Fornying av mønstertabellen
Mønstertabellen i indekseringsdialogen til DocFetcher Pro og mønstertabellen i indekseringspanelet til DocFetcher Server skiller seg fra den i DocFetcher på følgende måter:
- I tillegg til regulære uttrykk kan du bruke de mindre kraftige, men også mye enklere jokertegnene * og ? for å skrive matchingregler. Jokertegnet * er en plassholder for null eller flere tegn, mens jokertegnet ? er en plassholder for nøyaktig ett tegn.
- En ny “Inkluder”-handling i tillegg til “Ekskluder”-handlingen.
- “Detect mime type”-handlingen er fjernet. Hvis du vil indeksere filer uten filutvidelse som tekstfiler, bruk avkrysningsruten med samme beskrivelse under mønstertabellen.
- Matching kan være enten store/små bokstavfølsom eller ikke bokstavfølsom. I DocFetcher derimot er matching alltid bokstavfølsom.
- Matching kan utføres ikke bare mot vanlige filer, men også mot mapper og arkivfiler.
- På Windows, når regler matches mot filstier, vil sistnevnte bruke tegnet \ som sti-separator, ikke tegnet /. Eksempel: C:\Sti\Til\Fil.docx, i stedet for C:/Sti/Til/Fil.docx.
Som et resultat ser mønstertabellen i DocFetcher Pro slik ut:
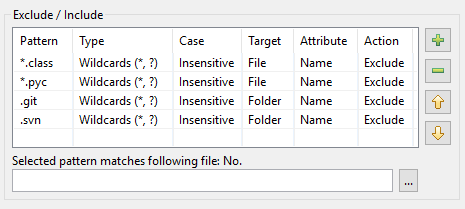
Mønstertabellen i DocFetcher Server ser lik ut, men “Valgt mønster passer til følgende fil”-testwidgeten under tabellen er for øyeblikket ikke tilgjengelig. Server Not available in DocFetcher Server
Klikk her for en detaljert diskusjon av mønstertabellen i DocFetcher, DocFetcher Pro og DocFetcher Server.
Her er hvordan fornyingen av mønstertabellen i DocFetcher Pro og DocFetcher Server kom i stand. La oss starte fra begynnelsen: I indekseringsdialogen til DocFetcher er det en mønstertabell for å utføre visse handlinger på filer som matches av bestemte mønstre under indeksering:
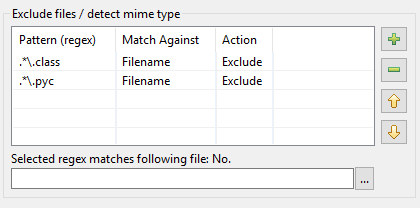
Mønstrene må være såkalte regulære uttrykk, og når det gjelder handlinger er to tilgjengelige i DocFetcher: Ekskludering av den matchede filen fra indeksering, og “mime-type deteksjon”, dvs. å prøve å gjette riktig måte å tolke den matchede filen på basert på filens innhold i stedet for basert på filnavnet. Så langt, så bra. Imidlertid viser det seg i praksis at implementasjonen ovenfor har en rekke problemer:
- Svært få personer vet hvordan man skriver regulære uttrykk.
- Noen ganger ønsker man å indeksere kun bestemte filer, og ikke unødvendig kaste bort indekseringstid på noe annet. For eksempel, indekser kun “txt”-filer og ingenting annet. DocFetcher kan faktisk gjøre dette, men det innebærer noen ganske avanserte regulære uttrykks-triks.
- Noen ganger ønsker man å ekskludere fra indeksering alle filer som matcher et bestemt mønster, unntatt alle filer som matcher et bestemt annet mønster. For eksempel, ekskluder fra indeksering alle PDF-filer, unntatt PDF-filer hvis navn starter med “rapport_”. Igjen, i DocFetcher krever dette avansert bruk av regulære uttrykk.
- Generelt er mime-type deteksjon ganske ubrukelig fordi: (1) Filutvidelsen er nesten alltid korrekt og derfor i de fleste tilfeller alt som trengs for å finne ut filformatet. (2) Når filutvidelsen ikke er korrekt og mime-type deteksjon er nødvendig, viser sistnevnte seg å ikke være spesielt pålitelig uansett. (3) Ingen bryr seg om og/eller vet hvordan man skriver matchingregler for de sjeldne tilfellene hvor mime-type deteksjon faktisk ville vært nødvendig. Imidlertid, i sammenheng med DocFetcher viser det seg at mime-type deteksjon har en viktig bruksområde: Å få programmet til å behandle filer uten filutvidelse som rene tekstfiler, f.eks. filer kalt README. Imidlertid imidlertid, for å få til dette må man skrive dette obskure regulære uttrykket: [^.]*
- Mime-type deteksjon kan mislykkes i å identifisere en fil som ren tekst hvis filen inneholder noen binære data.
- På grunn av at den portable versjonen av DocFetcher må kjøre på alle støttede plattformer, når regler matches mot filstier, bruker sistnevnte alltid tegnet / som sti-separator, selv på Windows, noe som er ganske kontraintuitivt for de fleste Windows-brukere.
Kort sagt, DocFetchers mønstertabell er et stort rot, og omskrivingen som kom med DocFetcher Pro var en god mulighet til å rydde opp i det hele:
- Jokertegn ble lagt til og er satt som standard slik at nå selv vanlige dødelige kan skrive matchingregler.
- “Inkluder”-handlingen dekker både tilfellet hvor man ønsker å indeksere kun en spesifikk type fil, og tilfellet hvor man ønsker å definere unntak til matchingregler. Selv unntak-til-unntak er nå mulig.
- Den generelt ubrukelige “Detect mime type”-handlingen er borte, og dens hovedbruksområde, å indeksere filer uten filutvidelse som tekstfiler, dekkes av en enkel avkrysningsrute under mønstertabellen. Og denne avkrysningsruten fungerer selv om filen inneholder noen binære data.
- Windows sti-separator problemet er fikset.
- Og noen andre ting (bokstavfølsomhet og matching mot filer/mapper/arkiver) ble kastet inn for godt mål.
Lasting og lagring av indekseringsinnstillinger
Merk: Denne funksjonen er for øyeblikket kun tilgjengelig i DocFetcher Pro, ikke i DocFetcher Server. Server Not available in DocFetcher Server
Problemet: I DocFetcher, hver gang du oppretter en ny indeks, må du legge inn alle reglene i mønstertabellen en etter en. Dette blir ganske kjedelig hvis du har mange sånne regler. Det er bare ingen måte å laste og lagre dem på.
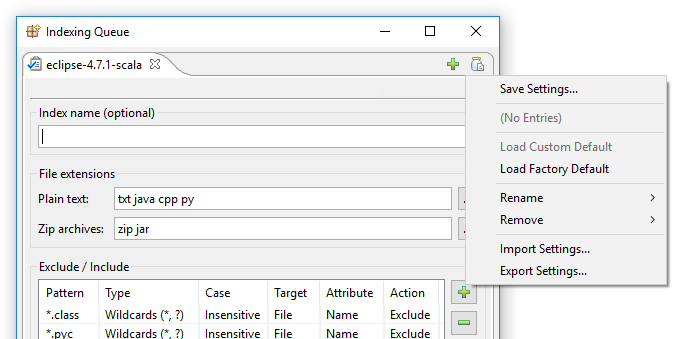
I DocFetcher Pro løses problemet ovenfor som følger: I øvre høyre hjørne av indekseringsdialogen til DocFetcher Pro sitter det en ubetydelig liten “krukke med dokument”-knapp. Å klikke på denne knappen åpner en meny som inneholder forskjellige handlinger for lasting og lagring av indekseringsinnstillinger:
Å klikke på “Lagre innstillinger” åpner denne dialogen:
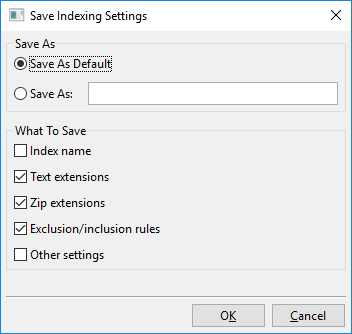
I hovedsak kan du med denne dialogen enten lagre de for øyeblikket synlige indekseringsinnstillingene til en ny navngitt plass, f.eks. “Mine nye indekseringsinnstillinger”, eller lagre de for øyeblikket synlige indekseringsinnstillingene som den nye standarden.
Denne standarden kalles “Egendefinert standard” og vil bli lastet automatisk når nye indekser opprettes. Det er også en “Fabrikkstandard”, som er standarden DocFetcher Pro bruker rett ut av boksen. De navngitte innstillingene du opprettet, nemlig “Egendefinert standard” og “Fabrikkstandard”, kan alle lastes via menyen vist ovenfor.
For å runde av tingene lar menyen deg også importere og eksportere alle indekseringsinnstillingene dine slik at du kan gjenbruke dem når du setter opp DocFetcher Pro i et nytt miljø.
Andre bemerkelsesverdige forbedringer
FB2-støtte: DocFetcher Pro og DocFetcher Server har støtte for e-bokformatet FB2. Zip-komprimerte FB2-filer, med filutvidelse fb2.zip eller fbz, støttes “innfødt”, dvs. DocFetcher Pro og DocFetcher Server ser hver sånn fil som en enkelt fil i stedet for som en fil pakket i et zip-arkiv.
Eksperimentell Mobipocket-støtte: DocFetcher Pro og DocFetcher Server har støtte for e-bokformatet Mobipocket, med filutvidelse “mobi”. Merk imidlertid at selv om DocFetcher Pro og DocFetcher Server totalt sett gjør en ganske solid jobb med å ekstraktere tekst fra mobi-filer, mislykkes de for øyeblikket enten i å ekstraktere en liten del av teksten på slutten av filen, eller i noen tilfeller mislykkes de fullstendig. Derfor er Mobipocket-støtte inntil videre merket som eksperimentell.
7z-arkivstøtte for gjeldende v0.4-format: DocFetcher kan lese 7z-arkiver opp til v0.3 av 7z-arkivformatet. DocFetcher Pro og DocFetcher Server kan også lese 7z-arkiver i gjeldende v0.4-format. Dette v0.4-formatet ble introdusert med 7-Zip 9.34, utgitt 2014-11-23.
Utvidet tar-arkivstøtte: DocFetcher støtter følgende tar-arkivutvidelser: tar, tar.gz, tgz, tar.bz2, tb2, tbz. DocFetcher Pro og DocFetcher Server støtter i tillegg følgende tar-arkivutvidelser: tbz2, tar.lzma, tlz, tar.xz, txz, tar.z, tz
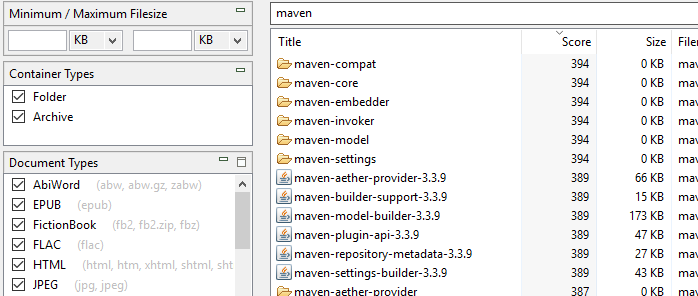
Indeksering av mappe- og arkivnavn: I motsetning til DocFetcher indekserer DocFetcher Pro og DocFetcher Server ikke bare vanlige filer, men også mapper og arkivfiler — eller mer presist, navnene på mapper og arkivfiler. Dermed vil mapper og arkivfiler vises i søkeresultatene til DocFetcher Pro og DocFetcher Server. Det er også et Beholdertyper-panel på venstre side av hovedapplikasjonsvinduet for å ekskludere mapper og/eller arkiver fra søkeresultatene.
MacOS: Daemon for automatisk indeksoppdatering: DocFetcher og DocFetcher Pro er i stand til automatisk indeksoppdatering, dvs. i stedet for å måtte starte indeksoppdateringer manuelt, startes indeksoppdateringer av programmet så snart filendringer oppdages. Imidlertid er denne funksjonaliteten kun tilgjengelig mens de to programmene faktisk kjører. Når de ikke kjører, trengs en separat daemon-prosess for å fylle gapet. I DocFetcher er daemonen kun tilgjengelig på Windows og Linux, mens i DocFetcher Pro er den også tilgjengelig på macOS. Når det gjelder DocFetcher Server, trengs ingen daemon siden serveren er designet for å kjøre kontinuerlig. Server Not available in DocFetcher Server
Smartere filnavnindeksering: Indeksering av filnavn i DocFetcher Pro og DocFetcher Server er smartere enn i DocFetcher. For eksempel, hvis DocFetcher støter på en fil kalt finn_denne_filen.pdf, ser den “finn_denne_filen” som ett enkelt ord, ikke som tre separate ord sammenkoblet. Dermed vil DocFetcher kun finne denne filen hvis du bokstavelig talt skriver inn “finn_denne_filen” i DocFetchers søkefelt. DocFetcher Pro og DocFetcher Server på den andre siden vil finne filen hvis du skriver inn “finn_denne_filen” eller noen av de tre individuelle ordene. Generelt sett det DocFetcher Pro og DocFetcher Server gjør er å gjenkjenne tegn som understreken som potensielle ordseparatorer.

Filnavnindeksering ved feil: Hvis DocFetcher Pro og DocFetcher Server mislykkes i å lese innholdet av en fil på grunn av en feil eller på grunn av passordbeskyttelse, blir filnavnet fortsatt indeksert. I DocFetcher på den andre siden hoppes filen over helt.
Ingen feil med dypt neste mappestrukturer: Når man prøver å indeksere dypt neste mappestrukturer, som C:\mappe1\mappe2\...\mappe99\mappe100, er DocFetcher tilbøyelig til å mislykkes med en “Mappehierarki er for dypt”-feil. I programmerersjargong kalles dette en “stack overflow”. DocFetcher Pro og DocFetcher Server på den andre siden er fullstendig immune mot denne typen feil.
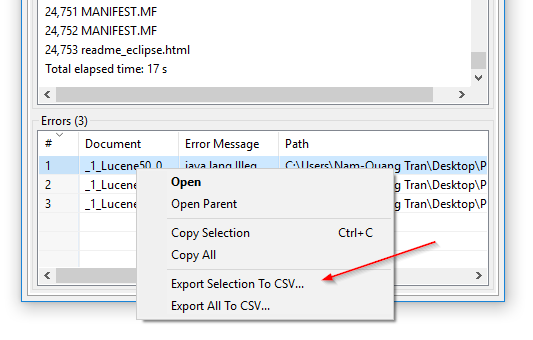
CSV-eksport av indekseringsfeil: I DocFetcher Pro kan du eksportere tabellen over filer programmet ikke klarte å lese under indeksering til en CSV-fil. Dette kan gjøres via kontekstmenyen til “Feiltabell”, som vist i følgende skjermbilde. Denne funksjonen er for øyeblikket ikke tilgjengelig i DocFetcher Server. Server Not available in DocFetcher Server
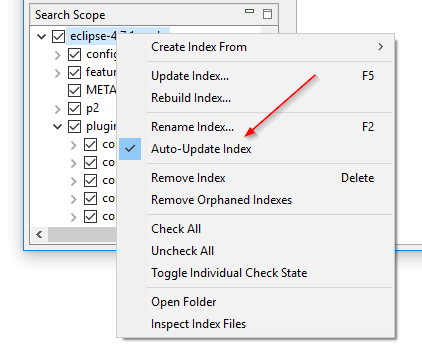
Slå mappeovervåking av og på uten å gjenoppbygge indeksen: DocFetchers “Watch folders for file changes”-innstilling, også kjent som mappeovervåking, er en per-indeks-innstilling som når den er slått på får programmet til å oppdatere indeksen automatisk når det oppdager filendringer i den indekserte mappen. Problemet er at hvis du vil slå denne innstillingen av eller på for en bestemt indeks, må du gjenoppbygge hele indeksen. I DocFetcher Pro kan du slå denne innstillingen av og på uten å gjenoppbygge indeksen, via kontekstmenyen til Search Scope-panelet. Dessuten har innstillingen blitt omdøpt til “Oppdater indeks automatisk”. Lignende funksjonalitet finnes i DocFetcher Server.
Samtidig søking og indeksgjenoppbygging: I DocFetcher, hvis du velger å gjenoppbygge en indeks, blir den indeksen utilgjengelig for søking mens gjenoppbyggingen pågår. I DocFetcher Pro og DocFetcher Server på den andre siden forblir indeksen søkbar under gjenoppbyggingen. (Mer presist, en gammel kopi av indeksen forblir søkbar mens den faktiske indeksen gjenoppbygges i bakgrunnen.)
Windows: Fikset håndtering av UNC-stier: I DocFetcher er håndteringen av UNC-stier på Windows dårlig ødelagt og ble redesignet fra bunnen av i DocFetcher Pro. Redesignet ble deretter overført til DocFetcher Server.
Ikke-modal indekseringsdialog: I motsetning til DocFetchers indekseringsdialog er den i DocFetcher Pro “ikke-modal”, noe som betyr at den ikke er festet til hovedprogramvinduet og ikke blokkerer input til hovedprogramvinduet mens den er åpen. Hovedfordelen med dette er at mens indekseringsprosesser kjører, kan du minimere hovedprogramvinduet, men holde indekseringsdialogen synlig og parkert på siden. Dette lar deg holde øye med indekseringsprosessene mens du arbeider i andre applikasjoner. Denne funksjonen gjelder ikke DocFetcher Server. Server Not available in DocFetcher Server
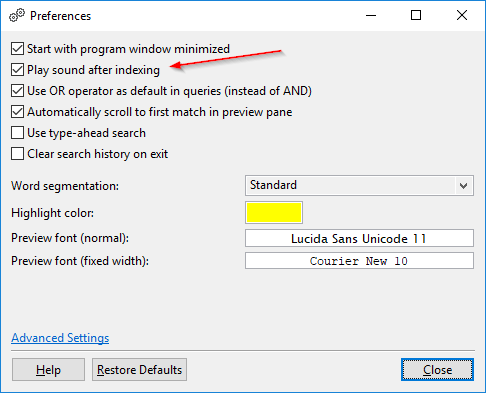
Spille en lyd etter indeksering: Som standard spiller DocFetcher Pro en “ferdig”-lyd etter indeksering. Dette kan slås av i innstillingene. Denne funksjonen er for øyeblikket ikke tilgjengelig i DocFetcher Server. Server Not available in DocFetcher Server
Indeksering av japansk tekst: DocFetcher har en såkalt “Ordsegmentering”-alternativ for å få brukbare søkeresultater når man indekserer kinesisk tekst. DocFetcher Pro har et ekstra ordsegmenteringsalternativ for håndtering av japansk tekst. Både kinesisk og japansk ordsegmentering er for øyeblikket ikke tilgjengelig i DocFetcher Server. Server Not available in DocFetcher Server