Deze pagina geeft een overzicht van alle belangrijke functies van DocFetcher Pro en DocFetcher Server, bedoeld voor degenen die niet bekend zijn met DocFetcher. Als u dat wel bent, vindt u de Vergelijking-pagina en de subpagina’s daarvan mogelijk nuttiger.
Alle onderstaande schermafbeeldingen tonen de gebruikersinterface van DocFetcher Pro. De webinterface van DocFetcher Server ziet er vergelijkbaar uit en is genest in een browservenster.
De Gebruikersinterface
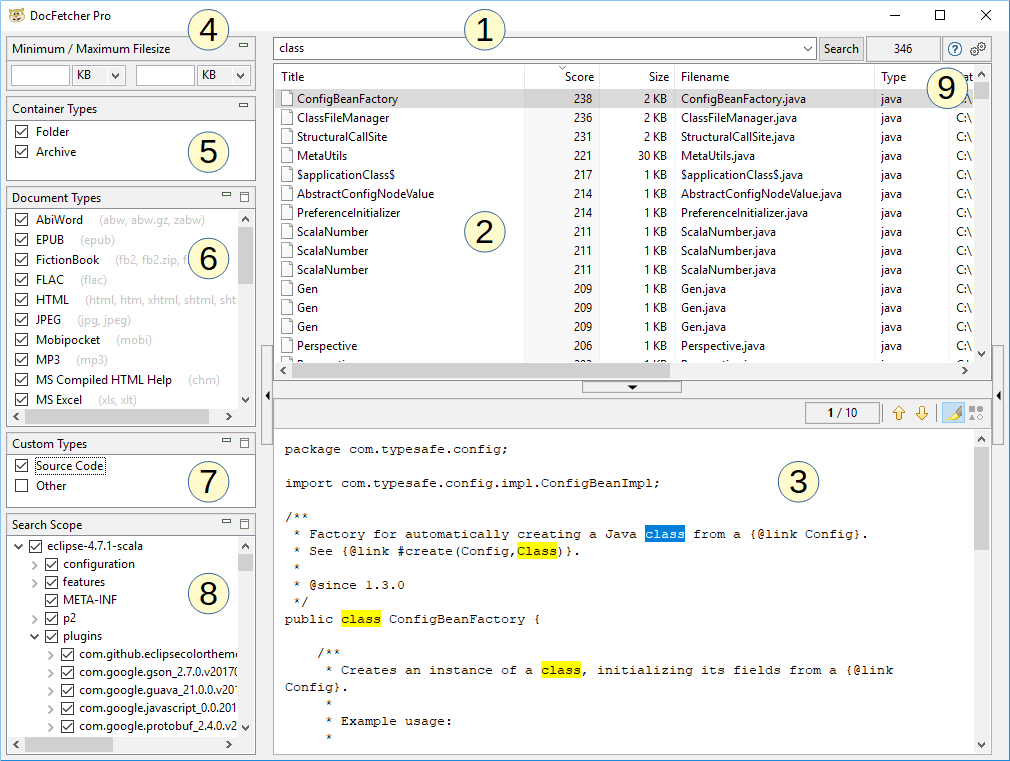
Zoals te zien in de bovenstaande schermafbeelding, bestaat het hoofdvenster van DocFetcher Pro uit de volgende onderdelen:
- Zoekveld: Voer hier de woorden in waarnaar u wilt zoeken.
- Resultatenvenster: Hier worden de zoekresultaten weergegeven. Dit zijn de bestanden, mappen of Outlook-e-mails die de woorden bevatten die u in het zoekveld hebt ingevoerd.
- Voorvertoningsvenster: Toont een tekstvoorvertoning van het bestand of de Outlook-e-mail die momenteel is geselecteerd in het resultatenvenster. Overeenkomsten in de tekst worden gemarkeerd.
- Minimaal/maximum Bestandsgrootte filter: De zoekresultaten kunnen hier worden gefilterd op minimum en/of maximum bestandsgrootte. Free Available in the free DocFetcher Pro Available in DocFetcher Pro Server Not available in DocFetcher Server
- Containertypen venster: Stel hier in of mappen en archieven moeten worden opgenomen in de zoekresultaten. In DocFetcher worden mappen en archieven niet opgenomen in de zoekresultaten, alleen bestanden en Outlook-e-mails. Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Available in DocFetcher Server
- Documenttypen venster: De zoekresultaten kunnen hier worden gefilterd op bestandstype.
- Aangepaste typen venster: Een alternatief voor het Documenttypen venster. Hier kunt u uw eigen bestandstypen definiëren om de zoekresultaten op te filteren. De definities zijn gebaseerd op het matchen van jokertekenpatronen of reguliere expressies tegen bestandsnamen. Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Not available in DocFetcher Server
- Zoekopslag venster: Dit venster heeft twee doelen: Het filteren van de zoekresultaten op locatie, en het beheren van uw “indexen”, die hieronder worden uitgelegd. Indexen kunnen worden toegevoegd, bijgewerkt en verwijderd. Elke index komt overeen met een doorzoekbare locatie op uw computer.
- Diverse bedieningselementen: De drie bedieningselementen rechts van de Zoeken knop zijn: het aantal momenteel zichtbare zoekresultaten, een knop om de handleiding te openen, en een knop om de programmavoorkeuren te openen.
Krachtige Zoekopdracht-syntaxis
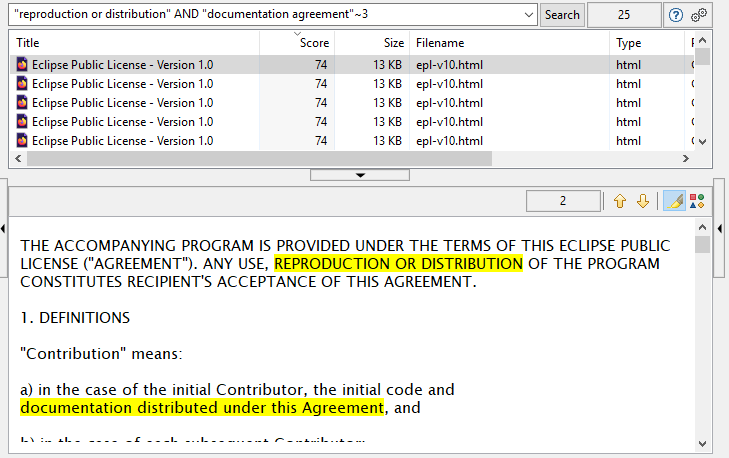
De bovenstaande schermafbeelding toont een voorbeeld van het soort complexe zoekopdrachten dat u kunt invoeren in DocFetcher, DocFetcher Pro en DocFetcher Server. De voorbeeldopdracht betekent: Vind alle documenten die (1) de woordgroep “reproduction or redistribution” bevatten, en (2) de woorden “documentation” en “agreement” op hoogstens drie woorden afstand van elkaar.
De zoekopdracht-syntaxis wordt aangedreven door de onderliggende zoekmachine Apache Lucene. Hier is een kort overzicht van de belangrijkste functies:
- Booleaanse operatoren: (hond OR kat) AND muis NOT paard
- Woordgroep zoeken, d.w.z. woorden vinden in een specifieke volgorde: "hond kat muis"
- Vereiste termen: +hond +kat
- Jokertekens: Tijdelijke aanduidingen * en ? om respectievelijk ‘nul of meer’ karakters en ‘precies één’ karakter te matchen. Voorbeelden:
- luc? komt overeen met lucy, luca, …
- luc* komt overeen met luc, lucy, luck, lucene, …
- *ene* komt overeen met lucene, energie, generator, …
- Fuzzy zoeken, d.w.z. woorden vinden die vergelijkbaar zijn met een gegeven woord. Bijvoorbeeld, zoeken naar roam~ zal documenten opleveren die woorden bevatten zoals foam en roams.
- Nabijheidszoeken, d.w.z. woorden vinden die niet meer dan een bepaald aantal woorden van elkaar af staan. Voorbeeld: "documentation agreement"~3
Index-gebaseerd Zoeken
Index-gebaseerd zoeken: DocFetcher, DocFetcher Pro en DocFetcher Server zoeken naar woorden in de bestandsnaam en inhoud van bestanden, evenals in de velden en body van Outlook-e-mails. Voor de efficiëntie echter, draait het zoeken op zogenaamde indexen, in plaats van direct op de bestanden en e-mails. Een index is in wezen een woordenboek waarin het programma snel kan opzoeken welke bestanden of e-mails een bepaald woord bevatten.
Afweging: snel zoeken en index aanmaken: Index-gebaseerd zoeken is een geweldig idee omdat het orders van grootte sneller is dan zoeken zonder indexen: DocFetcher, DocFetcher Pro en DocFetcher Server kunnen doorgaans duizenden overeenkomende bestanden vinden in minder dan een seconde. Het belangrijkste nadeel is dat de indexen eerst moeten worden aangemaakt — een proces dat indexeren wordt genoemd — en dit kan enige tijd duren afhankelijk van het totale aantal bestanden en e-mails, en hun individuele grootte.
Snel indexeren en “indexeer alleen wat je nodig hebt” filosofie: Het nadeel van het moeten aanmaken van een index wordt weggenomen door het feit dat indexeren in DocFetcher, DocFetcher Pro en DocFetcher Server vrij snel is: 200 bestanden per minuut is een vrij normale indexeersnelheid. Daarnaast volgen de drie programma’s een “indexeer alleen wat je nodig hebt” filosofie: Standaard wordt niets op uw computer geïndexeerd, en het is geheel aan u om te beslissen wat er wordt geïndexeerd. Dit staat in contrast met andere zoeksoftware die standaard een hoop tijd en computerkracht verspillen om in principe alles te indexeren, omdat ze u er niet op vertrouwen dat u zelf kunt beslissen. Om nog maar te zwijgen van de privacy-implicaties van deze “indexeer alles” benadering…
Index aanmaken vs. index bijwerken: Ten slotte is het indexeren van een bepaalde map meestal alleen tijdrovend de eerste keer, als dat al zo is. Daarna, wanneer u een zogenaamde index-update uitvoert, zal het programma slim genoeg zijn om alleen nieuwe en gewijzigde bestanden te indexeren, en de rest over te slaan. In de praktijk zijn er meestal slechts relatief weinig bestanden toegevoegd of gewijzigd, dus een index-update duurt meestal weinig tijd.
Indexen Aanmaken
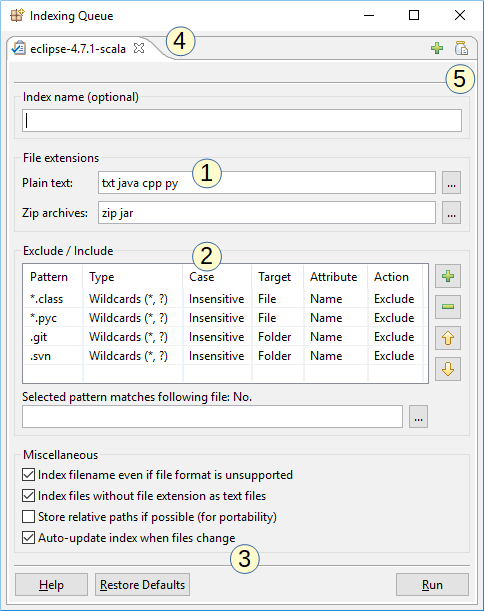
De bovenstaande schermafbeelding toont het indexeerdialoogvenster van DocFetcher Pro. Dit is het configuratiedialoogvenster dat u ziet bij het aanmaken van een nieuwe index. Opmerkelijke functies:
- Aanpasbare platte tekst en zip-extensies: De bestandsextensies waaraan het programma platte tekstbestanden en zip-archieven herkent, kunnen worden aangepast. Het aanpassen van platte tekst bestandsextensies is nuttig bij het werken met broncode.
- Inclusie- en exclusieregels: U kunt regels definiëren om bepaalde bestanden op te nemen of uit te sluiten op basis van jokerteken- of reguliere expressie-matching. Deze tabel bestaat ook in DocFetcher, maar jokertekens en de inclusieregel zijn alleen beschikbaar in DocFetcher Pro en DocFetcher Server. Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Available in DocFetcher Server
- Automatisch bijwerken van indexen: Als het vakje “Index automatisch bijwerken” is aangevinkt, zal het programma de geïndexeerde map bewaken op bestandswijzigingen en de index automatisch bijwerken wanneer een wijziging wordt gedetecteerd.
- Indexeerwachtrij: Meerdere indexeertaken kunnen in de wachtrij worden geplaatst, waarbij elke taak op een apart tabblad staat.
- Indexeerinstellingen opslaan en laden: Deze “pot” knop opent een menu voor het opslaan en laden van indexeerinstellingen. Dit is handig als u veel inclusie- en exclusieregels moet definiëren. Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Not available in DocFetcher Server
Ondersteunde Documentformaten
- AbiWord (abw, abw.gz, zabw)
- EPUB (epub)
- FictionBook (fb2, fbz, fb2.zip) Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Available in DocFetcher Server
- FLAC metadata (flac)
- HTML (html, xhtml, …)
- JPEG Exif metadata (jpg, jpeg)
- MP3 metadata (mp3)
- Microsoft Compiled HTML Help (chm)
- Microsoft Office pre-2007 (doc, xls, ppt, …)
- Microsoft Office 2007 and newer (docx, xlsx, pptx, …)
- Microsoft Outlook OST (ost) * Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Available in DocFetcher Server
- Microsoft Outlook PST (pst) *
- Microsoft Visio (vsd, vss, vst, vsw)
- Mobipocket (mobi) — support is currently experimental Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Available in DocFetcher Server
- OpenDocument (odt, ods, odg, odp, …)
- Portable Document Format (pdf)
- Plain Text (customizable extensions)
- Rich Text Format (rtf)
- Scalable Vector Graphics (svg)
Voor elk bestandsformaat dat niet in de bovenstaande lijst staat, kan ten minste de bestandsnaam worden geïndexeerd. Ook kan elk bestandsformaat dat herkenbaar is aan een specifieke bestandsextensie geforceerd worden geïndexeerd als platte tekst, omdat de platte tekst bestandsextensies aanpasbaar zijn.
* Beperkingen van PST en OST bestandsondersteuning
Geen e-mailvoorvertoning: Om technische redenen kunnen noch DocFetcher, noch DocFetcher Pro, noch DocFetcher Server e-mails in de zoekresultaten openen met Outlook. De e-mails kunnen alleen worden getoond in het tekstvoorvertoningsvenster van het programma. De mogelijkheid om e-mails in Outlook te openen kan mogelijk worden toegevoegd in een toekomstige hoofdversie van DocFetcher Pro (v2.0 of later). Dit kan niet worden geïmplementeerd in DocFetcher Server omdat de Outlook-instantie van de gebruiker en het PST- of OST-bestand dat de e-mail bevat zich mogelijk op verschillende computers bevinden.
Geef de voorkeur aan PST boven OST: Hoewel DocFetcher Pro en DocFetcher Server OST-bestanden tot op zekere hoogte kunnen lezen, moet u er rekening mee houden dat OST-bestanden eigenlijk alleen cachebestanden zijn waar Outlook tijdelijk een deel van de gegevens van een online account opslaat voor offline gebruik. Als u dus OST-bestanden indexeert, zult u merken dat veel e-mails en e-mailbijlagen die u zou verwachten te zien er gewoon niet zijn. PST-bestanden zijn wat Outlook gebruikt voor volledige, langdurige opslag van e-mails, dus geef altijd de voorkeur aan het indexeren van PST-bestanden boven OST-bestanden waar mogelijk. Voor meer informatie over PST- en OST-bestanden, en instructies over hoe te exporteren naar PST-bestanden, zie deze pagina van Microsoft.
Grote PST- en OST-bestanden: Om een PST- of OST-bestand te indexeren, moet de applicatie het volledige bestand in het RAM laden. Daarom wordt het indexeren van PST- of OST-bestanden die groter zijn dan de beschikbare hoeveelheid RAM (bijv. 30 GB PST-bestand vs. 16 GB RAM) niet ondersteund, en pogingen om dit te doen zullen de applicatie laten crashen. Om dit probleem op te lossen, kunt u het grote PST- of OST-bestand uitsluiten van indexering, of uw RAM upgraden. In geval van een RAM-upgrade, houd er rekening mee dat de totale hoeveelheid benodigde RAM groter is dan het PST- of OST-bestand, vanwege het feit dat het besturingssysteem en andere processen een deel van dat RAM in beslag nemen.
Disclaimer over best-effort indexeren
Zoals vrijwel alle zoeksoftware, ondersteunen DocFetcher, DocFetcher Pro en DocFetcher Server de verschillende hierboven genoemde bestandsformaten op een best-effort basis. Dit betekent bijvoorbeeld dat als u 10.000 bestanden probeert te indexeren, de software mogelijk slechts 9.500 bestanden (d.w.z. 95%) succesvol indexeert, terwijl het faalt op de resterende 500 bestanden. Natuurlijk hangt het werkelijke succespercentage af van uw dataset.
Bovendien, zelfs als een bepaald bestand succesvol wordt geïndexeerd, kan de software er niet in slagen om sommige tekst eruit te extraheren, vooral bij het werken met oude bestandsformaten zoals “doc” of “xls”. Het kan bijvoorbeeld falen bij het extraheren van sommige celopmerkingen of metadata uit oude Excel-bestanden.
In ieder geval zullen DocFetcher Pro en DocFetcher Server waarschijnlijk een beter werk leveren bij het indexeren van bestanden dan de oudere DocFetcher.
Als u een bijzonder hoog faalpercentage ziet tijdens het indexeren, meld het probleem dan gerust, met enkele testbestanden bijgevoegd. Er is echter geen garantie dat het probleem kan worden opgelost.
Ondersteunde Archiefformaten
- 7z archieven (7z), tot versie v0.3 van het 7z formaat
- 7z archieven (7z), tot versie v0.4 van het 7z formaat (sinds 7-Zip 9.34, van 2014-11-23) Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Available in DocFetcher Server
- Rar archieven (rar) — RAR 5.0 formaat niet ondersteund
- Tar en Tar.* archieven:
- tar, tar.gz, tgz, tar.bz2, tb2, tbz
- tbz2, tar.lzma, tlz, tar.xz, txz, tar.z, tz Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Available in DocFetcher Server
- Zip archieven (aanpasbare extensies)
Andere Opmerkelijke Functies
Cross-platform: DocFetcher, DocFetcher Pro en DocFetcher Server kunnen worden uitgevoerd op Windows, Linux en macOS. Daarnaast kan DocFetcher Server worden benaderd vanaf elke desktopcomputer met een actuele versie van Chrome, Firefox, Safari of Edge geïnstalleerd.
Draagbare versie: De DocFetcher Pro pakketten voor Windows, Linux en macOS komen elk in een draagbare en niet-draagbare versie. De draagbare versie is nuttig omdat het u toestaat om draagbare DocFetcher Pro, zijn indexen en de geïndexeerde documenten samen te bundelen, om op verschillende manieren te gebruiken:
- U kunt deze bundel meenemen op een USB-stick.
- U kunt het archiveren op een back-upmedium.
- U kunt het in een versleuteld volume plaatsen.
- U kunt het in een cloudstation plaatsen en synchroniseren tussen computers.
Houd er rekening mee dat het herverspreiden van dergelijke draagbare bundels naar andere gebruikers niet is toegestaan bij DocFetcher Pro, omdat elke gekochte kopie is gebonden aan een enkele gebruiker. (Elke ontvangende gebruiker zou zijn eigen kopie moeten kopen.) Herverspreiding is echter wel toegestaan bij de open-source DocFetcher.
Unicode-ondersteuning: DocFetcher, DocFetcher Pro en DocFetcher Server komen met solide Unicode-ondersteuning voor alle belangrijke formaten, inclusief Microsoft Office, OpenDocument, PDF, HTML, RTF en platte tekstbestanden.
Indexeren van netwerkstations: DocFetcher, DocFetcher Pro en DocFetcher Server kunnen netwerkstations evenals cloudstations indexeren. Meer algemeen, als een datastructuur kan worden aangekoppeld als iets dat eruitziet als een bestandssysteem in het OS, dan kunnen alle drie de programma’s het indexeren.
Detectie van HTML-paren: Tijdens het indexeren detecteren DocFetcher, DocFetcher Pro en DocFetcher Server paren van HTML-bestanden (bijv. een bestand genaamd test.html en een map genaamd test_files), en behandelen elk paar als een enkel document. Deze functie lijkt misschien aanvankelijk vrij nutteloos, maar het bleek dat dit de kwaliteit van de zoekresultaten dramatisch verhoogt wanneer u met HTML-bestanden werkt, omdat alle “rommel” binnen de HTML-mappen verdwijnt uit de resultaten.