Reformulação da Tabela de Padrões
A tabela de padrões no diálogo de indexação do DocFetcher Pro e a tabela de padrões no painel de indexação do DocFetcher Server diferem da do DocFetcher das seguintes maneiras:
- Além de expressões regulares, você pode usar os caracteres curinga * e ?, menos poderosos, mas também muito mais simples, para escrever regras de correspondência. O caractere curinga * é um espaço reservado para zero ou mais caracteres, enquanto o caractere curinga ? é um espaço reservado para exatamente um caractere.
- Uma nova ação “Incluir” além da ação “Excluir”.
- A ação “Detectar mime type” foi removida. Se você quiser indexar arquivos sem extensão como arquivos de texto, use a caixa de seleção com a mesma descrição abaixo da tabela de padrões.
- A correspondência pode ser sensível ou insensível a maiúsculas e minúsculas. No DocFetcher, por outro lado, a correspondência é sempre sensível a maiúsculas e minúsculas.
- A correspondência pode ser realizada não apenas contra arquivos regulares, mas também contra pastas e arquivos de arquivo morto.
- No Windows, quando as regras são correspondidas contra caminhos de arquivos, estes usarão o caractere \ como separador de caminho, não o caractere /. Exemplo: C:\Caminho\Para\Arquivo.docx, em vez de C:/Caminho/Para/Arquivo.docx.
Como resultado, é assim que a tabela de padrões no DocFetcher Pro se parece:
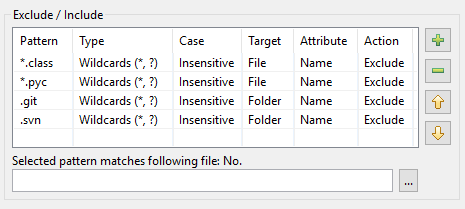
A tabela de padrões no DocFetcher Server tem a mesma aparência, mas o widget de teste “Padrão selecionado corresponde ao seguinte arquivo” abaixo da tabela não está disponível atualmente. Server Not available in DocFetcher Server
Clique aqui para uma discussão detalhada da tabela de padrões no DocFetcher, DocFetcher Pro e DocFetcher Server.
Veja como surgiu a reformulação da tabela de padrões no DocFetcher Pro e DocFetcher Server. Vamos começar do início: No diálogo de indexação do DocFetcher, existe uma tabela de padrões para executar certas ações em arquivos correspondidos por certos padrões durante a indexação:
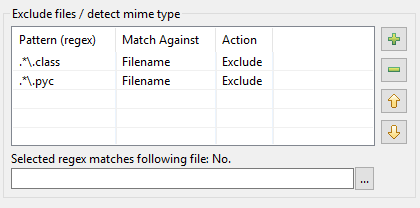
Os padrões precisam ser as chamadas expressões regulares, e quanto às ações, duas estão disponíveis no DocFetcher: Excluir o arquivo correspondido da indexação, e “detecção de mime-type”, ou seja, tentar adivinhar a maneira correta de analisar o arquivo correspondido com base no conteúdo do arquivo em vez de se basear em seu nome. Até aí, tudo bem. No entanto, na prática acontece que a implementação acima tem uma série de problemas:
- Muito poucas pessoas sabem como escrever expressões regulares.
- Às vezes alguém quer indexar apenas certos arquivos, e não desperdiçar desnecessariamente tempo de indexação com qualquer outra coisa. Por exemplo, indexar apenas arquivos “txt” e nada mais. O DocFetcher pode realmente fazer isso, mas envolve alguns truques de expressão regular bem avançados.
- Às vezes alguém quer excluir da indexação todos os arquivos que correspondem a um certo padrão, exceto todos os arquivos que correspondem a um certo outro padrão. Por exemplo, excluir da indexação todos os arquivos PDF, exceto arquivos PDF cujos nomes começam com “relatório_”. Novamente, no DocFetcher isso requer uso avançado de expressões regulares.
- Em geral, a detecção de mime-type é bastante inútil porque: (1) A extensão do arquivo quase sempre está correta e, portanto, na maioria dos casos é tudo que é necessário para descobrir o formato do arquivo. (2) Quando a extensão do arquivo não está correta e a detecção de mime-type é necessária, esta última acaba não sendo particularmente confiável de qualquer forma. (3) Ninguém se incomoda e/ou sabe como escrever regras de correspondência para esses casos raros onde a detecção de mime-type seria realmente necessária. No entanto, no contexto do DocFetcher acontece que a detecção de mime-type tem um caso de uso importante: Fazer o programa tratar arquivos sem extensão como arquivos de texto simples, por exemplo, arquivos chamados README. No entanto, para conseguir isso, é preciso escrever esta expressão regular obscura: [^.]*
- A detecção de mime-type pode falhar ao identificar um arquivo como texto simples se o arquivo contiver alguns dados binários.
- Devido ao fato de que a versão portátil do DocFetcher tem que rodar em todas as plataformas suportadas, quando as regras são correspondidas contra caminhos de arquivos, estes sempre usam o caractere / como separador de caminho, mesmo no Windows, o que é bastante contraintuitivo para a maioria dos usuários do Windows.
Resumindo, a tabela de padrões do DocFetcher é uma bagunça, e a reescrita que veio com o DocFetcher Pro foi uma boa oportunidade para limpar tudo:
- Caracteres curinga foram adicionados e definidos como padrão para que agora até pessoas comuns possam escrever regras de correspondência.
- A ação “Incluir” cobre tanto o caso onde alguém quer indexar apenas um tipo específico de arquivo, quanto o caso onde alguém quer definir exceções para regras de correspondência. Até exceções-para-exceções são agora possíveis.
- A ação geralmente inútil “Detectar mime type” foi removida, e seu principal caso de uso, indexar arquivos sem extensão como arquivos de texto, é coberto por uma simples caixa de seleção abaixo da tabela de padrões. E esta caixa de seleção funciona mesmo se o arquivo contiver alguns dados binários.
- O problema do separador de caminho do Windows foi corrigido.
- E algumas outras coisas (sensibilidade a maiúsculas/minúsculas e correspondência contra arquivos/pastas/arquivos mortos) foram incluídas por medida de segurança.
Carregar e Salvar Configurações de Indexação
Nota: Este recurso está atualmente disponível apenas no DocFetcher Pro, não no DocFetcher Server. Server Not available in DocFetcher Server
O problema: No DocFetcher, toda vez que você cria um novo índice, tem que inserir todas as regras na tabela de padrões uma por uma. Isso se torna bastante tedioso se você tem muitas dessas regras. Simplesmente não há maneira de carregá-las e salvá-las.
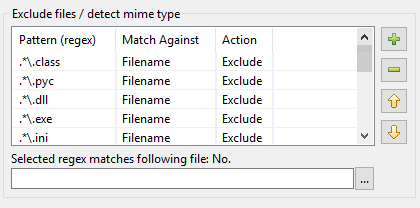
No DocFetcher Pro, o problema acima é resolvido da seguinte forma: No canto superior direito do diálogo de indexação do DocFetcher Pro, há um pequeno botão discreto “pote com documento”. Clicar neste botão abre um menu contendo várias ações para carregar e salvar configurações de indexação:
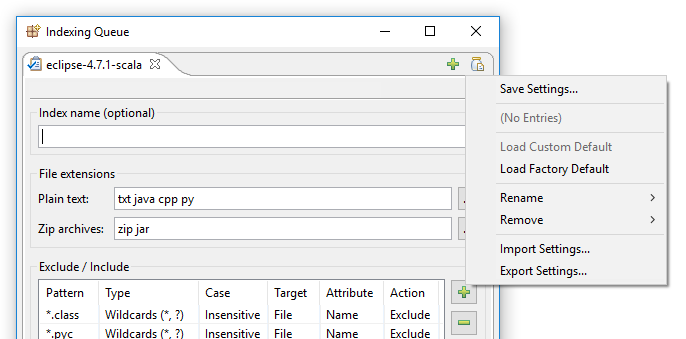
Clicar em “Salvar configurações” abre este diálogo:
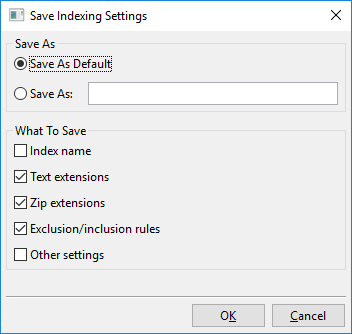
Essencialmente, o que você pode fazer com este diálogo é salvar as configurações de indexação atualmente visíveis em um novo slot nomeado, por exemplo, “Minhas Novas Configurações de Indexação”, ou salvar as configurações de indexação atualmente visíveis como o novo padrão.
Este padrão é chamado “Padrão personalizado” e será carregado automaticamente ao criar novos índices. Há também um “Padrão de fábrica”, que é o padrão que o DocFetcher Pro usa imediatamente. As configurações nomeadas que você criou, ou seja, “Padrão personalizado” e “Padrão de fábrica”, podem todas ser carregadas através do menu mostrado acima.
Para completar, o menu também permite importar e exportar todas as suas configurações de indexação para que você possa reusá-las ao configurar o DocFetcher Pro em um novo ambiente.
Outras Melhorias Notáveis
Suporte FB2: DocFetcher Pro e DocFetcher Server têm suporte para o formato de e-book FB2. Arquivos FB2 comprimidos em Zip, com extensão fb2.zip ou fbz, são suportados “nativamente”, ou seja, DocFetcher Pro e DocFetcher Server vêem cada arquivo como um único arquivo em vez de um arquivo envolvido em um arquivo zip.
Suporte experimental ao Mobipocket: DocFetcher Pro e DocFetcher Server têm suporte para o formato de e-book Mobipocket, com extensão “mobi”. No entanto, note que embora DocFetcher Pro e DocFetcher Server geralmente façam um trabalho bastante sólido de extrair texto de arquivos mobi, eles atualmente ou falham ao extrair uma pequena porção de texto no final do arquivo, ou em alguns casos falham completamente. Portanto, o suporte ao Mobipocket está por ora marcado como experimental.
Suporte a arquivos 7z para o formato v0.4 atual: DocFetcher pode ler arquivos 7z até v0.3 do formato de arquivo 7z. DocFetcher Pro e DocFetcher Server também podem ler arquivos 7z no formato v0.4 atual. Este formato v0.4 foi introduzido com o 7-Zip 9.34, lançado em 23-11-2014.
Suporte expandido a arquivos tar: DocFetcher suporta as seguintes extensões de arquivo tar: tar, tar.gz, tgz, tar.bz2, tb2, tbz. DocFetcher Pro e DocFetcher Server adicionalmente suportam as seguintes extensões de arquivo tar: tbz2, tar.lzma, tlz, tar.xz, txz, tar.z, tz
Indexação de nomes de pastas e arquivos mortos: Ao contrário do DocFetcher, DocFetcher Pro e DocFetcher Server indexam não apenas arquivos regulares, mas também pastas e arquivos mortos — ou mais precisamente, os nomes de pastas e arquivos mortos. Assim, pastas e arquivos mortos aparecerão nos resultados de busca do DocFetcher Pro e DocFetcher Server. Há também um painel Tipos de recipientes no lado esquerdo da janela principal da aplicação para excluir pastas e/ou arquivos mortos dos resultados de busca.
MacOS: Daemon para atualização automática de índice: DocFetcher e DocFetcher Pro são capazes de atualização automática de índice, ou seja, em vez de ter que iniciar atualizações de índice manualmente, as atualizações de índice são iniciadas pelo programa assim que mudanças de arquivos são detectadas. No entanto, esta funcionalidade só está disponível enquanto os dois programas estiverem realmente rodando. Quando eles não estão rodando, um processo daemon separado é necessário para preencher a lacuna. No DocFetcher, o daemon só está disponível no Windows e Linux, enquanto no DocFetcher Pro, também está disponível no macOS. Quanto ao DocFetcher Server, nenhum daemon é necessário já que o servidor é projetado para rodar continuamente. Server Not available in DocFetcher Server
Indexação mais inteligente de nomes de arquivos: A indexação de nomes de arquivos no DocFetcher Pro e DocFetcher Server é mais inteligente que no DocFetcher. Por exemplo, se o DocFetcher encontra um arquivo chamado encontrar_este_arquivo.pdf, ele vê “encontrar_este_arquivo” como uma única palavra, não como três palavras separadas ligadas. Assim, o DocFetcher só encontrará este arquivo se você digitar literalmente “encontrar_este_arquivo” no campo de busca do DocFetcher. DocFetcher Pro e DocFetcher Server por outro lado encontrarão o arquivo se você digitar “encontrar_este_arquivo” ou qualquer uma das três palavras individuais. Falando de forma geral, o que DocFetcher Pro e DocFetcher Server fazem é reconhecer caracteres como o sublinhado como potenciais separadores de palavras.

Indexação de nomes de arquivos em caso de erros: Se DocFetcher Pro e DocFetcher Server falharem ao ler o conteúdo de um arquivo devido a algum erro ou por causa de proteção por senha, o nome do arquivo ainda é indexado. No DocFetcher por outro lado, o arquivo é pulado completamente.
Sem erros com estruturas de pastas profundamente aninhadas: Ao tentar indexar estruturas de pastas profundamente aninhadas, como C:\pasta1\pasta2\...\pasta99\pasta100, o DocFetcher é propenso a falhar com um erro “Hierarquia de pastas muito profunda”. No jargão de programadores, isso é chamado de “stack overflow”. DocFetcher Pro e DocFetcher Server por outro lado são completamente imunes a este tipo de erro.
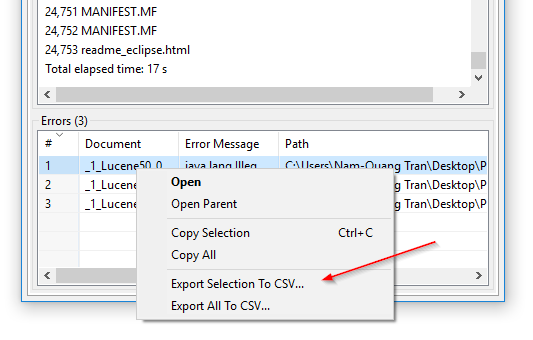
Exportação CSV de erros de indexação: No DocFetcher Pro, você pode exportar a tabela de arquivos que o programa falhou ao ler durante a indexação para um arquivo CSV. Isso pode ser feito através do menu de contexto da tabela de erros, como mostrado na captura de tela a seguir. Este recurso não está disponível atualmente no DocFetcher Server. Server Not available in DocFetcher Server
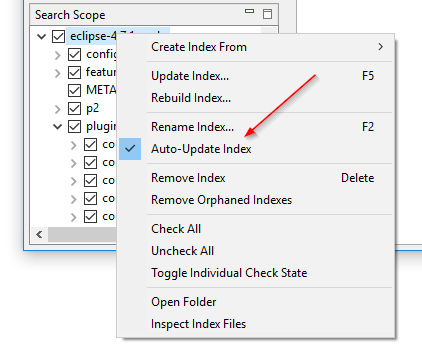
Ativar e desativar observação de pastas sem recriar o índice: A configuração “Observar mudanças nos arquivos das pastas” do DocFetcher, também conhecida como observação de pastas, é uma configuração por índice que quando ativada faz o programa atualizar automaticamente o índice sempre que detecta mudanças de arquivos na pasta indexada. O problema é que se você quiser ativar ou desativar esta configuração em um índice particular, tem que recriar todo o índice. No DocFetcher Pro, você pode ativar e desativar esta configuração sem recriar o índice, através do menu de contexto do painel Search Scope. Além disso, a configuração foi renomeada para “Atualizar índice automaticamente”. Funcionalidade similar existe no DocFetcher Server.
Busca simultânea e recriação de índice: No DocFetcher, se você escolher recriar um índice, esse índice se torna indisponível para busca enquanto a recriação está em progresso. No DocFetcher Pro e DocFetcher Server por outro lado, o índice permanece buscável durante a recriação. (Mais precisamente, uma cópia antiga do índice permanece buscável enquanto o índice real está sendo recriado em segundo plano.)
Windows: Tratamento corrigido de caminhos UNC: No DocFetcher, o tratamento de caminhos UNC no Windows está seriamente quebrado e foi reprojetado do zero no DocFetcher Pro. O reprojeto foi então transferido para o DocFetcher Server.
Diálogo de indexação não-modal: Em contraste com o diálogo de indexação do DocFetcher, o do DocFetcher Pro é “não-modal”, significando que não está anexado à janela principal do programa e não bloqueia entrada para a janela principal do programa enquanto está aberto. O principal benefício disso é que enquanto processos de indexação estão rodando, você pode minimizar a janela principal do programa, mas manter o diálogo de indexação visível e estacionado ao lado. Isso permite manter um olho nos processos de indexação enquanto faz trabalho em outras aplicações. Este recurso não se aplica ao DocFetcher Server. Server Not available in DocFetcher Server
Tocando um som após a indexação: Por padrão, o DocFetcher Pro toca um som de “terminado” após a indexação. Isso pode ser desligado nas preferências. Este recurso não está disponível atualmente no DocFetcher Server. Server Not available in DocFetcher Server
Indexação de texto japonês: DocFetcher tem uma opção chamada “segmentação de palavras” para obter resultados de busca usáveis ao indexar texto chinês. DocFetcher Pro tem uma opção adicional de segmentação de palavras para lidar com texto japonês. Tanto a segmentação de palavras chinesa quanto japonesa não estão disponíveis atualmente no DocFetcher Server. Server Not available in DocFetcher Server