< terug naar bovenliggende pagina
Herziening van de Patroontabel
De patroontabel in het indexeerdialoog van DocFetcher Pro en de patroontabel in het indexeervenster van DocFetcher Server verschillen van die in DocFetcher op de volgende manieren:
- Naast reguliere expressies kun je de minder krachtige, maar ook veel eenvoudigere jokertekens * en ? gebruiken om vergelijkingsregels te schrijven. Het jokerteken * is een plaatshouder voor nul of meer tekens, terwijl het jokerteken ? een plaatshouder is voor precies één teken.
- Een nieuwe “Opnemen” actie naast de “Uitsluiten” actie.
- De “Detecteer mime-type” actie is verdwenen. Als je bestanden zonder bestandsextensie als tekstbestanden wilt indexeren, gebruik dan het aankruisvakje met dezelfde beschrijving onder de patroontabel.
- Vergelijking kan hoofdlettergevoelig of hoofdletteronafhankelijk zijn. In DocFetcher daarentegen is vergelijking altijd hoofdlettergevoelig.
- Vergelijking kan niet alleen worden uitgevoerd tegen gewone bestanden, maar ook tegen mappen en archiefbestanden.
- Op Windows, wanneer regels worden vergeleken met bestandspaden, zullen deze laatste het teken \ gebruiken als padscheidingsteken, niet het teken /. Voorbeeld: C:\Pad\Naar\Bestand.docx, in plaats van C:/Pad/Naar/Bestand.docx.
Als gevolg hiervan ziet de patroontabel in DocFetcher Pro er zo uit:
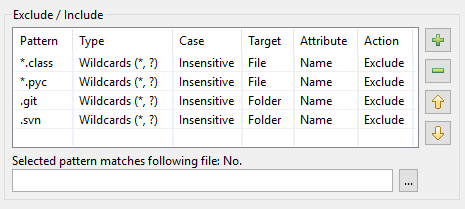
De patroontabel in DocFetcher Server ziet er hetzelfde uit, maar de “Geselecteerd patroon komt overeen met volgend bestand” test-widget onder de tabel is momenteel niet beschikbaar. Server Not available in DocFetcher Server
Klik hier voor een gedetailleerde bespreking van de patroontabel in DocFetcher, DocFetcher Pro en DocFetcher Server.
Zo kwam de herziening van de patroontabel in DocFetcher Pro en DocFetcher Server tot stand. Laten we vanaf het begin beginnen: In het indexeerdialoog van DocFetcher is er een patroontabel voor het uitvoeren van bepaalde acties op bestanden die overeenkomen met bepaalde patronen tijdens het indexeren:
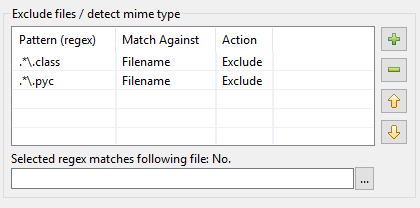
De patronen moeten zogenaamde reguliere expressies zijn, en wat betreft acties zijn er twee beschikbaar in DocFetcher: Het uitsluiten van het overeenkomende bestand van indexering, en “mime-type detectie”, d.w.z. proberen de juiste manier te raden om het overeenkomende bestand te parseren op basis van de inhoud van het bestand in plaats van op basis van de bestandsnaam. Tot zover, zo goed. In de praktijk blijkt echter dat bovenstaande implementatie een aantal problemen heeft:
- Very few people know how to write regular expressions.
- Sometimes one wants to index only certain files, and not needlessly waste indexing time on anything else. For instance, index only “txt” files and nothing else. DocFetcher can actually do this, but it involves some fairly advanced regular expression trickery.
- Soms wil men alle bestanden die overeenkomen met een bepaald patroon uitsluiten van indexering, behalve alle bestanden die overeenkomen met een bepaald ander patroon. Bijvoorbeeld, alle PDF-bestanden uitsluiten van indexering, behalve PDF-bestanden waarvan de naam begint met “rapport_”. Ook dit vereist in DocFetcher geavanceerd gebruik van reguliere expressies.
- Over het algemeen is mime-type detectie vrij nutteloos omdat: (1) De bestandsextensie is bijna altijd correct en daarom in de meeste gevallen alles wat nodig is om het bestandsformaat te achterhalen. (2) Wanneer de bestandsextensie niet correct is en mime-type detectie nodig is, blijkt deze laatste toch niet bijzonder betrouwbaar te zijn. (3) Niemand neemt de moeite om en/of weet hoe vergelijkingsregels te schrijven voor die zeldzame gevallen waar mime-type detectie daadwerkelijk nodig zou zijn. Echter, in de context van DocFetcher blijkt dat mime-type detectie wel één belangrijke toepassing heeft: Het programma bestanden zonder bestandsextensie als platte tekstbestanden laten behandelen, bijvoorbeeld bestanden genaamd README. Echter echter, om dit voor elkaar te krijgen moet men deze obscure reguliere expressie schrijven: [^.]*
- Mime-type detectie kan er niet in slagen een bestand als platte tekst te identificeren als het bestand binaire gegevens bevat.
- Vanwege het feit dat de draagbare versie van DocFetcher op alle ondersteunde platforms moet draaien, gebruiken bestandspaden bij het vergelijken van regels altijd het teken / als padscheidingsteken, zelfs op Windows, wat vrij contra-intuïtief is voor de meeste Windows-gebruikers.
Kortom, DocFetcher’s patroontabel is een puinhoop, en het herschrijven dat kwam met DocFetcher Pro was een goede gelegenheid om het allemaal op te ruimen:
- Jokertekens werden toegevoegd en zijn ingesteld als standaard zodat nu zelfs gewone stervelingen vergelijkingsregels kunnen schrijven.
- De “Opnemen” actie dekt zowel het geval waar men alleen een specifiek soort bestand wil indexeren, als het geval waar men uitzonderingen op vergelijkingsregels wil definiëren. Zelfs uitzonderingen-op-uitzonderingen zijn nu mogelijk.
- De over het algemeen nutteloze “Detecteer mime-type” actie is verdwenen, en de hoofdtoepassing ervan, het indexeren van bestanden zonder bestandsextensie als tekstbestanden, wordt gedekt door een eenvoudig aankruisvakje onder de patroontabel. En dit aankruisvakje werkt zelfs als het bestand binaire gegevens bevat.
- Het Windows padscheidingsteken probleem is opgelost.
- En wat andere dingen (hoofdlettergevoeligheid en vergelijking tegen bestanden/mappen/archieven) werden er voor de zekerheid bij gedaan.
Laden en Opslaan van Indexeerinstellingen
Opmerking: Deze functie is momenteel alleen beschikbaar in DocFetcher Pro, niet in DocFetcher Server. Server Not available in DocFetcher Server
Het probleem: In DocFetcher moet je elke keer dat je een nieuwe index aanmaakt alle regels in de patroontabel één voor één invoeren. Dit wordt behoorlijk vervelend als je veel van dergelijke regels hebt. Er is gewoon geen manier om ze te laden en op te slaan.
In DocFetcher Pro wordt bovenstaand probleem als volgt opgelost: In de rechterbovenhoek van het indexeerdialoog van DocFetcher Pro zit een onopvallende kleine “pot met document” knop. Door op deze knop te klikken opent een menu met verschillende acties voor het laden en opslaan van indexeerinstellingen:
Door te klikken op “Instellingen opslaan” opent dit dialoog:
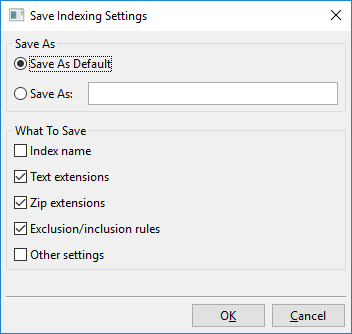
In wezen kun je met dit dialoog ofwel de momenteel zichtbare indexeerinstellingen opslaan in een nieuwe benoemde sleuf, bijvoorbeeld “Mijn Nieuwe Indexeerinstellingen”, of de momenteel zichtbare indexeerinstellingen opslaan als de nieuwe standaard.
Deze standaard wordt “Aangepaste standaardinstellingen” genoemd en wordt automatisch geladen bij het aanmaken van nieuwe indexen. Er is ook een “Fabrieksinstellingen”, wat de standaard is die DocFetcher Pro standaard gebruikt. De benoemde instellingen die je hebt aangemaakt, namelijk “Aangepaste standaardinstellingen” en “Fabrieksinstellingen”, kunnen allemaal worden geladen via het menu dat hierboven wordt getoond.
Om het af te ronden, stelt het menu je ook in staat alle indexeerinstellingen te importeren en exporteren zodat je ze opnieuw kunt gebruiken bij het opzetten van DocFetcher Pro in een nieuwe omgeving.
Andere Belangrijke Verbeteringen
FB2 ondersteuning: DocFetcher Pro en DocFetcher Server hebben ondersteuning voor het e-book formaat FB2. Zip-gecomprimeerde FB2 bestanden, met bestandsextensie fb2.zip of fbz, worden “native” ondersteund, d.w.z. DocFetcher Pro en DocFetcher Server zien elk dergelijk bestand als een enkel bestand in plaats van als een bestand verpakt in een zip-archief.
Experimentele Mobipocket ondersteuning: DocFetcher Pro en DocFetcher Server hebben ondersteuning voor het e-book formaat Mobipocket, met bestandsextensie “mobi”. Merk echter op dat hoewel DocFetcher Pro en DocFetcher Server over het algemeen behoorlijk goed werk leveren bij het extraheren van tekst uit mobi bestanden, ze momenteel ofwel falen om een klein deel van de tekst aan het einde van het bestand te extraheren, of in sommige gevallen volledig falen. Daarom staat Mobipocket ondersteuning voorlopig gemarkeerd als experimenteel.
7z archief ondersteuning voor het huidige v0.4 formaat: DocFetcher kan 7z archieven lezen tot v0.3 van het 7z archief formaat. DocFetcher Pro en DocFetcher Server kunnen ook 7z archieven lezen in het huidige v0.4 formaat. Dit v0.4 formaat werd geïntroduceerd met 7-Zip 9.34, uitgebracht op 2014-11-23.
Uitgebreide tar archief ondersteuning: DocFetcher ondersteunt de volgende tar archief extensies: tar, tar.gz, tgz, tar.bz2, tb2, tbz. DocFetcher Pro en DocFetcher Server ondersteunen daarnaast de volgende tar archief extensies: tbz2, tar.lzma, tlz, tar.xz, txz, tar.z, tz
Indexeren van map- en archief namen: In tegenstelling tot DocFetcher indexeren DocFetcher Pro en DocFetcher Server niet alleen gewone bestanden, maar ook mappen en archiefbestanden — of meer precies, de namen van mappen en archiefbestanden. Dus mappen en archiefbestanden zullen verschijnen in de zoekresultaten van DocFetcher Pro en DocFetcher Server. Er is ook een Containertypen venster aan de linkerkant van het hoofdtoepassingsvenster om mappen en/of archieven uit te sluiten van de zoekresultaten.
MacOS: Daemon voor automatische index bijwerking: DocFetcher en DocFetcher Pro zijn in staat tot automatische index bijwerking, d.w.z. in plaats van index updates handmatig te moeten starten, worden index updates door het programma gestart zodra bestandsveranderingen worden gedetecteerd. Deze functionaliteit is echter alleen beschikbaar terwijl de twee programma’s daadwerkelijk draaien. Wanneer ze niet draaien, is een apart daemon proces nodig om de kloof te vullen. In DocFetcher is de daemon alleen beschikbaar op Windows en Linux, terwijl in DocFetcher Pro deze ook beschikbaar is op macOS. Wat betreft DocFetcher Server, er is geen daemon nodig omdat de server is ontworpen om continu te draaien. Server Not available in DocFetcher Server
Slimmere bestandsnaam indexering: Indexering van bestandsnamen in DocFetcher Pro en DocFetcher Server is slimmer dan in DocFetcher. Bijvoorbeeld, als DocFetcher een bestand genaamd vind_dit_bestand.pdf tegenkomt, ziet het “vind_dit_bestand” als één woord, niet als drie afzonderlijke woorden aan elkaar geregen. Dus DocFetcher zal dit bestand alleen vinden als je letterlijk “vind_dit_bestand” intypt in DocFetcher’s zoekveld. DocFetcher Pro en DocFetcher Server daarentegen zullen het bestand vinden als je “vind_dit_bestand” intypt of een van de drie individuele woorden. Over het algemeen herkennen DocFetcher Pro en DocFetcher Server tekens zoals de underscore als potentiële woordscheidingstekens.

Filename indexing in case of errors: If DocFetcher Pro and DocFetcher Server fail to read the contents of a file due to some error or because of password protection, the filename still gets indexed. In DocFetcher on the other hand, the file is skipped altogether.
Geen fouten bij diep geneste mapstructuren: Bij het proberen te indexeren van diep geneste mapstructuren, zoals C:\map1\map2\...\map99\map100, is DocFetcher geneigd te falen met een “Maphierarchie is te diep” fout. In programmeersjargon wordt dit een “stack overflow” genoemd. DocFetcher Pro en DocFetcher Server daarentegen zijn volledig immuun voor dit soort fouten.
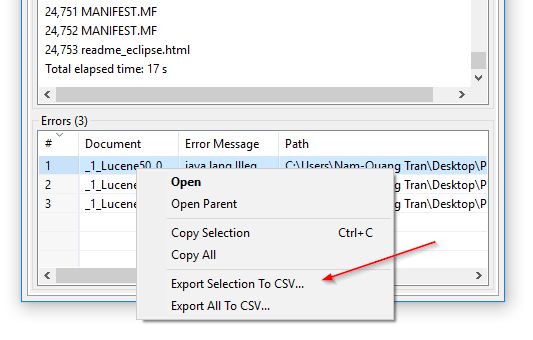
CSV export van indexeerfouten: In DocFetcher Pro kun je de tabel van bestanden die het programma er niet in is geslaagd te lezen tijdens het indexeren exporteren naar een CSV bestand. Dit kan gedaan worden via het contextmenu van de foutentabel, zoals getoond in de volgende schermafbeelding. Deze functie is momenteel niet beschikbaar in DocFetcher Server. Server Not available in DocFetcher Server
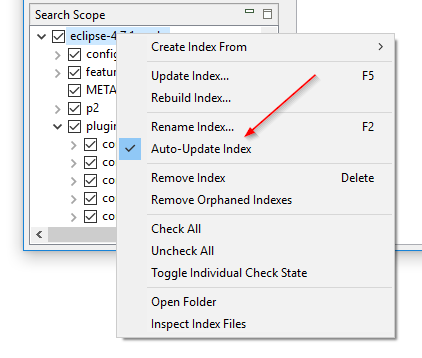
Mapbewaking aan en uit zetten zonder de index opnieuw op te bouwen: DocFetcher’s “Bewaak mappen voor bestandsveranderingen” instelling, ook wel mapbewaking genoemd, is een per-index instelling die wanneer ingeschakeld het programma de index automatisch laat bijwerken wanneer het bestandsveranderingen detecteert in de geïndexeerde map. Het probleem is dat als je deze instelling wilt in- of uitschakelen voor een bepaalde index, je de hele index opnieuw moet opbouwen. In DocFetcher Pro kun je deze instelling in- en uitschakelen zonder de index opnieuw op te bouwen, via het contextmenu van het Zoekbereik venster. Ook is de instelling hernoemd naar “Index automatisch bijwerken”. Vergelijkbare functionaliteit bestaat in DocFetcher Server.
Gelijktijdig zoeken en index herbouwen: In DocFetcher, als je ervoor kiest een index opnieuw op te bouwen, wordt die index niet beschikbaar voor zoeken terwijl het herbouwen bezig is. In DocFetcher Pro en DocFetcher Server daarentegen blijft de index doorzoekbaar tijdens het herbouwen. (Meer precies, een oude kopie van de index blijft doorzoekbaar terwijl de eigenlijke index op de achtergrond wordt herbouwd.)
Windows: Verbeterde afhandeling van UNC paden: In DocFetcher is de afhandeling van UNC paden op Windows ernstig kapot en werd vanaf nul herontworpen in DocFetcher Pro. Het herontwerp werd vervolgens overgebracht naar DocFetcher Server.
Niet-modaal indexeerdialoog: In tegenstelling tot DocFetcher’s indexeerdialoog is die in DocFetcher Pro “niet-modaal”, wat betekent dat het niet gekoppeld is aan het hoofdprogrammavenster en geen invoer naar het hoofdprogrammavenster blokkeert terwijl het open is. Het hoofdvoordeel hiervan is dat terwijl indexeerprocessen draaien, je het hoofdprogrammavenster kunt minimaliseren, maar het indexeerdialoog zichtbaar kunt houden en aan de zijkant kunt parkeren. Dit stelt je in staat om de indexeerprocessen in de gaten te houden terwijl je werk doet in andere toepassingen. Deze functie is niet van toepassing op DocFetcher Server. Server Not available in DocFetcher Server
Een geluid afspelen na indexering: Standaard speelt DocFetcher Pro een “klaar” geluid af na indexering. Dit kan worden uitgeschakeld in de voorkeuren. Deze functie is momenteel niet beschikbaar in DocFetcher Server. Server Not available in DocFetcher Server
Indexeren van Japanse tekst: DocFetcher heeft een zogenaamde “woordsegmentatie” optie om bruikbare zoekresultaten te krijgen bij het indexeren van Chinese tekst. DocFetcher Pro heeft een extra woordsegmentatie optie voor het omgaan met Japanse tekst. Zowel Chinese als Japanse woordsegmentatie zijn momenteel niet beschikbaar in DocFetcher Server. Server Not available in DocFetcher Server