このページは、DocFetcher ProとDocFetcher Serverのすべての主要な機能の概要です。DocFetcherに慣れていない方を対象としています。DocFetcherに慣れている方は、比較のページとそのサブページの方が役立つかもしれません。
以下のスクリーンショットはすべてDocFetcher Proのユーザーインターフェースです。DocFetcher Serverのウェブインターフェースも同様で、ブラウザウィンドウ内にネストされています。
ユーザーインターフェース
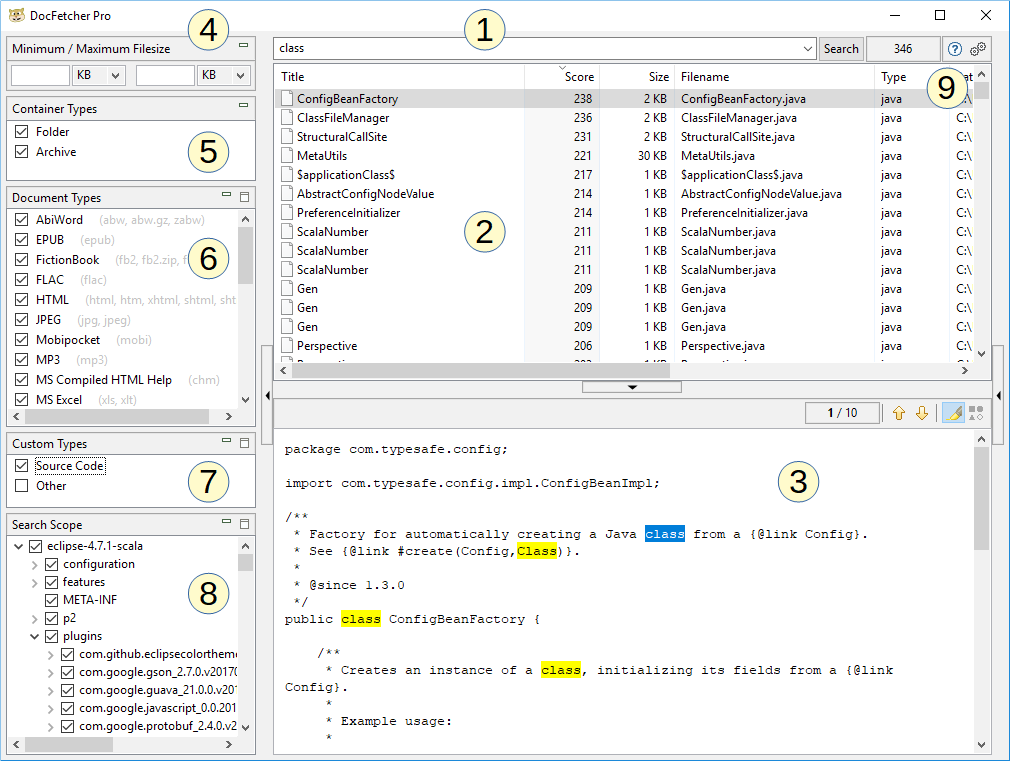
上のスクリーンショットに示すように、DocFetcher Proのメインウィンドウは次の部分で構成されています。
- 検索フィールド: ここに検索する単語を入力します。
- 結果ペイン: 検索結果がここに表示されます。これらは、検索フィールドに入力した単語を含むファイル、フォルダ、またはOutlookのメールです。
- プレビューペイン: 結果ペインで現在選択されているファイルまたはOutlookのメールのテキストのみのプレビューを表示します。テキスト内の一致箇所がハイライトされます。
- ファイルサイズの最小値/最大値 フィルター: ここで検索結果を最小および/または最大ファイルサイズでフィルタリングできます。 Free Available in the free DocFetcher Pro Available in DocFetcher Pro Server Not available in DocFetcher Server
- コンテナタイプ ペイン: ここでフォルダとアーカイブを検索結果に含めるかどうかを設定します。DocFetcherでは、フォルダとアーカイブは検索結果に含まれず、ファイルとOutlookのメールのみが含まれます。 Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Available in DocFetcher Server
- ドキュメントタイプペイン: ここで検索結果をファイルタイプでフィルタリングできます。
- カスタムタイプペイン: ドキュメントタイプペインの代替です。ここでは、独自のファイルタイプを定義して検索結果をフィルタリングできます。定義は、ファイル名に対するワイルドカードパターンまたは正規表現のマッチングに基づいています。 Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Not available in DocFetcher Server
- 検索範囲ペイン: このペインには2つの目的があります。場所による検索結果のフィルタリングと、以下で説明する「インデックス」の管理です。インデックスは追加、更新、削除できます。各インデックスは、コンピュータ上の検索可能な場所に対応しています。
- 各種コントロール: 検索ボタンの右側にある3つのコントロールは、現在表示されている検索結果の数、ユーザーマニュアルを開くボタン、およびプログラムの設定を開くボタンです。
強力なクエリ構文
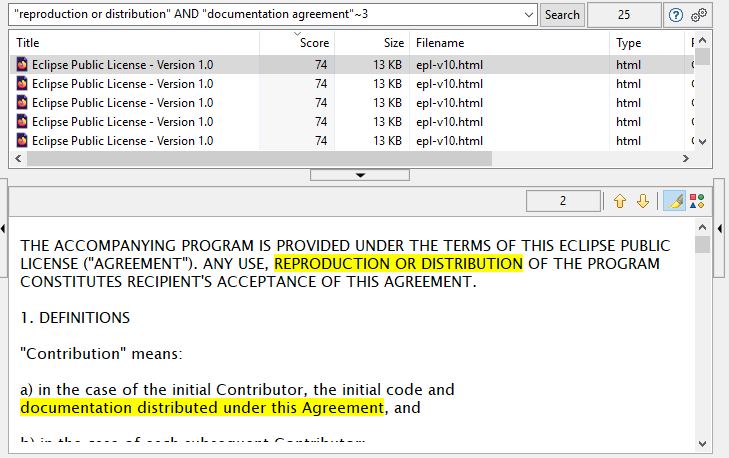
上のスクリーンショットは、DocFetcher、DocFetcher Pro、DocFetcher Serverで入力できる複雑な検索クエリの例を示しています。この例のクエリは、「reproduction or redistribution」というフレーズを含み、かつ「documentation」と「agreement」という単語が3単語以内に近接しているすべてのドキュメントを検索することを意味します。
クエリ構文は、基盤となる検索エンジンApache Luceneによって提供されています。その主な機能の簡単な概要は次のとおりです。
- ブール演算子: (犬 OR 猫) AND ねずみ NOT 馬
- フレーズ検索、つまり特定のの順序で単語を検索する: "犬 猫 ねずみ"
- 必須項目: +犬 +猫
- ワイルドカード: プレースホルダー文字 *と ?を使用して、それぞれ「0文字以上」と「正確に1文字」に一致させます。例:
- luc?は lucy、 lucaなどに一致します。
- luc*は luc、 lucy、 luck、 luceneなどに一致します。
- *ene*は lucene、 energy、 generatorなどに一致します。
- あいまい検索、つまり特定の単語に類似した単語を検索する。たとえば、 roam~を検索すると、 foamや roamsなどの単語を含むドキュメントが見つかります。
- 近接検索、つまり特定の単語数が離れていない単語を検索する。例: "documentation agreement"~3
インデックスベースの検索
インデックスベースの検索: DocFetcher、DocFetcher Pro、DocFetcher Serverは、ファイル名とファイルの内容、およびOutlookのメールのフィールドと本文で単語を検索します。ただし、効率のために、検索はファイルやメール自体ではなく、いわゆるインデックスに対して実行されます。インデックスは本質的に辞書であり、プログラムは特定の単語がどのファイルまたはメールに含まれているかをすばやく調べることができます。
トレードオフ: 高速な検索とインデックス作成: インデックスベースの検索は、インデックスなしで検索するよりも桁違いに高速であるため、優れたアイデアです。DocFetcher、DocFetcher Pro、DocFetcher Serverは、通常1秒未満で数千の一致するファイルを見つけることができます。主な欠点は、最初にインデックスを作成する必要があることです。これはインデックス作成として知られるプロセスであり、ファイルとメールの総数とその個々のサイズによっては時間がかかる場合があります。
高速なインデックス作成と「必要なものだけをインデックスする」哲学: インデックスを作成する必要があるという欠点は、DocFetcher、DocFetcher Pro、DocFetcher Serverでのインデックス作成が非常に高速であるという事実によって軽減されます。毎分200ファイルは、ごく普通のインデックス作成速度です。さらに、3つのプログラムは「必要なものだけをインデックスする」という哲学に従っています。初期設定では、コンピュータ上の何もインデックスされず、何をインデックスするかは完全にあなた次第です。これは、初期設定で基本的にすべてをインデックスするために多くの時間とコンピュータパワーを浪費する他の検索ソフトウェアとは対照的です。彼らはあなたが自分で決定することを信頼していないからです。この「すべてをインデックスする」アプローチのプライバシーへの影響は言うまでもありません…
インデックス作成とインデックス更新: 最後に、特定のフォルダのインデックス作成は、通常、初回のみ時間がかかります(もしあれば)。その後、いわゆるインデックス更新を実行するたびに、プログラムは新しく変更されたファイルのみをインデックスし、その他すべてをスキップするのに十分賢くなります。実際には、通常、比較的小数のファイルしか追加または変更されていないため、インデックス更新にはほとんど時間がかかりません。
インデックスの作成
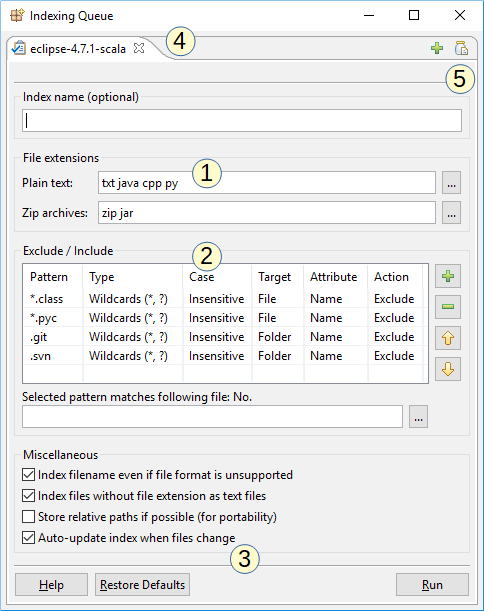
上のスクリーンショットは、DocFetcher Proのインデックス作成ダイアログを示しています。これは、新しいインデックスを作成するときに表示される設定ダイアログです。注目すべき機能:
- カスタマイズ可能なプレーンテキストとzipの拡張子: プログラムがプレーンテキストファイルとzipアーカイブを認識するためのファイル拡張子をカスタマイズできます。プレーンテキストファイルの拡張子をカスタマイズすることは、ソースコードを扱う場合に便利です。
- 包含および除外ルール: ワイルドカードまたは正規表現のマッチングに基づいて特定のファイルを含めたり除外したりするルールを定義できます。このテーブルはDocFetcherにも存在しますが、ワイルドカードと包含ルールはDocFetcher ProとDocFetcher Serverでのみ利用できます。 Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Available in DocFetcher Server
- インデックスの自動更新: 「インデックスを自動更新」ボックスがチェックされている場合、プログラムはインデックス付きフォルダのファイルの変更を監視し、変更が検出されるとインデックスを自動的に更新します。
- インデックス作成キュー: 複数のインデックス作成ジョブをキューに入れることができ、各ジョブは別のタブに表示されます。
- インデックス作成設定の保存と読み込み: この「瓶」ボタンは、インデックス作成設定を保存および読み込むためのメニューを開きます。これは、多くの包含および除外ルールを定義する必要がある場合に便利です。 Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Not available in DocFetcher Server
サポートされているドキュメント形式
- AbiWord (abw, abw.gz, zabw)
- EPUB (epub)
- FictionBook (fb2, fbz, fb2.zip) Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Available in DocFetcher Server
- FLACメタデータ (flac)
- HTML (html, xhtml, …)
- JPEG Exifメタデータ (jpg, jpeg)
- MP3メタデータ (mp3)
- Microsoft Compiled HTML Help (chm)
- Microsoft Office 2007以前 (doc, xls, ppt, …)
- Microsoft Office 2007以降 (docx, xlsx, pptx, …)
- Microsoft Outlook OST (ost) * Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Available in DocFetcher Server
- Microsoft Outlook PST (pst) *
- Microsoft Visio (vsd, vss, vst, vsw)
- Mobipocket (mobi) — 現在、サポートは実験的です Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Available in DocFetcher Server
- OpenDocument (odt, ods, odg, odp, …)
- Portable Document Format (pdf)
- プレーンテキスト (カスタマイズ可能な拡張子)
- Rich Text Format (rtf)
- Scalable Vector Graphics (svg)
上記のリストに含まれていないファイル形式については、少なくともファイル名はインデックスを作成できます。また、特定のファイル拡張子で識別できるファイル形式は、プレーンテキストファイルの拡張子がカスタマイズ可能であるため、強制的にプレーンテキストとしてインデックスを作成できます。
* PSTおよびOSTファイルのサポートの制限
メールのプレビューなし: 技術的な理由により、DocFetcher、DocFetcher Pro、DocFetcher Serverのいずれも、検索結果のメールをOutlookで開くことはできません。メールは、プログラムのテキストのみのプレビューペインにのみ表示できます。Outlookでメールを開く機能は、DocFetcher Proの将来のメジャーリリース(v2.0以降)で追加される可能性があります。ユーザーのOutlookインスタンスとメールを含むPSTまたはOSTファイルが異なるコンピュータにある可能性があるため、DocFetcher Serverでは実装できません。
OSTよりもPSTを優先: DocFetcher ProとDocFetcher ServerはOSTファイルをある程度読み取ることができますが、OSTファイルは実際にはOutlookがオフラインで使用するためにオンラインアカウントのデータの一部を一時的に保存するキャッシュファイルにすぎないことに注意してください。したがって、OSTファイルをインデックスすると、表示されるはずの多くのメールやメールの添付ファイルが単に存在しないことがわかります。PSTファイルは、Outlookがメールを完全かつ長期的に保存するために使用するものであるため、可能な場合は常にOSTファイルのインデックス作成よりもPSTファイルのインデックス作成を優先してください。PSTおよびOSTファイルの詳細、およびPSTファイルへのエクスポート手順については、Microsoftのこのページを参照してください。
大きなPSTおよびOSTファイル: PSTまたはOSTファイルをインデックスするには、アプリケーションがファイル全体をRAMにロードする必要があります。したがって、利用可能なRAMの量よりも大きいPSTまたはOSTファイル(例: 30 GBのPSTファイル対16 GBのRAM)のインデックス作成はサポートされておらず、そうしようとするとアプリケーションがクラッシュします。この問題に対処するには、大きなPSTまたはOSTファイルをインデックスから除外するか、RAMをアップグレードすることができます。RAMをアップグレードする場合、オペレーティングシステムやその他のプロセスがRAMの一部を占有するため、必要なRAMの合計量はPSTまたはOSTファイルよりも大きくなることに注意してください。
ベストエフォートでのインデックス作成に関する免責事項
事実上すべての検索ソフトウェアと同様に、DocFetcher、DocFetcher Pro、DocFetcher Serverは、上記のさまざまなファイル形式をベストエフォートでサポートしています。これは、たとえば、10,000個のファイルをインデックスしようとすると、ソフトウェアは9,500個のファイル(つまり95%)しか正常にインデックスできず、残りの500個のファイルで失敗する可能性があることを意味します。もちろん、実際の成功率はデータセットによって異なります。
さらに、特定のファイルが正常にインデックスされたとしても、特に「doc」や「xls」などの古いファイル形式を扱う場合、ソフトウェアはその中のテキストの一部を抽出できない場合があります。たとえば、古いExcelファイルから一部のセルコメントやメタデータを抽出できない場合があります。
いずれにせよ、DocFetcher ProとDocFetcher Serverは、古いDocFetcherよりもファイルのインデックス作成をうまく行う可能性が最も高いです。
インデックス作成中に特に高い失敗率が見られる場合は、問題を報告してください。テストファイルを添付してください。ただし、問題が解決される保証はありません。
サポートされているアーカイブ形式
- 7zアーカイブ (7z)、7z形式のバージョンv0.3まで
- 7zアーカイブ (7z)、7z形式のバージョンv0.4まで(2014-11-23の7-Zip 9.34以降) Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Available in DocFetcher Server
- Rarアーカイブ (rar) — RAR 5.0形式はサポートされていません
- TarおよびTar.*アーカイブ:
- tar, tar.gz, tgz, tar.bz2, tb2, tbz
- tbz2, tar.lzma, tlz, tar.xz, txz, tar.z, tz Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Available in DocFetcher Server
- Zipアーカイブ (カスタマイズ可能な拡張子)
その他の注目すべき機能
クロスプラットフォーム: DocFetcher、DocFetcher Pro、DocFetcher Serverは、Windows、Linux、macOSで実行できます。さらに、DocFetcher Serverは、最新バージョンのChrome、Firefox、Safari、またはEdgeがインストールされているデスクトップコンピュータからアクセスできます。
ポータブルバージョン: Windows、Linux、macOS用のDocFetcher Proパッケージには、それぞれポータブルバージョンと非ポータブルバージョンがあります。ポータブルバージョンは、ポータブルなDocFetcher Pro、そのインデックス、およびインデックスされたドキュメントをバンドルして、さまざまな方法で使用できるという点で便利です。
- このバンドルをUSBドライブに入れて持ち運ぶことができます。
- バックアップメディアにアーカイブできます。
- 暗号化されたボリュームに入れることができます。
- クラウドドライブに入れて、コンピュータ間で同期できます。
DocFetcher Proでは、購入した各コピーは単一のユーザーに紐付けられているため、このようなポータブルバンドルを他のユーザーに再配布することは許可されていません。(受け取る各ユーザーは自分のコピーを購入する必要があります。)ただし、オープンソースのDocFetcherでは再配布が許可されています。
Unicodeサポート: DocFetcher、DocFetcher Pro、DocFetcher Serverは、Microsoft Office、OpenDocument、PDF、HTML、RTF、プレーンテキストファイルなど、すべての主要な形式で堅牢なUnicodeサポートを備えています。
ネットワークドライブのインデックス作成: DocFetcher、DocFetcher Pro、DocFetcher Serverは、ネットワークドライブとクラウドドライブをインデックスできます。より一般的には、データ構造がOSでファイルシステムのようにマウントできるものであれば、3つのプログラムすべてがそれをインデックスできます。
HTMLペアの検出: インデックス作成中、DocFetcher、DocFetcher Pro、DocFetcher ServerはHTMLファイルのペア(例: foo.htmlという名前のファイルと foo_filesという名前のフォルダ)を検出し、各ペアを単一のドキュメントとして扱います。この機能は最初はあまり役に立たないように思えるかもしれませんが、HTMLファイルを扱う場合、HTMLフォルダ内のすべての「がらくた」が結果から消えるため、検索結果の品質が劇的に向上することがわかりました。