera text från mobi-filer, misslyckas de för närvarande antingen med att extrahera en liten del av texten i slutet av filen, eller i vissa fall misslyckas helt. Därför är Mobipocket-stödet för närvarande markerat som experimentellt.
7z-arkivstöd för det nuvarande v0.4-formatet: DocFetcher kan läsa 7z-arkiv upp till v0.3 av 7z-arkivformatet. DocFetcher Pro och DocFetcher Server kan också läsa 7z-arkiv i det nuvarande v0.4-formatet. Detta v0.4-format introducerades med 7-Zip 9.34, släppt 2014-11-23.
Utökat tar-arkivstöd: DocFetcher stöder följande tar-arkivtillägg: tar, tar.gz, tgz, tar.bz2, tb2, tbz. DocFetcher Pro och DocFetcher Server stöder dessutom följande tar-arkivtillägg: tbz2, tar.lzma, tlz, tar.xz, txz, tar.z, tz
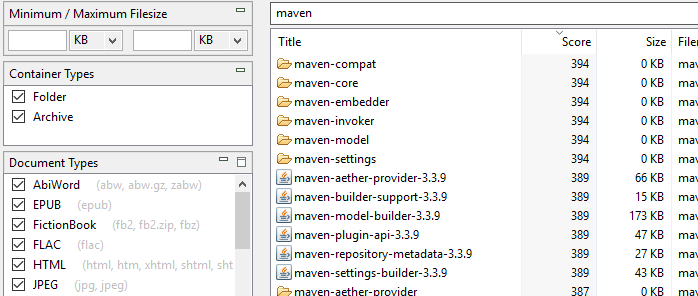
Indexering av mapp- och arkivnamn: Till skillnad från DocFetcher indexerar DocFetcher Pro och DocFetcher Server inte bara vanliga filer, utan också mappar och arkivfiler — eller mer precist, namnen på mappar och arkivfiler. Således kommer mappar och arkivfiler att visas i sökresultaten för DocFetcher Pro och DocFetcher Server. Det finns också ett Behållartyper-fönster på vänstra sidan av huvudapplikationsfönstret för att utesluta mappar och/eller arkiv från sökresultaten.
MacOS: Daemon för automatisk indexuppdatering: DocFetcher och DocFetcher Pro är kapabla till automatisk indexuppdatering, d.v.s. istället för att behöva starta indexuppdateringar manuellt, startas indexuppdateringar av programmet så snart filändringar upptäcks. Dock är denna funktionalitet endast tillgänglig medan de två programmen faktiskt körs. När de inte körs behövs en separat daemon-process för att fylla luckan. I DocFetcher är daemonen endast tillgänglig på Windows och Linux, medan den i DocFetcher Pro också är tillgänglig på macOS. Vad gäller DocFetcher Server behövs ingen daemon eftersom servern är designad att köras kontinuerligt. Server Not available in DocFetcher Server
Smartare filnamnsindexering: Indexering av filnamn i DocFetcher Pro och DocFetcher Server är smartare än i DocFetcher. Till exempel, om DocFetcher stöter på en fil som heter hitta_denna_fil.pdf, ser den ”hitta_denna_fil” som ett enda ord, inte som tre separata ord sammankopplade. Således kommer DocFetcher endast att hitta denna fil om du bokstavligt skriver in ”hitta_denna_fil” i DocFetchers sökfält. DocFetcher Pro och DocFetcher Server å andra sidan kommer att hitta filen om du skriver in ”hitta_denna_fil” eller något av de tre individuella orden. Generellt sett är det DocFetcher Pro och DocFetcher Server gör att känna igen tecken som understreck som potentiella ordavskiljare.

Filnamnsindexering vid fel: Om DocFetcher Pro och DocFetcher Server misslyckas med att läsa innehållet i en fil på grund av något fel eller på grund av lösenordsskydd, indexeras filnamnet ändå. I DocFetcher å andra sidan hoppas filen över helt.
Inga fel med djupt nästlade mappstrukturer: När man försöker indexera djupt nästlade mappstrukturer, som C:\mapp1\mapp2\...\mapp99\mapp100, är DocFetcher benägen att misslyckas med felet ”Folder hierarchy is too deep”. I programmerarjargong kallas detta för ”stack overflow”. DocFetcher Pro och DocFetcher Server å andra sidan är helt immuna mot denna typ av fel.
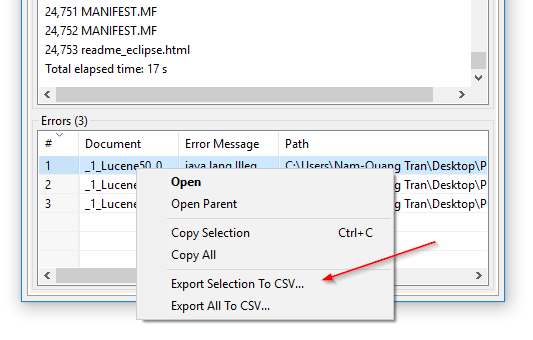
CSV-export av indexeringsfel: I DocFetcher Pro kan du exportera tabellen över filer som programmet misslyckades med att läsa under indexering till en CSV-fil. Detta kan göras via kontextmenyn för feltabellen, som visas i följande skärmbild. Denna funktion är för närvarande inte tillgänglig i DocFetcher Server. Server Not available in DocFetcher Server
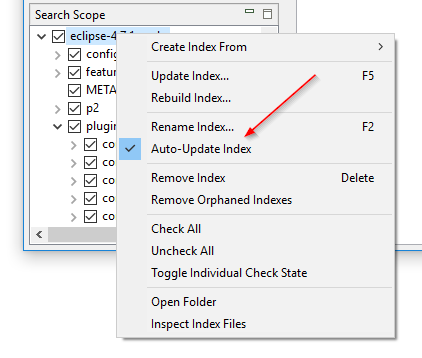
Slå på och av mappövervakning utan att bygga om indexet: DocFetchers ”Watch folders for file changes”-inställning, även känd som mappövervakning, är en per-index-inställning som när den är påslagen får programmet att automatiskt uppdatera indexet närhelst det upptäcker filändringar i den indexerade mappen. Problemet är att om du vill slå på eller av denna inställning på ett visst index måste du bygga om hela indexet. I DocFetcher Pro kan du slå på och av denna inställning utan att bygga om indexet, via kontextmenyn för sökområdesfönstret. Dessutom har inställningen döpts om till ”Uppdatera index automatiskt”. Liknande funktionalitet finns i DocFetcher Server.
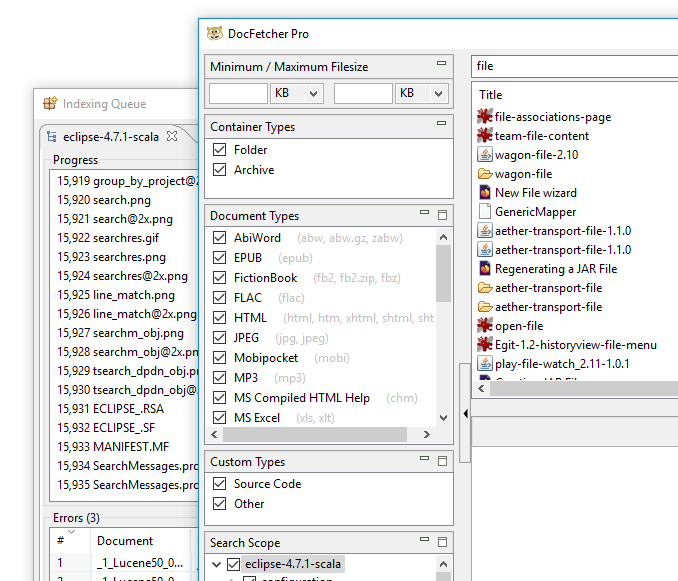
Samtidig sökning och indexombyggnad: I DocFetcher, om du väljer att bygga om ett index, blir detta index otillgängligt för sökning medan ombyggnaden pågår. I DocFetcher Pro och DocFetcher Server å andra sidan förblir indexet sökbart under ombyggnaden. (Mer precist, en gammal kopia av indexet förblir sökbar medan det faktiska indexet byggs om i bakgrunden.)
Windows: Fixad hantering av UNC-sökvägar: I DocFetcher är hanteringen av UNC-sökvägar på Windows allvarligt trasig och omdesignades från grunden i DocFetcher Pro. Omdesignen fördes sedan över till DocFetcher Server.
Icke-modal indexeringsdialog: I motsats till DocFetchers indexeringsdialog är den i DocFetcher Pro ”icke-modal”, vilket betyder att den inte är fäst vid huvudprogramfönstret och inte blockerar inmatning till huvudprogramfönstret medan den är öppen. Huvudfördelen med detta är att medan indexeringsprocesser körs kan du minimera huvudprogramfönstret, men hålla indexeringsdialogen synlig och parkerad på sidan. Detta låter dig hålla ett öga på indexeringsprocesserna medan du arbetar i andra applikationer. Denna funktion är inte tillämplig på DocFetcher Server. Server Not available in DocFetcher Server
Spela upp ljud efter indexering: Som standard spelar DocFetcher Pro upp ett ”klart”-ljud efter indexering. Detta kan stängas av i inställningarna. Denna funktion är för närvarande inte tillgänglig i DocFetcher Server. Server Not available in DocFetcher Server
Indexering av japansk text: DocFetcher har ett så kallat ”Ordsegmentering”-alternativ för att få användbara sökresultat när man indexerar kinesisk text. DocFetcher Pro har ett ytterligare ordsegmenteringsalternativ för hantering av japansk text. Både kinesisk och japansk ordsegmentering är för närvarande inte tillgängliga i DocFetcher Server. Server Not available in DocFetcher Server