Ta strona to przegląd wszystkich głównych funkcji DocFetcher Pro i DocFetcher Server, przeznaczony dla osób nieznających DocFetcher. Jeśli znasz go już, być może strona Porównanie i jej podstrony będą dla Ciebie bardziej pomocne.
Wszystkie zrzuty ekranu poniżej pokazują interfejs użytkownika DocFetcher Pro. Interfejs internetowy DocFetcher Server wygląda podobnie i jest zagnieżdżony w oknie przeglądarki.
Interfejs użytkownika
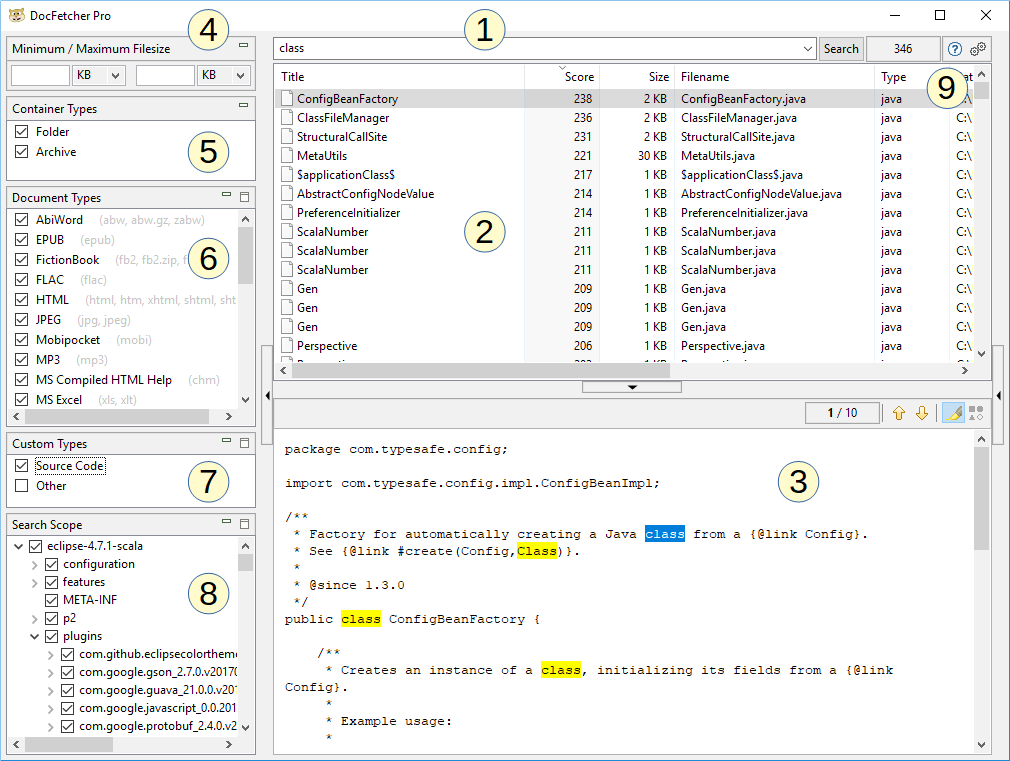
Jak pokazano na zrzucie ekranu powyżej, główne okno DocFetcher Pro składa się z następujących części:
- Pole wyszukiwania: Tutaj wpisz słowa do wyszukania.
- Panel wyników: Tutaj wyświetlane są wyniki wyszukiwania. To są pliki, foldery lub e-maile Outlook zawierające słowa, które wpisałeś w polu wyszukiwania.
- Panel podglądu: Pokazuje podgląd tekstowy aktualnie wybranego w panelu wyników pliku lub e-maila Outlook. Dopasowania w tekście są podświetlone.
- Filtr Minimalny/maksymalny rozmiar pliku: Wyniki wyszukiwania mogą być tutaj filtrowane według minimalnego i/lub maksymalnego rozmiaru pliku. Free Available in the free DocFetcher Pro Available in DocFetcher Pro Server Not available in DocFetcher Server
- Panel Typy pojemników: Ustaw tutaj, czy foldery i archiwa powinny być uwzględnione w wynikach wyszukiwania. W DocFetcher foldery i archiwa nie są uwzględniane w wynikach wyszukiwania, tylko pliki i e-maile Outlook. Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Available in DocFetcher Server
- Panel Typy dokumentów: Wyniki wyszukiwania mogą być tutaj filtrowane według typu pliku.
- Panel Typy niestandardowe: Alternatywa dla panelu Typy dokumentów. Tutaj możesz zdefiniować własne typy plików do filtrowania wyników wyszukiwania. Definicje opierają się na dopasowywaniu wzorców wieloznacznych lub wyrażeń regularnych do nazw plików. Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Not available in DocFetcher Server
- Panel Zakres wyszukiwania: Ten panel ma dwa cele: filtrowanie wyników wyszukiwania według lokalizacji i zarządzanie „indeksami”, które są wyjaśnione poniżej. Indeksy mogą być dodawane, aktualizowane i usuwane. Każdy indeks odpowiada pewnej lokalizacji, którą można przeszukiwać na komputerze.
- Różne kontrolki: Trzy kontrolki po prawej stronie przycisku Szukaj to: liczba aktualnie widocznych wyników wyszukiwania, przycisk do otwarcia instrukcji obsługi i przycisk do otwarcia preferencji programu.
Potężna składnia zapytań
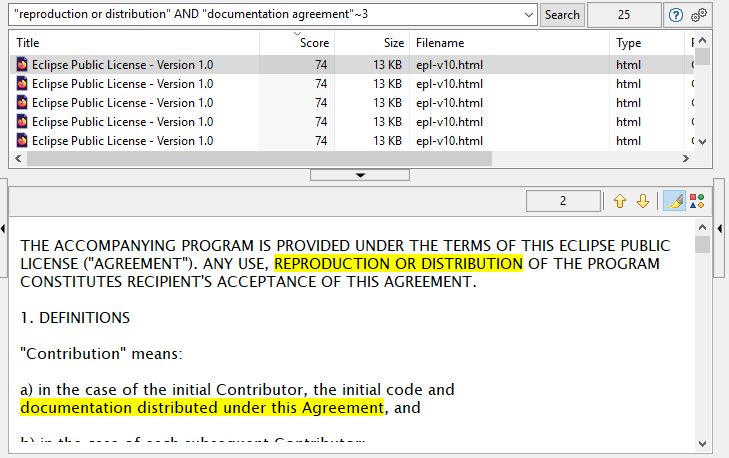
Powyższy zrzut ekranu pokazuje przykład złożonych zapytań wyszukiwania, które możesz wprowadzić w DocFetcher, DocFetcher Pro i DocFetcher Server. Przykładowe zapytanie oznacza: Znajdź wszystkie dokumenty zawierające (1) frazę „reproduction or redistribution” i (2) słowa „documentation” i „agreement” oddzielone co najwyżej trzema słowami.
Składnia zapytań jest napedzana przez podstawową wyszukiwarkę Apache Lucene. Oto krótkie ominięcie jej głównych funkcji:
- Operatory logiczne: (pies OR kot) AND mysz NOT koń
- Wyszukiwanie fraz, tj. znajdowanie słów w określonej kolejności: "pies kot mysz"
- Wymagane terminy: +pies +kot
- Znaki wieloznaczne: Znaki zastępujące * i ? do dopasowania odpowiednio «zero lub więcej» znaków i «dokładnie jednego» znaku. Przykłady:
- luc? dopasowuje lucy, luca, …
- luc* dopasowuje luc, lucy, luck, lucene, …
- *ene* dopasowuje lucene, energy, generator, …
- Wyszukiwanie rozmyte, tj. znajdowanie słów podobnych do podanego słowa. Na przykład wyszukiwanie roam~ znajdzie dokumenty zawierające słowa takie jak foam i roams.
- Wyszukiwanie zbliżeniowe, tj. znajdowanie słów oddalonych o nie więcej niż określoną liczbę słów. Przykład: "documentation agreement"~3
Wyszukiwanie oparte na indeksach
Wyszukiwanie oparte na indeksach: DocFetcher, DocFetcher Pro i DocFetcher Server wyszukują słowa w nazwach plików i treści plików, a także w polach i treści e-maili Outlook. Jednak ze względu na efektywność wyszukiwanie odbywa się na tak zwanych indeksach, a nie bezpośrednio na plikach i e-mailach. Indeks to zasadniczo słownik, w którym program może szybko sprawdzić dla każdego słowa, które pliki lub e-maile zawierają to słowo.
Kompromis: szybkie wyszukiwanie i tworzenie indeksów: Wyszukiwanie oparte na indeksach to świetny pomysł, ponieważ jest rzędy wielkości szybsze niż wyszukiwanie bez indeksów: DocFetcher, DocFetcher Pro i DocFetcher Server mogą zwykle znaleźć tysiące pasujących plików w mniej niż sekundę. Główną wadą jest to, że indeksy muszą być najpierw utworzone — proces znany jako indeksowanie — i może to zająć pewien czas w zależności od całkowitej liczby plików i e-maili oraz ich indywidualnych rozmiarów.
Szybkie indeksowanie i filozofia „indeksuj tylko to, czego potrzebujesz”: Wada konieczności tworzenia indeksu jest łagodzona przez fakt, że indeksowanie w DocFetcher, DocFetcher Pro i DocFetcher Server jest dość szybkie: 200 plików na minutę to całkiem normalna prędkość indeksowania. Ponadto te trzy programy przestrzegają filozofii „indeksuj tylko to, czego potrzebujesz”: Fabrycznie nic na komputerze nie jest indeksowane i to ty decydujesz całkowicie, co ma być indeksowane. Jest to w przeciwieństwie do innych oprogramowań wyszukiwania, które fabrycznie marnują mnimo czasu i mocy obliczeniowej na indeksowanie w zasadzie wszystkiego, gdyż nie ufają ci w podejmowaniu własnych decyzji. Nie wspominając o konsekwencjach prywatności tego podejścia „indeksuj wszystko”…
Tworzenie indeksu vs. aktualizacja indeksu: Na koniec, indeksowanie konkretnego folderu jest zwykle czasochłonne tylko za pierwszym razem, jeśli w ogóle. Następnie, gdy uruchamiasz tak zwaną aktualizację indeksu, program będzie na tyle inteligentny, że zaindeksuje tylko nowe i zmodyfikowane pliki, pomijając wszystko inne. W praktyce zwykle tylko stosunkowo mała liczba plików zostanie dodana lub zmodyfikowana, więc aktualizacja indeksu zazwyczaj zajmuje mało czasu.
Tworzenie indeksów
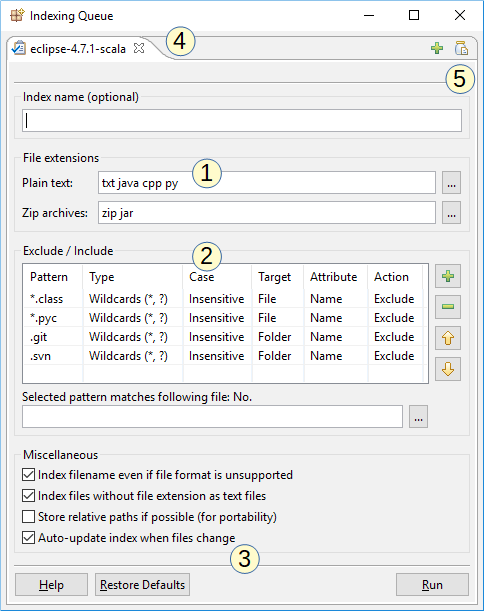
Powyższy zrzut ekranu pokazuje okno dialogowe indeksowania DocFetcher Pro. To jest okno konfiguracyjne, które widzisz podczas tworzenia nowego indeksu. Godną uwagi funkcje:
- Konfigurowalne rozszerzenia zwykłego tekstu i zip: Rozszerzenia plików, przez które program rozpoznaje pliki zwykłego tekstu i archiwa zip, mogą być konfigurowane. Konfigurowanie rozszerzeń plików zwykłego tekstu jest przydatne przy pracy z kodem źródłowym.
- Reguły włączania i wykluczania: Możesz zdefiniować reguły włączania lub wykluczania określonych plików na podstawie dopasowania wzorców wieloznacznych lub wyrażeń regularnych. Ta tabela istnieje także w DocFetcher, ale wzorce wieloznaczne i reguła włączania są dostępne tylko w DocFetcher Pro i DocFetcher Server. Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Available in DocFetcher Server
- Automatyczne aktualizowanie indeksów: Jeśli pole „Automatycznie aktualizuj indeks” jest zaznaczone, program będzie obserwować indeksowany folder pod kątem zmian plików i automatycznie aktualizować indeks po wykryciu zmiany.
- Kolejka indeksowania: Wiele zadań indeksowania może być ustawionych w kolejce, z każdym zadaniem na oddzielnej karcie.
- Zapisywanie i ładowanie ustawień indeksowania: Ten przycisk „słoika” otwiera menu do zapisywania i ładowania ustawień indeksowania. Przyda się to, jeśli musisz zdefiniować dużo reguł włączania i wykluczania. Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Not available in DocFetcher Server
Obsługiwane formaty dokumentów
- AbiWord (abw, abw.gz, zabw)
- EPUB (epub)
- FictionBook (fb2, fbz, fb2.zip) Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Available in DocFetcher Server
- FLAC metadata (flac)
- HTML (html, xhtml, …)
- JPEG Exif metadata (jpg, jpeg)
- MP3 metadata (mp3)
- Microsoft Compiled HTML Help (chm)
- Microsoft Office pre-2007 (doc, xls, ppt, …)
- Microsoft Office 2007 and newer (docx, xlsx, pptx, …)
- Microsoft Outlook OST (ost) * Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Available in DocFetcher Server
- Microsoft Outlook PST (pst) *
- Microsoft Visio (vsd, vss, vst, vsw)
- Mobipocket (mobi) — support is currently experimental Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Available in DocFetcher Server
- OpenDocument (odt, ods, odg, odp, …)
- Portable Document Format (pdf)
- Plain Text (customizable extensions)
- Rich Text Format (rtf)
- Scalable Vector Graphics (svg)
Dla każdego formatu pliku nie zawartego w powyższej liście przynajmniej nazwa pliku może być indeksowana. Również każdy format pliku identyfikowany przez określone rozszerzenie może być przymusowo indeksowany jako zwykły tekst, gdyż rozszerzenia plików zwykłego tekstu są konfigurowalne.
* Ograniczenia obsługi plików PST i OST
Brak podglądu e-maili: Ze względów technicznych ani DocFetcher, ani DocFetcher Pro, ani DocFetcher Server nie mogą otwierać e-maili w wynikach wyszukiwania za pomocą Outlook. E-maile mogą być pokazane tylko w panelu podglądu tekstowego programu. Możliwość otwierania e-maili w Outlook może zostać dodana w przyszłej głównej wersji DocFetcher Pro (v2.0 lub późniejszej). Nie może być zaimplementowana w DocFetcher Server, ponieważ instancja Outlook użytkownika i plik PST lub OST zawierający e-mail znajdują się potencjalnie na różnych komputerach.
Preferuj PST nad OST: Choć DocFetcher Pro i DocFetcher Server mogą odczytywać pliki OST do pewnego stopnia, należy ostrzec, że pliki OST to w rzeczywistości tylko pliki pamięci podręcznej, w których Outlook tymczasowo przechowuje część danych z konta online do użytku offline. Tak więc, jeśli indeksujesz pliki OST, stwierdzisz, że wiele e-maili i załączników e-mail, które spodziewasz się zobaczyć, po prostu tam nie ma. Pliki PST to to, czego Outlook używa do pełnego, długoterminowego przechowywania e-maili, więc zawsze preferuj indeksowanie plików PST nad indeksowaniem plików OST, gdzie to możliwe. Aby uzyskać więcej informacji o plikach PST i OST oraz instrukcje dotyczące eksportowania do plików PST, zobacz tę stronę Microsoft.
Duże pliki PST i OST: Aby zaindeksować plik PST lub OST, aplikacja musi załadować cały plik do pamięci RAM. Tak więc indeksowanie plików PST lub OST większych niż dostępna ilość pamięci RAM (np. 30 GB plik PST vs. 16 GB RAM) nie jest obsługiwane, a próby tego doprowadzą do awarii aplikacji. Aby poradzić sobie z tym problemem, możesz albo wykluczyć duży plik PST lub OST z indeksowania, albo zaktualizować pamięć RAM. W przypadku aktualizacji RAM, pamiętaj, że całkowita ilość potrzebnej pamięci RAM jest większa niż plik PST lub OST, ze względu na fakt, że system operacyjny i inne procesy zajmują część tej pamięci.
Zastrzeżenie o indeksowaniu w oparciu o najlepsze starania
Jak praktycznie całe oprogramowanie wyszukiwania, DocFetcher, DocFetcher Pro i DocFetcher Server obsługują różne formaty plików wymienione powyżej na zasadzie najlepszych starań. Oznacza to, na przykład, że jeśli spróbujesz zaindeksować 10 000 plików, oprogramowanie może pomyślnie zaindeksować tylko 9 500 plików (tj. 95%), nie radząc sobie z pozostałymi 500 plikami. Oczywiście rzeczywisty wskaźnik sukcesu zależy od Twojego zbioru danych.
Ponadto, nawet jeśli konkretny plik zostanie pomyślnie zaindeksowany, oprogramowanie może nie udać się wydobyć części tekstu z niego, szczególnie podczas pracy ze starymi formatami plików, takimi jak „doc” lub „xls”. Na przykład może nie udać się wydobyć niektórych komentarzy komórki lub metadanych z zabytkowych plików Excel.
W każdym przypadku DocFetcher Pro i DocFetcher Server prawdopodobnie lepiej poradzą sobie z indeksowaniem plików niż starszy DocFetcher.
Jeśli widzisz szczególnie wysoki wskaźnik niepowodzeń podczas indeksowania, koniecznie zgłoś problem, z niektórymi plikami testowymi w załączeniu. Jednak nie ma gwarancji, że problem może zostać rozwiązany.
Obsługiwane formaty archiwum
- Archiwa 7z (7z), do wersji v0.3 formatu 7z
- Archiwa 7z (7z), do wersji v0.4 formatu 7z (od 7-Zip 9.34, z 2014-11-23) Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Available in DocFetcher Server
- Archiwa Rar (rar) — format RAR 5.0 nie obsługiwany
- Archiwa Tar i Tar.*:
- tar, tar.gz, tgz, tar.bz2, tb2, tbz
- tbz2, tar.lzma, tlz, tar.xz, txz, tar.z, tz Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Available in DocFetcher Server
- Archiwa Zip (konfigurowalne rozszerzenia)
Inne godną uwagi funkcje
Wieloplatformowość: DocFetcher, DocFetcher Pro i DocFetcher Server mogą być uruchamiane na Windows, Linux i macOS. Ponadto DocFetcher Server może być używany z każdego komputera stacjonarnego z aktualną wersją Chrome, Firefox, Safari lub Edge zainstalowaną.
Wersja przenośna: Pakiety DocFetcher Pro dla Windows, Linux i macOS przychodzi w wersji przenośnej i nieprzenośnej. Wersja przenośna jest przydatna tym, że pozwala ci spakowac przenośny DocFetcher Pro, jego indeksy i indeksowane dokumenty, do użycia na różne sposoby:
- Możesz nosić ten pakiet na dysku USB.
- Możesz go zarchiwizować na jakimś nośniku kopii zapasowej.
- Możesz go umieścić w zaszyfrowanym woluminie.
- Możesz go umieścić w dysku chmurowym i synchronizować między komputerami.
Proszę pamiętać, że redystrybucja takich przenośnych pakietów innym użytkownikom nie jest dozwolona z DocFetcher Pro, gdyż każda zakupiona kopia jest związana z jednym użytkownikiem. (Każdy odbierający użytkownik musiałby kupić własną kopię.) Redystrybucja jest dozwolona z open-source DocFetcher, jednak.
Obsługa Unicode: DocFetcher, DocFetcher Pro i DocFetcher Server są wyposażone w solidną obsługę Unicode dla wszystkich głównych formatów, w tym Microsoft Office, OpenDocument, PDF, HTML, RTF i plików zwykłego tekstu.
Indeksowanie dysków sieciowych: DocFetcher, DocFetcher Pro i DocFetcher Server mogą indeksować dyski sieciowe, a także dyski chmurowe. Ogólnie mówiąc, jeśli struktura danych może być zamontowana jako coś, co wygląda jak system plików w systemie operacyjnym, to wszystkie trzy programy mogą ją indeksować.
Wykrywanie par HTML: Podczas indeksowania DocFetcher, DocFetcher Pro i DocFetcher Server wykrywają pary plików HTML (np. plik o nazwie cos.html i folder o nazwie cos_files), i traktują każdą parę jako pojedynczy dokument. Ta funkcja może wydawać się raczej bezsługa na początku, ale okazało się, że dramatycznie zwiększa jakość wyników wyszukiwania podczas pracy z plikami HTML, ponieważ wszystkie „bałagan” wewnątrz folderów HTML znika z wyników.