Przebudowa tabeli wzorców
Tabela wzorców w oknie dialogowym indeksowania DocFetcher Pro i tabela wzorców w panelu indeksowania DocFetcher Server różnią się od tej w DocFetcher w następujących punktach:
- Oprócz wyrażeń regularnych, możesz używać mniej potężnych, ale także znacznie prostszych znaków wieloznacznych * i ? do tworzenia reguł dopasowywania. Znak wieloznaczny * jest symbolem zastępczym dla zero lub więcej znaków, podczas gdy znak wieloznaczny ? jest symbolem zastępczym dla dokładnie jednego znaku.
- Nowa akcja „Dołącz” w dodatku do akcji „Wyklucz”.
- Akcja „Wykryj typ mime” zniknęła. Jeśli chcesz indeksować pliki bez rozszerzenia jako pliki tekstowe, użyj pola wyboru o tym samym opisie poniżej tabeli wzorców.
- Dopasowywanie może być wrażliwe na wielkość liter lub niewrażliwe na wielkość liter. W DocFetcher z drugiej strony, dopasowywanie jest zawsze wrażliwe na wielkość liter.
- Dopasowywanie może być wykonywane nie tylko względem zwykłych plików, ale także względem folderów i plików archiwów.
- W systemie Windows, gdy reguły są dopasowywane względem ścieżek plików, te ostatnie będą używać znaku \ jako separatora ścieżki, nie znaku /. Przykład: C:\Ścieżka\Do\Pliku.docx, zamiast C:/Ścieżka/Do/Pliku.docx.
W rezultacie, tak wygląda tabela wzorców w DocFetcher Pro:
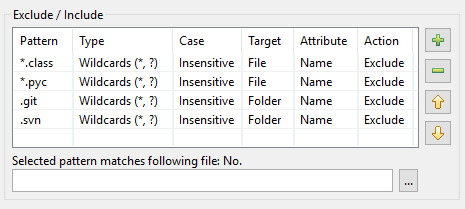
Tabela wzorców w DocFetcher Server wygląda tak samo, ale widget testowy „Wybrany wzorzec pasuje do następującego pliku” poniżej tabeli jest obecnie niedostępny. Server Not available in DocFetcher Server
Kliknij tutaj, aby uzyskać szczegółowe omówienie tabeli wzorców w DocFetcher, DocFetcher Pro i DocFetcher Server.
Oto jak doszło do przebudowy tabeli wzorców w DocFetcher Pro i DocFetcher Server. Zacznijmy od początku: W oknie dialogowym indeksowania DocFetcher, znajduje się tabela wzorców do wykonywania określonych akcji na plikach dopasowanych przez określone wzorce podczas indeksowania:
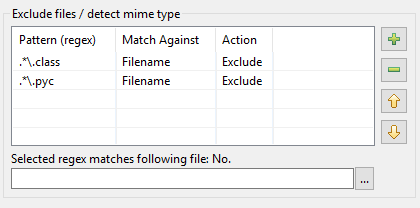
Wzorce muszą być tak zwanymi wyrażeniami regularnymi, a co do akcji, dwie są dostępne w DocFetcher: Wykluczenie dopasowanego pliku z indeksowania oraz „wykrywanie typu mime”, czyli próba odgadnięcia poprawnego sposobu parsowania dopasowanego pliku na podstawie zawartości pliku, a nie na podstawie jego nazwy. Jak dotąd, wszystko w porządku. Jednakże w praktyce okazuje się, że powyższa implementacja ma szereg problemów:
- Bardzo niewiele osób wie, jak pisać wyrażenia regularne.
- Czasami chce się indeksować tylko określone pliki, a nie niepotrzebnie tracić czasu indeksowania na cokolwiek innego. Na przykład, indeksować tylko pliki „txt” i nic więcej. DocFetcher może to faktycznie zrobić, ale wymaga to dość zaawansowanych tricków z wyrażeniami regularnymi.
- Czasami chce się wykluczyć z indeksowania wszystkie pliki pasujące do określonego wzorca, z wyjątkiem wszystkich plików pasujących do określonego innego wzorca. Na przykład, wykluczyć z indeksowania wszystkie pliki PDF, z wyjątkiem plików PDF, których nazwy zaczynają się od „raport_”. Ponownie, w DocFetcher wymaga to zaawansowanego użycia wyrażeń regularnych.
- Ogólnie rzecz biorąc, wykrywanie typu mime jest dość bezpożyteczne, ponieważ: (1) Rozszerzenie pliku jest prawie zawsze poprawne i dlatego w większości przypadków to wszystko, co jest potrzebne do określenia formatu pliku. (2) Gdy rozszerzenie pliku nie jest poprawne i wykrywanie typu mime jest potrzebne, to ostatnie okazuje się i tak nie być szczególnie niezawodne. (3) Nikt nie zadaje sobie trudu i/lub nie wie, jak napisać reguły dopasowywania dla tych rzadkich przypadków, gdzie wykrywanie typu mime byłoby rzeczywiście potrzebne. Jednakże, w kontekście DocFetcher okazuje się, że wykrywanie typu mime ma jeden ważny przypadek użycia: Sprawienie, aby program traktował pliki bez rozszerzenia jako zwykłe pliki tekstowe, np. pliki o nazwie README. Jednak jednak, aby to osiągnąć, trzeba napisać to niejasne wyrażenie regularne: [^.]*
- Wykrywanie typu mime może nie powiedzieć się w identyfikacji pliku jako zwykłego tekstu, jeśli plik zawiera niektóre dane binarne.
- Z uwagi na fakt, że przenośna wersja DocFetcher musi działać na wszystkich obsługiwanych platformach, gdy reguły są dopasowywane względem ścieżek plików, te ostatnie zawsze używają znaku / jako separatora ścieżki, nawet w systemie Windows, co jest dość nieintuicyjne dla większości użytkowników Windows.
Krótko mówiąc, tabela wzorców DocFetcher to kompletny bałagan, a przepisanie, które przyszło z DocFetcher Pro było dobą okazją do uporządkowania tego wszystkiego:
- Znaki wieloznaczne zostały dodane i są ustawione jako domyślne, więc teraz nawet zwykli śmiertelni mogą pisać reguły dopasowywania.
- Akcja „Dołącz” obejmuje zarówno przypadek, w którym chce się indeksować tylko określony rodzaj pliku, jak i przypadek, w którym chce się definiować wyjątki od reguł dopasowywania. Nawet wyjątki-od-wyjątków są teraz możliwe.
- Ogólnie bezpożyteczna akcja „Wykryj typ mime” zniknęła, a jej główny przypadek użycia, indeksowanie plików bez rozszerzenia jako plików tekstowych, jest obsługiwany przez proste pole wyboru poniżej tabeli wzorców. I to pole wyboru działa nawet jeśli plik zawiera niektóre dane binarne.
- Problem separatora ścieżki Windows został naprawiony.
- I kilka innych rzeczy (wrażliwość na wielkość liter i dopasowywanie względem plików/folderów/archiwów) zostało dodane dla pełnej miary.
Ładowanie i zapisywanie ustawień indeksowania
Uwaga: Ta funkcja jest obecnie dostępna tylko w DocFetcher Pro, nie w DocFetcher Server. Server Not available in DocFetcher Server
Problem: W DocFetcher, za każdym razem, gdy tworzysz nowy indeks, musisz wprowadzić wszystkie reguły w tabeli wzorców jedną po drugiej. Staje się to dość nużące, jeśli masz wiele takich reguł. Po prostu nie ma sposobu na załadowanie i zapisanie ich.
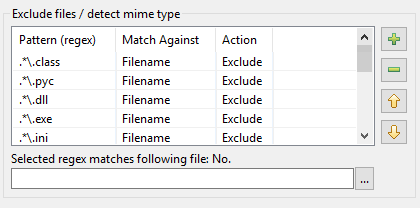
W DocFetcher Pro, powyższy problem jest rozwiązany następująco: W prawym górnym rogu okna dialogowego indeksowania DocFetcher Pro, znajduje się niepostrzeżenie mały przycisk „słoik z dokumentem”. Kliknięcie tego przycisku otwiera menu zawierające różne akcje do ładowania i zapisywania ustawień indeksowania:
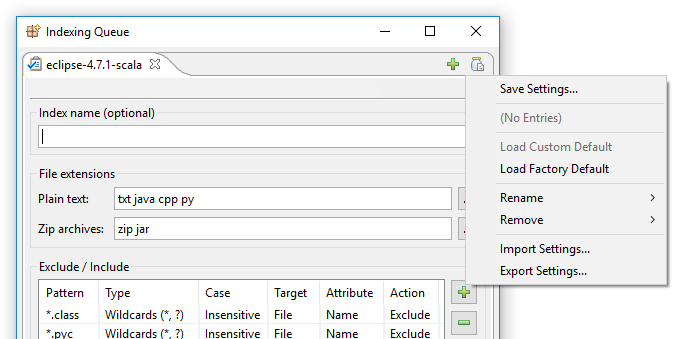
Kliknięcie na „Zapisz ustawienia” otwiera to okno dialogowe:
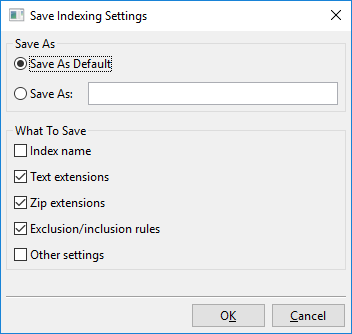
Zasadniczo, co możesz zrobić z tym oknem dialogowym, to albo zapisać aktualnie widoczne ustawienia indeksowania do nowego nazwowanego slotu, np. „Moje nowe ustawienia indeksowania”, albo zapisać aktualnie widoczne ustawienia indeksowania jako nową domyślną wartość.
Ta domyślna wartość nazywa się „Domyślne użytkownika” i będzie ładowana automatycznie podczas tworzenia nowych indeksów. Jest także „Domyślne fabryczne”, która jest domyślną wartością, którą DocFetcher Pro używa zaraz po instalacji. Nazwane ustawienia, które utworzyłeś, czyli „Domyślne użytkownika” i „Domyślne fabryczne”, mogą być wszystkie załadowane za pomocą menu pokazanego powyżej.
Aby zaokrąglić sprawy, menu także pozwala na import i eksport wszystkich Twoich ustawień indeksowania, więc możesz je ponownie użyć podczas konfigurowania DocFetcher Pro w nowym środowisku.
Inne znaczące usprawnienia
Obsługa FB2: DocFetcher Pro i DocFetcher Server mają obsługę formatu e-book FB2. Pliki FB2 skompresowane zip, z rozszerzeniem fb2.zip lub fbz, są obsługiwane „natywnie”, tzn. DocFetcher Pro i DocFetcher Server widzą każdy taki plik jako pojedynczy plik, a nie jako plik zapakowany w archiwum zip.
Eksperymentalna obsługa Mobipocket: DocFetcher Pro i DocFetcher Server mają obsługę formatu e-book Mobipocket, z rozszerzeniem „mobi”. Jednakże, należy zauważyć, że choć DocFetcher Pro i DocFetcher Server ogólnie radzą sobie całkiem dobrze z wydobywaniem tekstu z plików mobi, obecnie albo nie potrafią wydobyć małej części tekstu na końcu pliku, albo w niektórych przypadkach zawodzą całkowicie. Stąd obsługa Mobipocket jest na razie oznaczona jako eksperymentalna.
Obsługa archiwów 7z dla obecnego formatu v0.4: DocFetcher może czytać archiwa 7z do v0.3 formatu archiwum 7z. DocFetcher Pro i DocFetcher Server mogą także czytać archiwa 7z w obecnym formacie v0.4. Ten format v0.4 został wprowadzony z 7-Zip 9.34, wydanym 2014-11-23.
Rozszerzona obsługa archiwów tar: DocFetcher obsługuje następujące rozszerzenia archiwów tar: tar, tar.gz, tgz, tar.bz2, tb2, tbz. DocFetcher Pro i DocFetcher Server dodatkowo obsługują następujące rozszerzenia archiwów tar: tbz2, tar.lzma, tlz, tar.xz, txz, tar.z, tz
Indeksowanie nazw folderów i archiwów: W przeciwieństwie do DocFetcher, DocFetcher Pro i DocFetcher Server indeksują nie tylko zwykłe pliki, ale także foldery i pliki archiwów — lub dokładniej, nazwy folderów i plików archiwów. Tak więc, foldery i pliki archiwów pojawią się w wynikach wyszukiwania DocFetcher Pro i DocFetcher Server. Jest także panel Typy pojemników po lewej stronie głównego okna aplikacji, aby wykluczyć foldery i/lub archiwa z wyników wyszukiwania.
MacOS: Demon do automatycznego aktualizowania indeksu: DocFetcher i DocFetcher Pro są zdolne do automatycznego aktualizowania indeksu, tzn. zamiast musieć uruchamiać aktualizacje indeksu ręcznie, aktualizacje indeksu są uruchamiane przez program, jak tylko zostaną wykryte zmiany plików. Jednakże, ta funkcjonalność jest dostępna tylko wtedy, gdy oba programy rzeczywiście działają. Gdy nie działają, potrzebny jest oddzielny proces demona, aby wypełnić lukę. W DocFetcher, demon jest dostępny tylko w systemach Windows i Linux, podczas gdy w DocFetcher Pro jest także dostępny w macOS. Jeśli chodzi o DocFetcher Server, demon nie jest potrzebny, ponieważ serwer jest zaprojektowany do ciągłego działania. Server Not available in DocFetcher Server
Mądrzejsze indeksowanie nazw plików: Indeksowanie nazw plików w DocFetcher Pro i DocFetcher Server jest mądrzejsze niż w DocFetcher. Na przykład, jeśli DocFetcher napotka plik o nazwie znajdź_ten_plik.pdf, widzi „znajdź_ten_plik” jako pojedyncze słowo, nie jako trzy oddzielne słowa połączone razem. Tak więc DocFetcher znajdzie ten plik tylko wtedy, gdy dosłownie wpiszesz „znajdź_ten_plik” w polu wyszukiwania DocFetcher. DocFetcher Pro i DocFetcher Server z drugiej strony znajdą plik, jeśli wpiszesz „znajdź_ten_plik” lub dowolne z trzech pojedynczych słów. Ogólnie mówiąc, to, co robią DocFetcher Pro i DocFetcher Server, to rozpoznawanie znaków takich jak podkreślenie jako potencjalnych separatorów słów.

Indeksowanie nazw plików w przypadku błędów: Jeśli DocFetcher Pro i DocFetcher Server nie potrafią odczytać zawartości pliku z powodu pewnego błędu lub z powodu ochrony hasłem, nazwa pliku nadal zostaje zaindeksowana. W DocFetcher z drugiej strony, plik jest całkowicie pomijany.
Brak błędów z głęboko zagnieżdżonymi strukturami folderów: Podczas próby indeksowania głęboko zagnieżdżonych struktur folderów, takich jak C:\folder1\folder2\...\folder99\folder100, DocFetcher ma skłonność do niepowodzenia z błędem „Hierarchia folderów jest zbyt głęboka”. W żargonie programistów, nazywa się to „przepełnieniem stosu”. DocFetcher Pro i DocFetcher Server z drugiej strony są całkowicie odporne na tego rodzaju błąd.
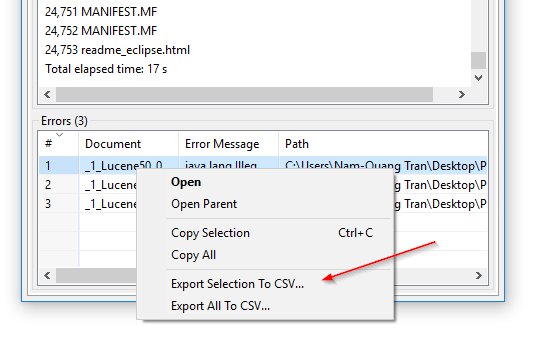
Eksport błędów indeksowania do CSV: W DocFetcher Pro możesz wyeksportować tabelę plików, których program nie potrafił odczytać podczas indeksowania, do pliku CSV. Można to zrobić za pomocą menu kontekstowego tabeli błędów, jak pokazano na następującym zrzucie ekranu. Ta funkcja jest obecnie niedostępna w DocFetcher Server. Server Not available in DocFetcher Server
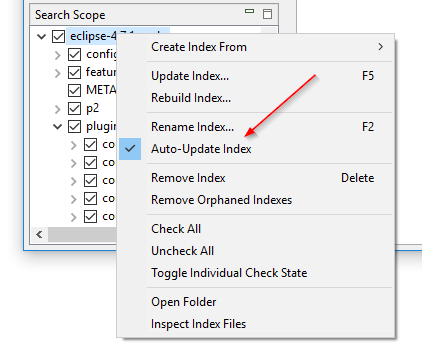
Włączanie i wyłączanie obserwowania folderów bez przebudowywania indeksu: Ustawienie „Obserwuj zmiany plików w folderach” DocFetcher, znane także jako obserwowanie folderów, jest ustawieniem per-indeks, które po włączeniu sprawia, że program automatycznie aktualizuje indeks, gdy wykryje zmiany plików w indeksowanym folderze. Problem polega na tym, że jeśli chcesz włączyć lub wyłączyć to ustawienie w konkretnym indeksie, musisz przebudować cały indeks. W DocFetcher Pro możesz włączyć i wyłączyć to ustawienie bez przebudowywania indeksu, za pomocą menu kontekstowego panelu Zakresu wyszukiwania. Także ustawienie zostało przemianowane na „Automatycznie aktualizuj indeks”. Podobna funkcjonalność istnieje w DocFetcher Server.
Jednoczesne wyszukiwanie i przebudowywanie indeksu: W DocFetcher, jeśli zdecydujesz się przebudować indeks, ten indeks staje się niedostępny do wyszukiwania podczas przebudowy. W DocFetcher Pro i DocFetcher Server z drugiej strony, indeks pozostaje przeszukiwalny podczas przebudowy. (Dokładniej, stara kopia indeksu pozostaje przeszukiwalna, podczas gdy rzeczywisty indeks jest przebudowywany w tle.)
Windows: Naprawiona obsługa ścieżek UNC: W DocFetcher, obsługa ścieżek UNC w systemie Windows jest bardzo źle zepsuty i została przeprojektowana od podstaw w DocFetcher Pro. Przeprojektowanie zostało następnie przeniesione do DocFetcher Server.
Niemodalny dialog indeksowania: W przeciwieństwie do dialogu indeksowania DocFetcher, ten w DocFetcher Pro jest „niemodalny”, co oznacza, że nie jest dołączony do głównego okna programu i nie blokuje wejścia do głównego okna programu, gdy jest otwarty. Główną korzyścią z tego jest to, że podczas gdy procesy indeksowania są uruchomione, możesz zminimalizować główne okno programu, ale zachować dialog indeksowania widoczny i zaparkowany z boku. Pozwala to na oko na procesy indeksowania podczas pracy w innych aplikacjach. Ta funkcja nie dotyczy DocFetcher Server. Server Not available in DocFetcher Server
Odtwarzanie dźwięku po indeksowaniu: Domyślnie, DocFetcher Pro odtwarza dźwięk „zakończono” po indeksowaniu. Można to wyłączyć w preferencjach. Ta funkcja jest obecnie niedostępna w DocFetcher Server. Server Not available in DocFetcher Server
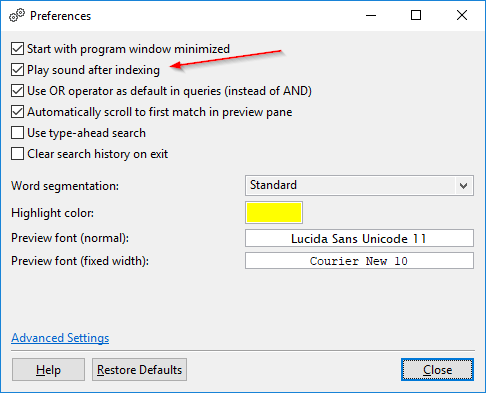
Indeksowanie tekstu japońskiego: DocFetcher ma tak zwaną opcję „segmentacji wyrazów”, aby uzyskać użyteczne wyniki wyszukiwania podczas indeksowania tekstu chińskiego. DocFetcher Pro ma dodatkową opcję segmentacji wyrazów do obsługi tekstu japońskiego. Zarówno chińska, jak i japońska segmentacja wyrazów są obecnie niedostępne w DocFetcher Server. Server Not available in DocFetcher Server