Renovación de la Tabla de Patrones
La tabla de patrones del diálogo de indexación de DocFetcher Pro y la tabla de patrones del panel de indexación de DocFetcher Server difieren de la de DocFetcher en las siguientes formas:
- Además de expresiones regulares, puedes usar los comodines * y ?, que son menos potentes pero también mucho más simples, para escribir reglas de coincidencia. El comodín * es un marcador de posición para cero o más caracteres, mientras que el comodín ? es un marcador de posición para exactamente un carácter.
- Una nueva acción «Incluir» además de la acción «Excluir».
- La acción «Detectar tipo mime» ha desaparecido. Si quieres indexar archivos sin extensión de archivo como archivos de texto, usa la casilla de verificación con la misma descripción debajo de la tabla de patrones.
- La coincidencia puede ser sensible a mayúsculas y minúsculas o insensible a mayúsculas y minúsculas. En DocFetcher, por otro lado, la coincidencia siempre es sensible a mayúsculas y minúsculas.
- La coincidencia se puede realizar no solo contra archivos regulares, sino también contra carpetas y archivos de archivo.
- En Windows, cuando las reglas se comparan contra rutas de archivos, estas últimas usarán el carácter \ como separador de ruta, no el carácter /. Ejemplo: C:\Ruta\A\Archivo.docx, en lugar de C:/Ruta/A/Archivo.docx.
Como resultado, así es como se ve la tabla de patrones en DocFetcher Pro:
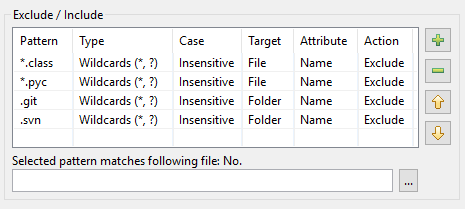
La tabla de patrones en DocFetcher Server se ve igual, pero el widget de prueba «El patrón seleccionado coincide con el siguiente archivo» debajo de la tabla actualmente no está disponible. Server Not available in DocFetcher Server
Haz clic aquí para una discusión detallada de la tabla de patrones en DocFetcher, DocFetcher Pro y DocFetcher Server.
Así es como surgió la renovación de la tabla de patrones en DocFetcher Pro y DocFetcher Server. Empecemos desde el principio: En el diálogo de indexación de DocFetcher, hay una tabla de patrones para realizar ciertas acciones en archivos que coinciden con ciertos patrones durante la indexación:
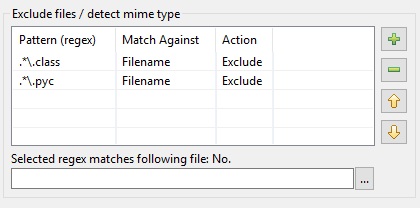
Los patrones necesitan ser las llamadas expresiones regulares, y en cuanto a acciones, dos están disponibles en DocFetcher: Excluir el archivo coincidente de la indexación, y «detección de tipo mime», es decir, tratar de adivinar la forma correcta de analizar el archivo coincidente basándose en el contenido del archivo en lugar de basarse en su nombre de archivo. Hasta aquí, todo bien. Sin embargo, en la práctica resulta que la implementación anterior tiene varios problemas:
- Muy pocas personas saben cómo escribir expresiones regulares.
- A veces uno quiere indexar solo ciertos archivos, y no desperdiciar innecesariamente tiempo de indexación en cualquier otra cosa. Por ejemplo, indexar solo archivos «txt» y nada más. DocFetcher puede hacer esto, pero implica trucos bastante avanzados de expresiones regulares.
- A veces uno quiere excluir de la indexación todos los archivos que coinciden con un cierto patrón, excepto todos los archivos que coinciden con un cierto otro patrón. Por ejemplo, excluir de la indexación todos los archivos PDF, excepto archivos PDF cuyos nombres empiecen con «informe_». De nuevo, en DocFetcher esto requiere uso avanzado de expresiones regulares.
- En general, la detección de tipo mime es bastante inútil porque: (1) La extensión del archivo es casi siempre correcta y por lo tanto en la mayoría de los casos es todo lo que se necesita para averiguar el formato del archivo. (2) Cuando la extensión del archivo no es correcta y se necesita detección de tipo mime, esta última resulta no ser particularmente confiable de todos modos. (3) Nadie se molesta en y/o sabe cómo escribir reglas de coincidencia para esos casos raros donde la detección de tipo mime sería realmente necesaria. Sin embargo, en el contexto de DocFetcher resulta que la detección de tipo mime sí tiene un caso de uso importante: Hacer que el programa trate archivos sin extensión de archivo como archivos de texto plano, por ejemplo, archivos llamados README. Sin embargo sin embargo, para lograr esto, uno necesita escribir esta expresión regular oscura: [^.]*
- La detección de tipo mime puede fallar al identificar un archivo como texto plano si el archivo contiene algunos datos binarios.
- Debido al hecho de que la versión portátil de DocFetcher tiene que ejecutarse en todas las plataformas soportadas, cuando las reglas se comparan contra rutas de archivos, estas últimas siempre usan el carácter / como separador de ruta, incluso en Windows, lo cual es bastante contraintuitivo para la mayoría de usuarios de Windows.
En resumen, la tabla de patrones de DocFetcher es un desastre, y la reescritura que vino con DocFetcher Pro fue una buena oportunidad para limpiar todo esto:
- Se agregaron comodines y se establecieron como predeterminados para que ahora incluso simples mortales puedan escribir reglas de coincidencia.
- La acción «Incluir» cubre tanto el caso donde uno quiere indexar solo un tipo específico de archivo, como el caso donde uno quiere definir excepciones a las reglas de coincidencia. Incluso excepciones-a-excepciones ahora son posibles.
- La generalmente inútil acción «Detectar tipo mime» ha desaparecido, y su caso de uso principal, indexar archivos sin extensión de archivo como archivos de texto, está cubierto por una simple casilla de verificación debajo de la tabla de patrones. Y esta casilla de verificación funciona incluso si el archivo contiene algunos datos binarios.
- El problema del separador de ruta de Windows está arreglado.
- Y algunas otras cosas (sensibilidad a mayúsculas y minúsculas y coincidencia contra archivos/carpetas/archivos) se agregaron por si acaso.
Cargar y Guardar Configuraciones de Indexación
Nota: Esta característica actualmente solo está disponible en DocFetcher Pro, no en DocFetcher Server. Server Not available in DocFetcher Server
El problema: En DocFetcher, cada vez que creas un nuevo índice, tienes que ingresar todas las reglas en la tabla de patrones una por una. Esto se vuelve bastante tedioso si tienes muchas de estas reglas. Simplemente no hay manera de cargarlas y guardarlas.
En DocFetcher Pro, el problema anterior se resuelve de la siguiente manera: En la esquina superior derecha del diálogo de indexación de DocFetcher Pro, se encuentra un discreto pequeño botón de «frasco con documento». Hacer clic en este botón abre un menú que contiene varias acciones para cargar y guardar configuraciones de indexación:
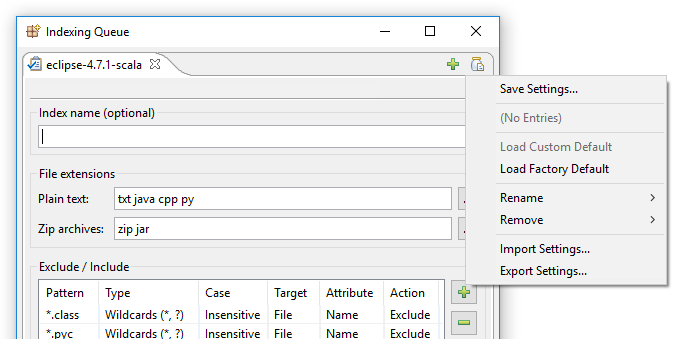
Hacer clic en «Guardar configuraciones» abre este diálogo:
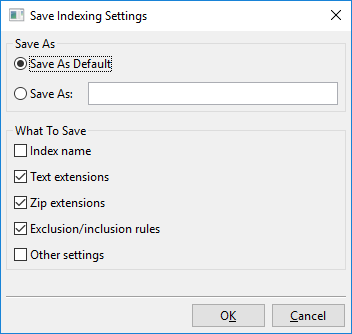
Esencialmente, lo que puedes hacer con este diálogo es guardar las configuraciones de indexación actualmente visibles a una nueva ranura con nombre, por ejemplo, «Mis Nuevas Configuraciones de Indexación», o guardar las configuraciones de indexación actualmente visibles como el nuevo predeterminado.
Este predeterminado se llama «Predeterminado personalizado» y se cargará automáticamente al crear nuevos índices. También hay un «Predeterminado de fábrica», que es el predeterminado que DocFetcher Pro usa de fábrica. Las configuraciones con nombre que creaste, a saber «Predeterminado personalizado» y «Predeterminado de fábrica», pueden todas cargarse a través del menú mostrado arriba.
Para completar las cosas, el menú también te permite importar y exportar todas tus configuraciones de indexación para que puedas reutilizarlas al configurar DocFetcher Pro en un nuevo entorno.
Otras Mejoras Notables
Soporte para FB2: DocFetcher Pro y DocFetcher Server tienen soporte para el formato de libro electrónico FB2. Los archivos FB2 comprimidos con zip, con extensión de archivo fb2.zip o fbz, son soportados «nativamente», es decir, DocFetcher Pro y DocFetcher Server ven cada uno de estos archivos como un archivo único en lugar de como un archivo envuelto en un archivo zip.
Soporte experimental para Mobipocket: DocFetcher Pro y DocFetcher Server tienen soporte para el formato de libro electrónico Mobipocket, con extensión de archivo «mobi». Sin embargo, ten en cuenta que aunque DocFetcher Pro y DocFetcher Server en general hacen un trabajo bastante sólido extrayendo texto de archivos mobi, actualmente fallan al extraer una pequeña porción de texto al final del archivo, o en algunos casos fallan completamente. Por tanto, el soporte para Mobipocket está marcado como experimental por ahora.
Soporte para archivos 7z para el formato v0.4 actual: DocFetcher puede leer archivos 7z hasta la versión v0.3 del formato de archivo 7z. DocFetcher Pro y DocFetcher Server también pueden leer archivos 7z en el formato v0.4 actual. Este formato v0.4 se introdujo con 7-Zip 9.34, lanzado el 23-11-2014.
Soporte ampliado para archivos tar: DocFetcher soporta las siguientes extensiones de archivo tar: tar, tar.gz, tgz, tar.bz2, tb2, tbz. DocFetcher Pro y DocFetcher Server adicionalmente soportan las siguientes extensiones de archivo tar: tbz2, tar.lzma, tlz, tar.xz, txz, tar.z, tz
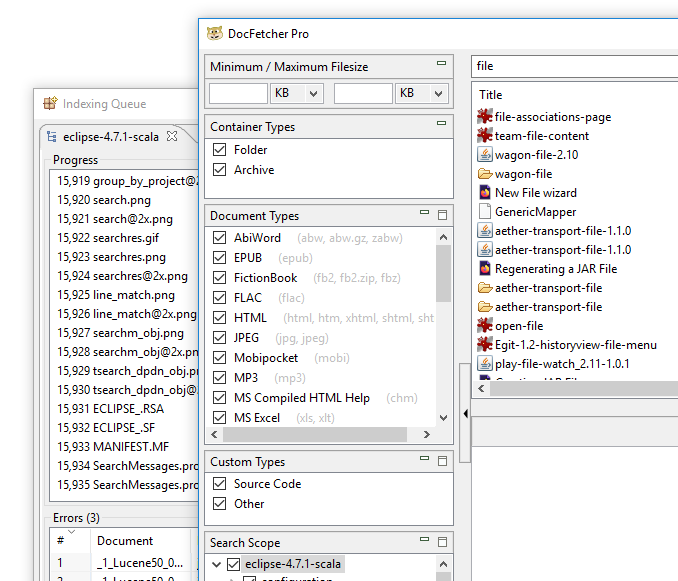
Indexación de nombres de carpetas y archivos: A diferencia de DocFetcher, DocFetcher Pro y DocFetcher Server indexan no solo archivos regulares, sino también carpetas y archivos de archivo — o más precisamente, los nombres de carpetas y archivos de archivo. Por tanto, las carpetas y archivos de archivo aparecerán en los resultados de búsqueda de DocFetcher Pro y DocFetcher Server. También hay un panel Tipos de contenedor en el lado izquierdo de la ventana principal de la aplicación para excluir carpetas y/o archivos de los resultados de búsqueda.
MacOS: Demonio para actualización automática de índice: DocFetcher y DocFetcher Pro son capaces de actualización automática de índice, es decir, en lugar de tener que iniciar actualizaciones de índice manualmente, las actualizaciones de índice son iniciadas por el programa tan pronto como se detectan cambios en archivos. Sin embargo, esta funcionalidad solo está disponible mientras los dos programas están realmente ejecutándose. Cuando no están ejecutándose, se necesita un proceso demonio separado para llenar el vacío. En DocFetcher, el demonio solo está disponible en Windows y Linux, mientras que en DocFetcher Pro, también está disponible en macOS. En cuanto a DocFetcher Server, no se necesita demonio ya que el servidor está diseñado para ejecutarse continuamente. Server Not available in DocFetcher Server
Indexación más inteligente de nombres de archivo: La indexación de nombres de archivo en DocFetcher Pro y DocFetcher Server es más inteligente que en DocFetcher. Por ejemplo, si DocFetcher encuentra un archivo llamado encontrar_este_archivo.pdf, ve «encontrar_este_archivo» como una sola palabra, no como tres palabras separadas unidas. Por tanto, DocFetcher solo encontrará este archivo si literalmente escribes «encontrar_este_archivo» en el campo de búsqueda de DocFetcher. DocFetcher Pro y DocFetcher Server, por otro lado, encontrarán el archivo si escribes «encontrar_este_archivo» o cualquiera de las tres palabras individuales. En general, lo que DocFetcher Pro y DocFetcher Server hacen es reconocer caracteres como el guión bajo como potenciales separadores de palabras.

Indexación de nombres de archivo en caso de errores: Si DocFetcher Pro y DocFetcher Server fallan al leer el contenido de un archivo debido a algún error o por protección con contraseña, el nombre del archivo aún se indexa. En DocFetcher, por otro lado, el archivo se omite por completo.
Sin errores con estructuras de carpetas profundamente anidadas: Al tratar de indexar estructuras de carpetas profundamente anidadas, como C:\carpeta1\carpeta2\...\carpeta99\carpeta100, DocFetcher es propenso a fallar con un error de «Jerarquía de carpetas demasiado profunda». En jerga de programadores, esto se llama «desbordamiento de pila». DocFetcher Pro y DocFetcher Server, por otro lado, son completamente inmunes a este tipo de error.
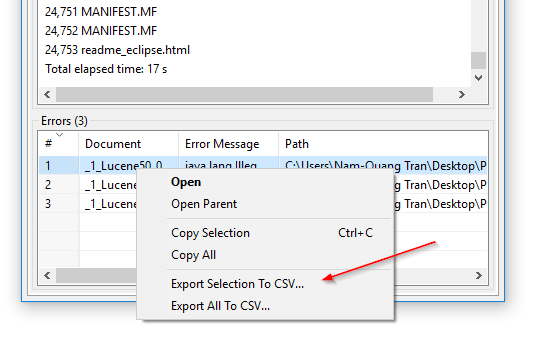
Exportación CSV de errores de indexación: En DocFetcher Pro, puedes exportar la tabla de archivos que el programa falló en leer durante la indexación a un archivo CSV. Esto se puede hacer a través del menú contextual de la tabla de errores, como se muestra en la siguiente captura de pantalla. Esta característica actualmente no está disponible en DocFetcher Server. Server Not available in DocFetcher Server
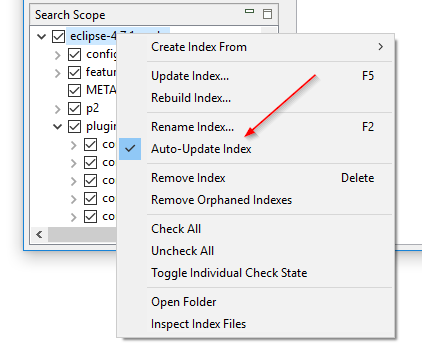
Activar y desactivar la vigilancia de carpetas sin reconstruir el índice: La configuración «Vigilar cambios de ficheros en las carpetas» de DocFetcher, también conocida como vigilancia de carpetas, es una configuración por índice que cuando se activa hace que el programa actualice automáticamente el índice cada vez que detecta cambios de archivo en la carpeta indexada. El problema es que si quieres activar o desactivar esta configuración en un índice particular, tienes que reconstruir todo el índice. En DocFetcher Pro, puedes activar y desactivar esta configuración sin reconstruir el índice, a través del menú contextual del panel de Ámbito de Búsqueda. También, la configuración ha sido renombrada a «Actualizar índice automáticamente». Funcionalidad similar existe en DocFetcher Server.
Búsqueda simultánea y reconstrucción de índice: En DocFetcher, si eliges reconstruir un índice, ese índice se vuelve no disponible para búsqueda mientras la reconstrucción está en progreso. En DocFetcher Pro y DocFetcher Server, por otro lado, el índice permanece buscable durante la reconstrucción. (Más precisamente, una copia antigua del índice permanece buscable mientras el índice actual está siendo reconstruido en segundo plano.)
Windows: Manejo arreglado de rutas UNC: En DocFetcher, el manejo de rutas UNC en Windows está muy dañado y fue rediseñado desde cero en DocFetcher Pro. El rediseño fue luego llevado a DocFetcher Server.
Diálogo de indexación no modal: En contraste con el diálogo de indexación de DocFetcher, el de DocFetcher Pro es «no modal», significando que no está conectado a la ventana principal del programa y no bloquea la entrada a la ventana principal del programa mientras está abierto. El beneficio principal de esto es que mientras los procesos de indexación están ejecutándose, puedes minimizar la ventana principal del programa, pero mantener el diálogo de indexación visible y estacionado a un lado. Esto te permite mantener un ojo en los procesos de indexación mientras haces trabajo en otras aplicaciones. Esta característica no es aplicable a DocFetcher Server. Server Not available in DocFetcher Server
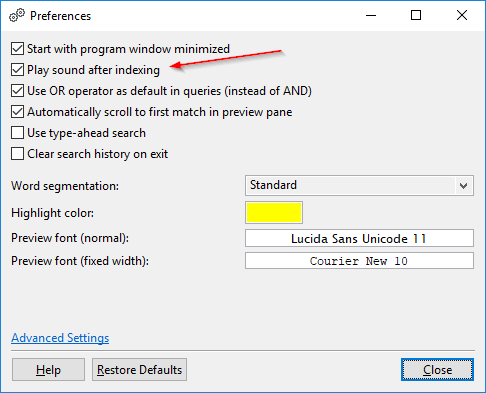
Reproducir un sonido después de indexar: Por defecto, DocFetcher Pro reproduce un sonido de «terminado» después de indexar. Esto se puede desactivar en las preferencias. Esta característica actualmente no está disponible en DocFetcher Server. Server Not available in DocFetcher Server
Indexar texto japonés: DocFetcher tiene una opción llamada «segmentación de palabras» para obtener resultados de búsqueda utilizables al indexar texto chino. DocFetcher Pro tiene una opción adicional de segmentación de palabras para manejar texto japonés. Tanto la segmentación de palabras china como japonesa actualmente no están disponibles en DocFetcher Server. Server Not available in DocFetcher Server