Esta página es una descripción general de todas las características principales de DocFetcher Pro y DocFetcher Server, destinada a aquellos que no están familiarizados con DocFetcher. Si lo está, puede encontrar más útil la página de Comparación y sus subpáginas.
Todas las capturas de pantalla a continuación muestran la interfaz de usuario de DocFetcher Pro. La interfaz web de DocFetcher Server se ve similar y está anidada dentro de una ventana del navegador.
La Interfaz de Usuario
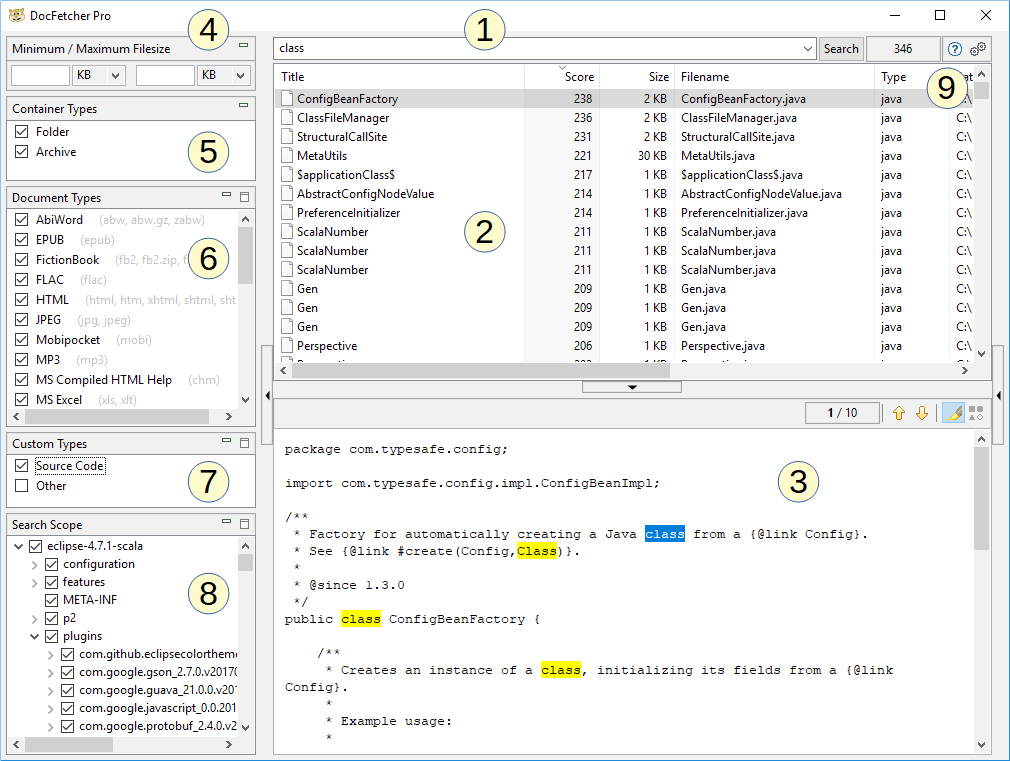
Como se muestra en la captura de pantalla anterior, la ventana principal de DocFetcher Pro consta de las siguientes partes:
- Campo de búsqueda: Ingrese aquí las palabras a buscar.
- Panel de resultados: Los resultados de búsqueda se muestran aquí. Estos son los archivos, carpetas o correos de Outlook que contienen las palabras que ingresó en el campo de búsqueda.
- Panel de vista previa: Muestra una vista previa de solo texto del archivo o correo de Outlook actualmente seleccionado en el panel de resultados. Las coincidencias en el texto están resaltadas.
- Filtro de Tamaño de archivo mínimo/máximo: Los resultados de búsqueda pueden filtrarse por tamaño de archivo mínimo y/o máximo aquí. Free Available in the free DocFetcher Pro Available in DocFetcher Pro Server Not available in DocFetcher Server
- Panel de Tipos de contenedor: Configure aquí si las carpetas y archivos deben incluirse en los resultados de búsqueda. En DocFetcher, las carpetas y archivos no se incluyen en los resultados de búsqueda, solo archivos y correos de Outlook. Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Available in DocFetcher Server
- Panel de Tipos de Documento: Los resultados de búsqueda pueden filtrarse por tipo de archivo aquí.
- Panel de Tipos Personalizados: Una alternativa al panel de Tipos de Documento. Aquí puede definir sus propios tipos de archivo para filtrar los resultados de búsqueda. Las definiciones se basan en la coincidencia de patrones comodín o expresiones regulares contra nombres de archivo. Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Not available in DocFetcher Server
- Panel de Ámbito de Búsqueda: Este panel tiene dos propósitos: Filtrar los resultados de búsqueda por ubicación, y administrar sus «índices», que se explican a continuación. Los índices pueden agregarse, actualizarse y eliminarse. Cada índice corresponde a alguna ubicación buscable en su computadora.
- Varios controles: Los tres controles a la derecha del botón Buscar son: el número de resultados de búsqueda actualmente visibles, un botón para abrir el manual del usuario y un botón para abrir las preferencias del programa.
Sintaxis de Consulta Potente
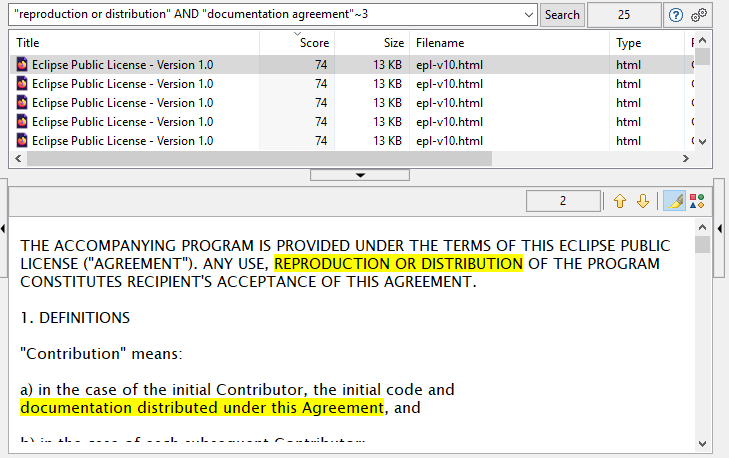
La captura de pantalla anterior muestra un ejemplo de los tipos de consultas de búsqueda complejas que puede ingresar en DocFetcher, DocFetcher Pro y DocFetcher Server. La consulta de ejemplo significa: Encontrar todos los documentos que contengan (1) la frase «reproduction or redistribution», y (2) las palabras «documentation» y «agreement» a lo sumo tres palabras de distancia.
La sintaxis de consulta está basada en el motor de búsqueda subyacente Apache Lucene. Aquí está un resumen rápido de sus características principales:
- Operadores booleanos: (perro OR gato) AND ratón NOT caballo
- Búsqueda de frases, es decir, encontrar palabras en un orden específico: "perro gato ratón"
- Términos requeridos: +perro +gato
- Comodines: Caracteres de marcador de posición * y ? para coincidir con “cero o más” caracteres y “exactamente un” carácter, respectivamente. Ejemplos:
- luc? coincide con lucy, luca, …
- luc* coincide con luc, lucy, luck, lucene, …
- *ene* coincide con lucene, energy, generator, …
- Búsqueda difusa, es decir, encontrar palabras que son similares a una palabra dada. Por ejemplo, buscar roam~ mostrará documentos que contengan palabras como foam y roams.
- Búsqueda de proximidad, es decir, encontrar palabras que no estén a más de un cierto número de palabras de distancia. Ejemplo: "documentation agreement"~3
Búsqueda Basada en Índices
Búsqueda basada en índices: DocFetcher, DocFetcher Pro y DocFetcher Server buscan palabras en el nombre de archivo y contenido de archivos, así como en los campos y cuerpo de correos de Outlook. Sin embargo, por motivos de eficiencia, la búsqueda se ejecuta en los llamados índices, en lugar de en los archivos y correos directamente. Un índice es esencialmente un diccionario donde el programa puede buscar rápidamente para cualquier palabra dada qué archivos o correos contienen esa palabra.
Compromiso: búsqueda rápida y creación de índices: La búsqueda basada en índices es una gran idea porque es órdenes de magnitud más rápida que buscar sin índices: DocFetcher, DocFetcher Pro y DocFetcher Server típicamente pueden encontrar miles de archivos coincidentes en menos de un segundo. La principal desventaja es que los índices deben crearse primero — un proceso conocido como indexación — y esto puede tomar algún tiempo dependiendo del número total de archivos y correos, y sus tamaños individuales.
Indexación rápida y filosofía de «indexar solo lo que necesita»: La desventaja de tener que crear un índice se alivia por el hecho de que la indexación en DocFetcher, DocFetcher Pro y DocFetcher Server es bastante rápida: 200 archivos por minuto es una velocidad de indexación bastante normal. Además, los tres programas siguen una filosofía de «indexar solo lo que necesita»: De fábrica, nada en su computadora está indexado, y depende completamente de usted decidir qué se indexa. Esto contrasta con otros programas de búsqueda que de fábrica desperdician una tonelada de tiempo y poder computacional para indexar básicamente todo, ya que no confían en que usted decida por su cuenta. Sin mencionar las implicaciones de privacidad de este enfoque de «indexar todo»…
Creación de índice vs. actualización de índice: Por último pero no menos importante, indexar una carpeta particular generalmente solo consume tiempo la primera vez, si acaso. Después, cada vez que ejecute una llamada actualización de índice, el programa será lo suficientemente inteligente para indexar solo archivos nuevos y modificados, omitiendo todo lo demás. En la práctica, generalmente solo un número relativamente pequeño de archivos habrá sido agregado o modificado, por lo que una actualización de índice generalmente toma poco tiempo.
Creando Índices
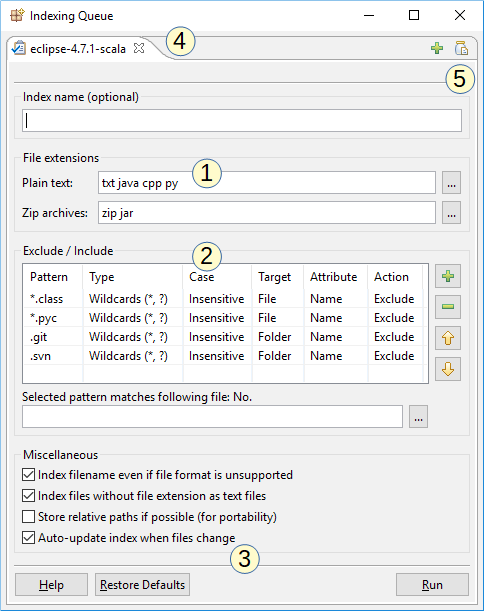
La captura de pantalla anterior muestra el diálogo de indexación de DocFetcher Pro. Este es el diálogo de configuración que ve al crear un nuevo índice. Características notables:
- Extensiones de texto plano y zip personalizables: Las extensiones de archivo por las cuales el programa reconoce archivos de texto plano y archivos zip pueden personalizarse. Personalizar las extensiones de archivos de texto plano es útil al tratar con código fuente.
- Reglas de inclusión y exclusión: Puede definir reglas para incluir o excluir ciertos archivos basadas en coincidencia de patrones comodín o expresiones regulares. Esta tabla también existe en DocFetcher, pero los comodines y la regla de inclusión solo están disponibles en DocFetcher Pro y DocFetcher Server. Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Available in DocFetcher Server
- Actualización automática de índices: Si la casilla «Actualizar índice automáticamente» está marcada, el programa vigilará la carpeta indexada para cambios de archivos y actualizará el índice automáticamente cuando se detecte un cambio.
- Cola de indexación: Múltiples trabajos de indexación pueden ponerse en cola, con cada trabajo en una pestaña separada.
- Guardar y cargar configuraciones de indexación: Este botón de «tarro» abre un menú para guardar y cargar configuraciones de indexación. Esto es útil si necesita definir muchas reglas de inclusión y exclusión. Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Not available in DocFetcher Server
Formatos de Documento Compatibles
- AbiWord (abw, abw.gz, zabw)
- EPUB (epub)
- FictionBook (fb2, fbz, fb2.zip) Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Available in DocFetcher Server
- Metadatos FLAC (flac)
- HTML (html, xhtml, …)
- Metadatos JPEG Exif (jpg, jpeg)
- Metadatos MP3 (mp3)
- Microsoft Compiled HTML Help (chm)
- Microsoft Office anterior a 2007 (doc, xls, ppt, …)
- Microsoft Office 2007 y más reciente (docx, xlsx, pptx, …)
- Microsoft Outlook OST (ost) * Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Available in DocFetcher Server
- Microsoft Outlook PST (pst) *
- Microsoft Visio (vsd, vss, vst, vsw)
- Mobipocket (mobi) — el soporte es actualmente experimental Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Available in DocFetcher Server
- OpenDocument (odt, ods, odg, odp, …)
- Portable Document Format (pdf)
- Texto Plano (extensiones personalizables)
- Rich Text Format (rtf)
- Scalable Vector Graphics (svg)
Para cualquier formato de archivo no incluido en la lista anterior, al menos el nombre de archivo puede indexarse. Además, cualquier formato de archivo identificable por una extensión de archivo específica puede indexarse forzosamente como texto plano, ya que las extensiones de archivos de texto plano son personalizables.
* Limitaciones del soporte de archivos PST y OST
Sin vista previa de correo: Por razones técnicas, ni DocFetcher ni DocFetcher Pro ni DocFetcher Server pueden abrir correos en los resultados de búsqueda con Outlook. Los correos solo pueden mostrarse en el panel de vista previa de solo texto del programa. La capacidad de abrir correos en Outlook puede agregarse en una futura versión principal de DocFetcher Pro (v2.0 o posterior). No puede implementarse en DocFetcher Server ya que la instancia de Outlook del usuario y el archivo PST u OST que contiene el correo residen en computadoras potencialmente diferentes.
Prefiera PST a OST: Aunque DocFetcher Pro y DocFetcher Server pueden leer archivos OST hasta cierto punto, tenga en cuenta que los archivos OST son en realidad solo archivos de caché donde Outlook almacena temporalmente alguna porción de los datos de una cuenta en línea para uso sin conexión. Por lo tanto, si indexa archivos OST, encontrará que muchos correos y archivos adjuntos de correo que esperaría ver simplemente no están ahí. Los archivos PST son lo que Outlook usa para el almacenamiento completo y a largo plazo de correos, por lo que siempre prefiera indexar archivos PST a indexar archivos OST cuando sea posible. Para más información sobre archivos PST y OST, e instrucciones sobre cómo exportar a archivos PST, vea esta página de Microsoft.
Archivos PST y OST grandes: Para indexar un archivo PST u OST, la aplicación tiene que cargar todo el archivo en la RAM. Por lo tanto, indexar archivos PST u OST que son más grandes que la cantidad disponible de RAM (p. ej., archivo PST de 30 GB vs. 16 GB de RAM) no está soportado, y los intentos de hacerlo harán que la aplicación se bloquee. Para lidiar con este problema, puede excluir el archivo PST u OST grande de la indexación, o actualizar su RAM. En caso de actualización de RAM, tenga en cuenta que la cantidad total de RAM necesaria es mayor que el archivo PST u OST, debido al hecho de que el sistema operativo y otros procesos ocupan algo de esa RAM.
Descargo de responsabilidad sobre indexación de mejor esfuerzo
Como virtualmente todo software de búsqueda, DocFetcher, DocFetcher Pro y DocFetcher Server soportan los varios formatos de archivo listados anteriormente en base de mejor esfuerzo. Esto significa, por ejemplo, si trata de indexar 10,000 archivos, entonces el software puede indexar exitosamente solo 9,500 archivos (es decir, 95%), mientras falla en los 500 archivos restantes. Por supuesto, la tasa de éxito real depende de su conjunto de datos.
Además, incluso si un archivo particular se indexa exitosamente, el software puede fallar al extraer algo de texto en él, especialmente al tratar con formatos de archivo antiguos como «doc» o «xls». Por ejemplo, puede fallar al extraer algunos comentarios de celda o metadatos de archivos antiguos de Excel.
En cualquier caso, DocFetcher Pro y DocFetcher Server muy probablemente harán un mejor trabajo indexando archivos que el DocFetcher más antiguo.
Si ve una tasa de falla particularmente alta durante la indexación, por favor reporte el problema, con algunos archivos de prueba adjuntos. Sin embargo, no hay garantía de que el problema pueda resolverse.
Formatos de Archivo Compatibles
- Archivos 7z (7z), hasta la versión v0.3 del formato 7z
- Archivos 7z (7z), hasta la versión v0.4 del formato 7z (desde 7-Zip 9.34, del 2014-11-23) Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Available in DocFetcher Server
- Archivos Rar (rar) — formato RAR 5.0 no soportado
- Archivos Tar y Tar.*:
- tar, tar.gz, tgz, tar.bz2, tb2, tbz
- tbz2, tar.lzma, tlz, tar.xz, txz, tar.z, tz Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Available in DocFetcher Server
- Archivos Zip (extensiones personalizables)
Otras Características Notables
Multiplataforma: DocFetcher, DocFetcher Pro y DocFetcher Server pueden ejecutarse en Windows, Linux y macOS. Además, DocFetcher Server puede accederse desde cualquier computadora de escritorio con una versión actualizada de Chrome, Firefox, Safari o Edge instalada.
Versión portátil: Los paquetes de DocFetcher Pro para Windows, Linux y macOS vienen cada uno en una versión portátil y no portátil. La versión portátil es útil en que le permite empaquetar DocFetcher Pro portátil, sus índices y los documentos indexados, para ser usado de varias maneras:
- Puede llevar este paquete en una unidad USB.
- Puede archivarlo en algún medio de respaldo.
- Puede ponerlo en un volumen encriptado.
- Puede ponerlo en una unidad en la nube y sincronizarlo entre computadoras.
Tenga en cuenta que redistribuir tales paquetes portátiles a otros usuarios no está permitido con DocFetcher Pro, ya que cada copia comprada está vinculada a un solo usuario. (Cada usuario receptor tendría que comprar su propia copia.) La redistribución está permitida con el DocFetcher de código abierto, sin embargo.
Soporte Unicode: DocFetcher, DocFetcher Pro y DocFetcher Server vienen con soporte Unicode sólido como una roca para todos los formatos principales, incluyendo Microsoft Office, OpenDocument, PDF, HTML, RTF y archivos de texto plano.
Indexación de unidades de red: DocFetcher, DocFetcher Pro y DocFetcher Server pueden indexar unidades de red así como unidades en la nube. Más generalmente, si una estructura de datos puede montarse como algo que parece un sistema de archivos en el OS, entonces los tres programas pueden indexarlo.
Detección de pares HTML: Durante la indexación, DocFetcher, DocFetcher Pro y DocFetcher Server detectan pares de archivos HTML (p. ej., un archivo llamado ejemplo.html y una carpeta llamada ejemplo_files), y tratan cada par como un solo documento. Esta característica puede parecer bastante inútil al principio, pero resultó que esto aumenta dramáticamente la calidad de los resultados de búsqueda cuando está tratando con archivos HTML, ya que todo el «desorden» dentro de las carpetas HTML desaparece de los resultados.