< 親ページに戻る
パターンテーブルの見直し
DocFetcher Proのインデックス処理ダイアログとDocFetcher Serverのインデックス処理ペインにあるパターンテーブルは、以下の点でDocFetcherのものとは異なります。
- 正規表現に加えて、より強力ではないがはるかに単純なワイルドカード * と ? を使ってマッチングルールを書くことができます。ワイルドカード * は*ゼロ個以上の*文字のプレースホルダーであり、ワイルドカード ? は*正確に1個の*文字のプレースホルダーです。
- 「除外」アクションに加えて、新しい「組み込み」アクションが追加されました。
- 「mimeタイプを検出」アクションはなくなりました。ファイル拡張子のないファイルをテキストファイルとしてインデックス処理したい場合は、パターンテーブルの下にある同じ説明のチェックボックスを使用してください。
- マッチングは、大文字と小文字を区別するか、区別しないかを選択できます。一方、DocFetcherでは、マッチングは常に大文字と小文字を区別します。
- マッチングは、通常のファイルだけでなく、フォルダやアーカイブファイルに対しても実行できます。
- Windowsでは、ルールがファイルパスと照合される場合、後者はパス区切り文字として / ではなく \ を使用します。例: C:\パス\へ\ファイル.docx であり、 C:/パス/へ/ファイル.docx ではありません。
その結果、DocFetcher Proのパターンテーブルは次のようになります。
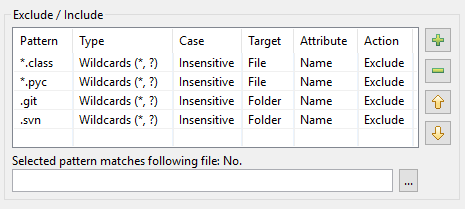
DocFetcher Serverのパターンテーブルも同じように見えますが、テーブルの下にある「選択したパターンは次のファイルに一致します」テストウィジェットは現在利用できません。 Server Not available in DocFetcher Server
DocFetcher、DocFetcher Pro、DocFetcher Serverのパターンテーブルの詳細な説明については、ここをクリックしてください。
DocFetcher ProとDocFetcher Serverのパターンテーブルの見直しがどのように行われたかを説明します。まず初めに、DocFetcherのインデックス処理ダイアログには、インデックス処理中に特定のパターンに一致するファイルに対して特定のアクションを実行するためのパターンテーブルがあります。
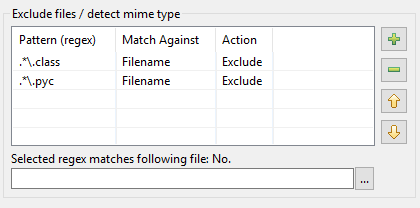
パターンは、いわゆる正規表現である必要があり、アクションとしては、DocFetcherでは2つが利用可能です。一致したファイルをインデックス処理から除外することと、「mimeタイプ検出」、つまりファイル名ではなくファイルの内容に基づいて一致したファイルを解析する正しい方法を推測しようとすることです。ここまでは順調です。しかし、実際には、上記の実装には多くの問題があることがわかります。
- 正規表現の書き方を知っている人はほとんどいません。
- 時には、特定のファイル*のみ*をインデックス処理し、他のものにインデックス処理時間を無駄にしたくない場合があります。たとえば、「txt」ファイルのみをインデックス処理し、他には何もしません。DocFetcherは実際にこれを行うことができますが、かなり高度な正規表現のトリックが必要です。
- 時には、特定のパターンに一致するすべてのファイルをインデックス処理から除外したいが、特定の*他の*パターンに一致するすべてのファイルは*除外*したい場合があります。たとえば、名前が「report_」で始まるPDFファイル*を除き*、すべてのPDFファイルをインデックス処理から除外します。これもまた、DocFetcherでは正規表現の高度な使用が必要です。
- 一般に、mimeタイプ検出はほとんど役に立ちません。なぜなら、(1)ファイル拡張子はほとんど常に正しく、したがってほとんどの場合、ファイル形式を把握するために必要なのはそれだけです。(2)ファイル拡張子が正しくなく、mimeタイプ検出が必要な場合、後者はとにかく特に信頼性が高くないことがわかります。(3)mimeタイプ検出が実際に必要となるまれなケースのために、マッチングルールを書くのに誰も手間をかけたり、書き方を知らなかったりします。しかし、DocFetcherの文脈では、mimeタイプ検出には1つの重要な使用例があることがわかります。ファイル拡張子のないファイルをプレーンテキストファイルとしてプログラムに扱わせることです。たとえば、 README という名前のファイルです。しかしながら、これを実現するには、 [^.]* という不可解な正規表現を書く必要があります。
- ファイルにバイナリデータが含まれている場合、mimeタイプ検出はファイルをプレーンテキストとして識別できない場合があります。
- DocFetcherのポータブル版はサポートされているすべてのプラットフォームで実行する必要があるため、ファイルパスに対してルールを照合する場合、後者はWindowsでも常にパス区切り文字として / を使用します。これは、ほとんどのWindowsユーザーにとって非常に直感的ではありません。
要するに、DocFetcherのパターンテーブルはごちゃごちゃしており、DocFetcher Proに付属していた書き直しは、それをすべて整理する良い機会でした。
- ワイルドカードが追加され、デフォルトとして設定されたため、今では一般の人でもマッチングルールを書くことができます。
- 「組み込み」アクションは、特定の種類のファイル*のみ*をインデックス処理したい場合と、マッチングルールに例外を定義したい場合の両方をカバーします。例外の例外も可能になりました。
- 一般的に役に立たない「mimeタイプを検出」アクションはなくなり、その主な使用例であるファイル拡張子のないファイルをテキストファイルとしてインデックス処理することは、パターンテーブルの下にある単純なチェックボックスでカバーされます。そして、このチェックボックスは、ファイルにバイナリデータが含まれている場合でも機能します。
- Windowsのパス区切り文字の問題は修正されました。
- そして、他のいくつかのもの(大文字と小文字の区別、ファイル/フォルダ/アーカイブに対するマッチング)もついでに追加されました。
インデックス処理設定の読み込みと保存
注意:この機能は現在、DocFetcher Proでのみ利用可能であり、DocFetcher Serverでは利用できません。 Server Not available in DocFetcher Server
問題点:DocFetcherでは、新しいインデックスを作成するたびに、パターンテーブルのすべてのルールを1つずつ入力する必要があります。このようなルールがたくさんある場合、これは非常に面倒になります。それらを読み込んで保存する方法がありません。
DocFetcher Proでは、上記の問題は次のように解決されます。DocFetcher Proのインデックス処理ダイアログの右上隅に、目立たない小さな「ドキュメントの入った瓶」ボタンがあります。このボタンをクリックすると、インデックス処理設定を読み込んだり保存したりするためのさまざまなアクションを含むメニューが開きます。
「設定を保存」をクリックすると、このダイアログが開きます。
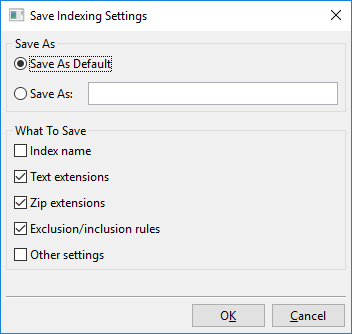
基本的に、このダイアログでできることは、現在表示されているインデックス処理設定を「私の新しいインデックス処理設定」などの新しい名前付きスロットに保存するか、現在表示されているインデックス処理設定を新しいデフォルトとして保存することです。
このデフォルトは「カスタム既定設定」と呼ばれ、新しいインデックスを作成するときに自動的に読み込まれます。また、「工場出荷時設定」もあり、これはDocFetcher Proが初期状態で使用するデフォルトです。作成した名前付き設定、つまり「カスタム既定設定」と「工場出荷時設定」は、すべて上記のメニューから読み込むことができます。
締めくくりとして、メニューではすべてのインデックス処理設定をインポートおよびエクスポートすることもできるため、新しい環境でDocFetcher Proを設定するときに再利用できます。
その他の注目すべき改善点
FB2サポート:DocFetcher ProとDocFetcher Serverは、電子書籍形式FB2をサポートしています。Zip圧縮されたFB2ファイル(ファイル拡張子fb2.zipまたはfbz)は「ネイティブに」サポートされています。つまり、DocFetcher ProとDocFetcher Serverは、そのような各ファイルをzipアーカイブにラップされたファイルとしてではなく、単一のファイルとして認識します。
実験的なMobipocketサポート:DocFetcher ProとDocFetcher Serverは、電子書籍形式Mobipocket(ファイル拡張子「mobi」)をサポートしています。ただし、DocFetcher ProとDocFetcher Serverは、mobiファイルからテキストを抽出する全体的な仕事はかなりしっかりしていますが、現在、ファイルの最後にあるテキストの小さな部分を抽出しそこなうか、場合によっては完全に失敗することに注意してください。したがって、Mobipocketのサポートは今のところ実験的なものとしてマークされています。
現在のv0.4形式の7zアーカイブサポート:DocFetcherは、7zアーカイブ形式のv0.3までの7zアーカイブを読み取ることができます。DocFetcher ProとDocFetcher Serverは、現在のv0.4形式の7zアーカイブも読み取ることができます。このv0.4形式は、2014-11-23にリリースされた7-Zip 9.34で導入されました。
拡張tarアーカイブサポート:DocFetcherは、次のtarアーカイブ拡張子をサポートしています:tar、tar.gz、tgz、tar.bz2、tb2、tbz。DocFetcher ProとDocFetcher Serverは、さらに次のtarアーカイブ拡張子をサポートしています:tbz2、tar.lzma、tlz、tar.xz、txz、tar.z、tz
フォルダとアーカイブ名のインデックス処理:DocFetcherとは異なり、DocFetcher ProとDocFetcher Serverは、通常のファイルだけでなく、フォルダとアーカイブファイル、より正確にはフォルダとアーカイブファイルの名前もインデックス処理します。したがって、フォルダとアーカイブファイルは、DocFetcher ProとDocFetcher Serverの検索結果に表示されます。また、メインアプリケーションウィンドウの左側には、検索結果からフォルダやアーカイブを除外するためのコンテナタイプペインもあります。
MacOS:自動インデックス更新のためのデーモン:DocFetcherとDocFetcher Proは、自動インデックス更新が可能です。つまり、インデックス更新を手動で開始する必要はなく、ファイルの変更が検出されるとすぐにプログラムによってインデックス更新が開始されます。ただし、この機能は、2つのプログラムが実際に実行されている間のみ利用可能です。実行されていない場合は、ギャップを埋めるために別のデーモンプロセスが必要です。DocFetcherでは、デーモンはWindowsとLinuxでのみ利用可能ですが、DocFetcher Proでは、macOSでも利用可能です。DocFetcher Serverについては、サーバーは継続的に実行するように設計されているため、デーモンは必要ありません。 Server Not available in DocFetcher Server
よりスマートなファイル名インデックス処理:DocFetcher ProとDocFetcher Serverでのファイル名のインデックス処理は、DocFetcherよりもスマートです。たとえば、DocFetcherが find_this_file.pdf という名前のファイルに遭遇した場合、「find_this_file」を1つの単語として認識し、3つの別々の単語が連結されたものとは認識しません。したがって、DocFetcherの検索フィールドに文字通り「find_this_file」と入力した場合にのみ、DocFetcherはこのファイルを見つけます。一方、DocFetcher ProとDocFetcher Serverは、「find_this_file」または3つの個々の単語のいずれかを入力すると、ファイルを見つけます。一般的に言えば、DocFetcher ProとDocFetcher Serverが行うことは、アンダースコアなどの文字を潜在的な単語区切り文字として認識することです。

エラー時のファイル名インデックス処理:DocFetcher ProとDocFetcher Serverが、何らかのエラーまたはパスワード保護のためにファイルの内容を読み取れなかった場合でも、ファイル名はインデックス処理されます。一方、DocFetcherでは、ファイルは完全にスキップされます。
深くネストされたフォルダ構造でのエラーなし: C:\フォルダ1\フォルダ2\...\フォルダ99\フォルダ100 のような深くネストされたフォルダ構造をインデックス処理しようとすると、DocFetcherは「フォルダ階層が深すぎます」というエラーで失敗しがちです。プログラマーの専門用語では、これは「スタックオーバーフロー」と呼ばれます。一方、DocFetcher ProとDocFetcher Serverは、この種のエラーに対して完全に耐性があります。
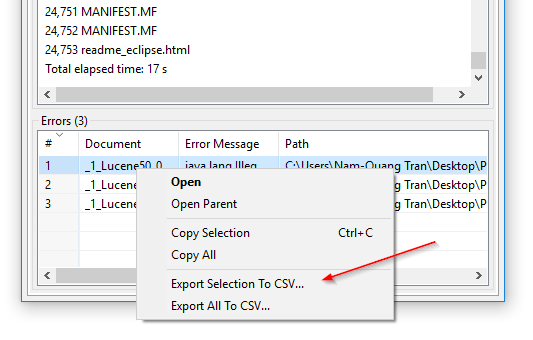
インデックス処理エラーのCSVエクスポート:DocFetcher Proでは、プログラムがインデックス処理中に読み取れなかったファイルのテーブルをCSVファイルにエクスポートできます。これは、次のスクリーンショットに示すように、エラーテーブルのコンテキストメニューから実行できます。この機能は現在、DocFetcher Serverでは利用できません。 Server Not available in DocFetcher Server
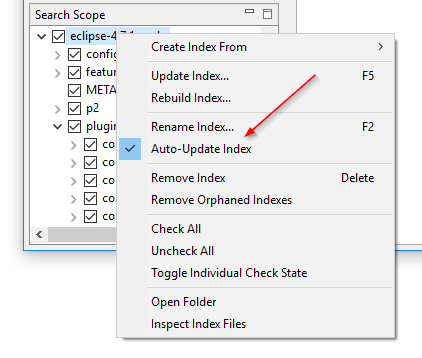
インデックスを再構築せずにフォルダ監視のオン/オフを切り替える:DocFetcherの「ファイルが変更されたかフォルダを監視」設定(フォルダ監視とも呼ばれる)は、インデックスごとの設定であり、オンにすると、インデックス付きフォルダでファイルの変更を検出するたびにプログラムがインデックスを自動更新します。問題は、特定のインデックスでこの設定をオンまたはオフにしたい場合、インデックス全体を再構築する必要があることです。DocFetcher Proでは、検索スコープペインのコンテキストメニューから、インデックスを再構築*せずに*この設定をオンまたはオフにできます。また、設定は「インデックスを自動更新」に名前が変更されました。同様の機能がDocFetcher Serverにも存在します。
検索とインデックス再構築の同時実行:DocFetcherでは、インデックスを再構築することを選択した場合、再構築の進行中は、そのインデックスは検索できなくなります。一方、DocFetcher ProとDocFetcher Serverでは、再構築中もインデックスは検索可能なままです。(より正確には、実際のインデックスがバックグラウンドで再構築されている間、インデックスの古いコピーが検索可能なままです。)
Windows:UNCパスの処理の修正:DocFetcherでは、WindowsでのUNCパスの処理がひどく壊れており、DocFetcher Proでゼロから再設計されました。この再設計は、その後DocFetcher Serverに引き継がれました。
非モーダルインデックス処理ダイアログ:DocFetcherのインデックス処理ダイアログとは対照的に、DocFetcher Proのダイアログは「非モーダル」です。つまり、メインプログラムウィンドウにアタッチされておらず、開いている間はメインプログラムウィンドウへの入力をブロックしません。これの主な利点は、インデックス処理プロセスが実行されている間、メインプログラムウィンドウを最小化し、インデックス処理ダイアログを表示したまま横に置いておくことができることです。これにより、他のアプリケーションで作業しながらインデックス処理プロセスを監視できます。この機能はDocFetcher Serverには適用されません。 Server Not available in DocFetcher Server
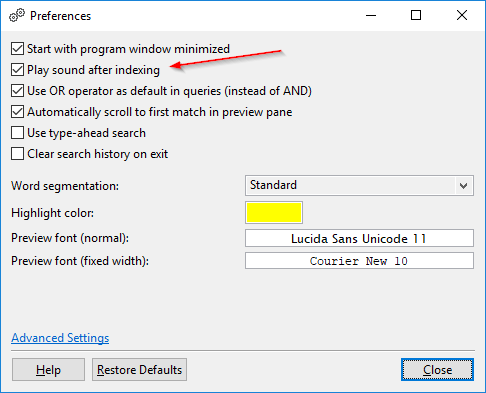
インデックス処理後のサウンド再生:デフォルトでは、DocFetcher Proはインデックス処理後に「完了」サウンドを再生します。これは設定でオフにできます。この機能は現在、DocFetcher Serverでは利用できません。 Server Not available in DocFetcher Server
日本語テキストのインデックス処理:DocFetcherには、中国語テキストをインデックス処理する際に実用的な検索結果を得るための、いわゆる「単語分割」オプションがあります。DocFetcher Proには、日本語テキストを処理するための追加の単語分割オプションがあります。中国語と日本語の両方の単語分割は、現在DocFetcher Serverでは利用できません。 Server Not available in DocFetcher Server