Refonte du tableau de motifs
Le tableau de motifs de la boîte de dialogue d’indexation de DocFetcher Pro et le tableau de motifs du volet d’indexation de DocFetcher Server diffèrent de celui de DocFetcher de la manière suivante :
- En plus des expressions régulières, vous pouvez utiliser les caractères génériques * et ?, moins puissants mais beaucoup plus simples, pour écrire des règles de correspondance. Le caractère générique * est un espace réservé pour zéro ou plusieurs caractères, tandis que le caractère générique ? est un espace réservé pour exactement un caractère.
- Une nouvelle action « Inclure » en plus de l’action « Exclure ».
- L’action « Détecter le type mime » a disparu. Si vous voulez indexer des fichiers sans extension comme fichiers texte, utilisez la case à cocher de même description sous le tableau de motifs.
- La correspondance peut être sensible à la casse ou insensible à la casse. Dans DocFetcher en revanche, la correspondance est toujours sensible à la casse.
- La correspondance peut être effectuée non seulement sur les fichiers réguliers, mais aussi sur les dossiers et les fichiers d’archive.
- Sous Windows, lorsque les règles sont comparées aux chemins de fichiers, ces derniers utilisent le caractère \ comme séparateur de chemin, et non le caractère /. Exemple : C:\Chemin\Vers\Fichier.docx, au lieu de C:/Chemin/Vers/Fichier.docx.
En conséquence, voici à quoi ressemble le tableau de motifs dans DocFetcher Pro :
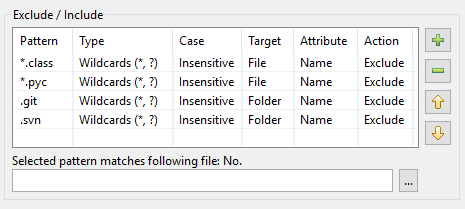
Le tableau de motifs dans DocFetcher Server a la même apparence, mais le widget de test « Modèle sélectionné correspond au fichier suivant » sous le tableau n’est actuellement pas disponible. Server Not available in DocFetcher Server
Cliquez ici pour une discussion détaillée du tableau de motifs dans DocFetcher, DocFetcher Pro et DocFetcher Server.
Voici comment la refonte du tableau de motifs dans DocFetcher Pro et DocFetcher Server s’est déroulée. Commençons par le commencement : dans la boîte de dialogue d’indexation de DocFetcher, il y a un tableau de motifs pour effectuer certaines actions sur les fichiers correspondant à certains motifs lors de l’indexation :
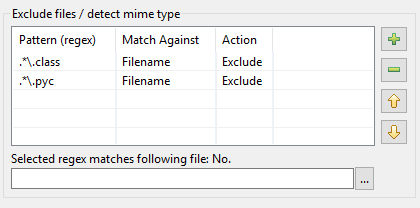
Les motifs doivent être des expressions régulières, et quant aux actions, deux sont disponibles dans DocFetcher : exclure le fichier correspondant de l’indexation, et la « détection de type mime », c’est-à-dire essayer de deviner la bonne façon d’analyser le fichier correspondant en se basant sur le contenu du fichier plutôt que sur son nom de fichier. Jusqu’ici, tout va bien. Cependant, en pratique, il s’avère que l’implémentation ci-dessus présente un certain nombre de problèmes :
- Très peu de personnes savent comment écrire des expressions régulières.
- Parfois, on veut indexer seulement certains fichiers, et ne pas perdre inutilement du temps d’indexation sur autre chose. Par exemple, indexer seulement les fichiers « txt » et rien d’autre. DocFetcher peut en fait faire cela, mais cela implique des astuces d’expressions régulières assez avancées.
- Parfois, on veut exclure de l’indexation tous les fichiers correspondant à un certain motif, à l’exception de tous les fichiers correspondant à un certain autre motif. Par exemple, exclure de l’indexation tous les fichiers PDF, à l’exception des fichiers PDF dont les noms commencent par « rapport_ ». Encore une fois, dans DocFetcher, cela nécessite une utilisation avancée des expressions régulières.
- En général, la détection de type mime est assez inutile car : (1) L’extension de fichier est presque toujours correcte et donc dans la plupart des cas, c’est tout ce qui est nécessaire pour déterminer le format de fichier. (2) Quand l’extension de fichier n’est pas correcte et que la détection de type mime est nécessaire, cette dernière s’avère de toute façon peu fiable. (3) Personne ne se donne la peine et/ou ne sait comment écrire des règles de correspondance pour ces rares cas où la détection de type mime serait vraiment nécessaire. Cependant, dans le contexte de DocFetcher, il s’avère que la détection de type mime a un cas d’usage important : faire en sorte que le programme traite les fichiers sans extension comme des fichiers texte brut, par exemple les fichiers nommés README. Cependant cependant, pour y parvenir, il faut écrire cette expression régulière obscure : [^.]*
- La détection de type mime peut échouer à identifier un fichier comme texte brut si le fichier contient des données binaires.
- En raison du fait que la version portable de DocFetcher doit fonctionner sur toutes les plateformes supportées, lors de la correspondance des règles avec les chemins de fichiers, ces derniers utilisent toujours le caractère / comme séparateur de chemin, même sous Windows, ce qui est assez contre-intuitif pour la plupart des utilisateurs Windows.
En bref, le tableau de motifs de DocFetcher est un vrai fouillis, et la réécriture qui est venue avec DocFetcher Pro était une bonne occasion de tout nettoyer :
- Les caractères génériques ont été ajoutés et définis par défaut, de sorte que maintenant même les simples mortels peuvent écrire des règles de correspondance.
- L’action « Inclure » couvre à la fois le cas où l’on veut indexer seulement un type spécifique de fichier, et le cas où l’on veut définir des exceptions aux règles de correspondance. Même les exceptions aux exceptions sont maintenant possibles.
- L’action généralement inutile « Détecter le type mime » a disparu, et son principal cas d’usage, indexer les fichiers sans extension comme fichiers texte, est couvert par une simple case à cocher sous le tableau de motifs. Et cette case à cocher fonctionne même si le fichier contient des données binaires.
- Le problème du séparateur de chemin Windows est corrigé.
- Et d’autres choses (sensibilité à la casse et correspondance avec les fichiers/dossiers/archives) ont été ajoutées pour faire bonne mesure.
Chargement et sauvegarde des paramètres d’indexation
Note : Cette fonctionnalité n’est actuellement disponible que dans DocFetcher Pro, pas dans DocFetcher Server. Server Not available in DocFetcher Server
Le problème : Dans DocFetcher, chaque fois que vous créez un nouvel index, vous devez saisir toutes les règles dans le tableau de motifs une par une. Cela devient assez fastidieux si vous avez beaucoup de telles règles. Il n’y a tout simplement aucun moyen de les charger et de les sauvegarder.
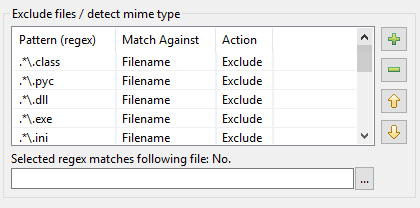
Dans DocFetcher Pro, le problème ci-dessus est résolu comme suit : Dans le coin supérieur droit de la boîte de dialogue d’indexation de DocFetcher Pro, se trouve un petit bouton discret « pot avec document ». Cliquer sur ce bouton ouvre un menu contenant diverses actions pour charger et sauvegarder les paramètres d’indexation :
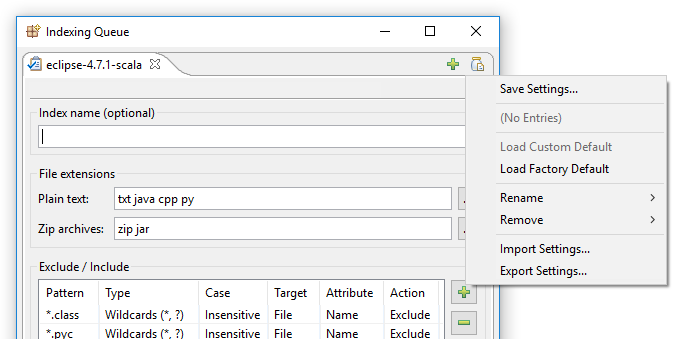
Cliquer sur « Enregistrer les paramètres » ouvre cette boîte de dialogue :
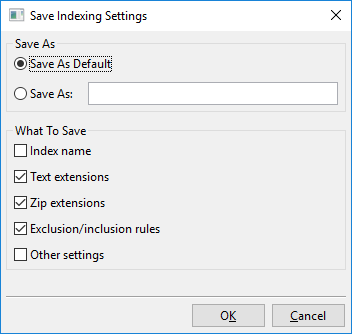
Essentiellement, ce que vous pouvez faire avec cette boîte de dialogue est soit sauvegarder les paramètres d’indexation actuellement visibles dans un nouvel emplacement nommé, par exemple « Mes nouveaux paramètres d’indexation », soit sauvegarder les paramètres d’indexation actuellement visibles comme nouvelle valeur par défaut.
Cette valeur par défaut est appelée « Valeurs personnalisées » et sera chargée automatiquement lors de la création de nouveaux index. Il y a aussi une « Valeurs d'usine », qui est la valeur par défaut que DocFetcher Pro utilise prêt à l’emploi. Les paramètres nommés que vous avez créés, à savoir « Valeurs personnalisées » et « Valeurs d'usine », peuvent tous être chargés via le menu présenté ci-dessus.
Pour couronner le tout, le menu permet également d’importer et d’exporter tous vos paramètres d’indexation afin de pouvoir les réutiliser lors de la configuration de DocFetcher Pro dans un nouvel environnement.
Autres améliorations notables
Support FB2 : DocFetcher Pro et DocFetcher Server prennent en charge le format de livre électronique FB2. Les fichiers FB2 compressés en zip, avec l’extension de fichier fb2.zip ou fbz, sont pris en charge « nativement », c’est-à-dire que DocFetcher Pro et DocFetcher Server voient chaque fichier comme un fichier unique plutôt que comme un fichier emballé dans une archive zip.
Support expérimental Mobipocket : DocFetcher Pro et DocFetcher Server prennent en charge le format de livre électronique Mobipocket, avec l’extension de fichier « mobi ». Cependant, notez que bien que DocFetcher Pro et DocFetcher Server fassent globalement un travail assez solide d’extraction de texte à partir des fichiers mobi, ils échouent actuellement soit à extraire une petite portion de texte à la fin du fichier, soit dans certains cas échouent complètement. Par conséquent, le support Mobipocket est pour l’instant marqué comme expérimental.
Support d’archives 7z pour le format v0.4 actuel : DocFetcher peut lire les archives 7z jusqu’à la v0.3 du format d’archive 7z. DocFetcher Pro et DocFetcher Server peuvent également lire les archives 7z dans le format v0.4 actuel. Ce format v0.4 a été introduit avec 7-Zip 9.34, publié le 23-11-2014.
Support étendu d’archives tar : DocFetcher prend en charge les extensions d’archives tar suivantes : tar, tar.gz, tgz, tar.bz2, tb2, tbz. DocFetcher Pro et DocFetcher Server prennent en charge en plus les extensions d’archives tar suivantes : tbz2, tar.lzma, tlz, tar.xz, txz, tar.z, tz
Indexation des noms de dossiers et d’archives : Contrairement à DocFetcher, DocFetcher Pro et DocFetcher Server indexent non seulement les fichiers réguliers, mais aussi les dossiers et les fichiers d’archive — ou plus précisément, les noms des dossiers et des fichiers d’archive. Ainsi, les dossiers et les fichiers d’archive apparaîtront dans les résultats de recherche de DocFetcher Pro et DocFetcher Server. Il y a aussi un volet Types de conteneurs sur le côté gauche de la fenêtre principale de l’application pour exclure les dossiers et/ou les archives des résultats de recherche.
MacOS : Démon pour la mise à jour automatique d’index : DocFetcher et DocFetcher Pro sont capables de mise à jour d’index automatique, c’est-à-dire qu’au lieu de devoir démarrer les mises à jour d’index manuellement, les mises à jour d’index sont démarrées par le programme dès que des changements de fichiers sont détectés. Cependant, cette fonctionnalité n’est disponible que lorsque les deux programmes sont effectivement en cours d’exécution. Quand ils ne sont pas en cours d’exécution, un processus démon séparé est nécessaire pour combler le manque. Dans DocFetcher, le démon n’est disponible que sur Windows et Linux, tandis que dans DocFetcher Pro, il est aussi disponible sur macOS. Quant à DocFetcher Server, aucun démon n’est nécessaire puisque le serveur est conçu pour fonctionner en continu. Server Not available in DocFetcher Server
Indexation plus intelligente des noms de fichiers : L’indexation des noms de fichiers dans DocFetcher Pro et DocFetcher Server est plus intelligente que dans DocFetcher. Par exemple, si DocFetcher rencontre un fichier nommé trouve_ce_fichier.pdf, il voit « trouve_ce_fichier » comme un seul mot, pas comme trois mots séparés assemblés. Ainsi, DocFetcher ne trouvera ce fichier que si vous tapez littéralement « trouve_ce_fichier » dans le champ de recherche de DocFetcher. DocFetcher Pro et DocFetcher Server d’autre part trouveront le fichier si vous tapez « trouve_ce_fichier » ou n’importe lequel des trois mots individuels. De manière générale, ce que DocFetcher Pro et DocFetcher Server font est de reconnaître des caractères comme le trait de soulignement comme des séparateurs de mots potentiels.

Indexation de noms de fichiers en cas d’erreurs : Si DocFetcher Pro et DocFetcher Server échouent à lire le contenu d’un fichier à cause d’une erreur ou en raison d’une protection par mot de passe, le nom de fichier est tout de même indexé. Dans DocFetcher d’autre part, le fichier est complètement ignoré.
Aucune erreur avec les structures de dossiers profondément imbriquées : Lors de la tentative d’indexation de structures de dossiers profondément imbriquées, telles que C:\dossier1\dossier2\...\dossier99\dossier100, DocFetcher est enclin à échouer avec une erreur « Hiérarchie de dossiers trop profonde ». En jargon de programmeur, cela s’appelle un « débordement de pile ». DocFetcher Pro et DocFetcher Server d’autre part sont complètement immunisés contre ce type d’erreur.
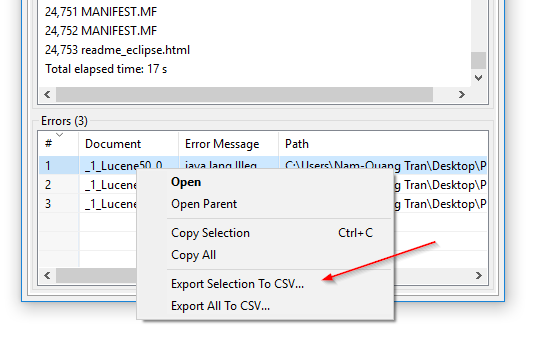
Export CSV des erreurs d’indexation : Dans DocFetcher Pro, vous pouvez exporter le tableau des fichiers que le programme a échoué à lire lors de l’indexation vers un fichier CSV. Cela peut être fait via le menu contextuel du tableau d’erreurs, comme montré dans la capture d’écran suivante. Cette fonctionnalité n’est actuellement pas disponible dans DocFetcher Server. Server Not available in DocFetcher Server
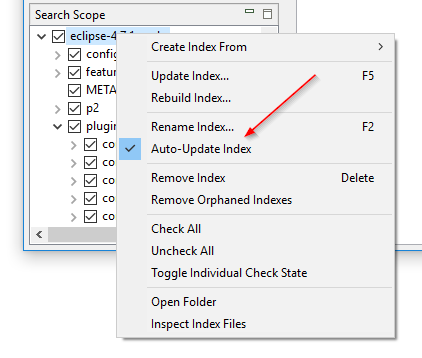
Activer et désactiver la surveillance de dossiers sans reconstruire l’index : Le paramètre « Surveiller les fichiers modifiés dans les dossiers » de DocFetcher, aussi connu sous le nom de surveillance de dossiers, est un paramètre par index qui quand il est activé fait que le programme met automatiquement à jour l’index chaque fois qu’il détecte des changements de fichiers dans le dossier indexé. Le problème est que si vous voulez activer ou désactiver ce paramètre sur un index particulier, vous devez reconstruire l’index entier. Dans DocFetcher Pro, vous pouvez activer et désactiver ce paramètre sans reconstruire l’index, via le menu contextuel du volet Portée de recherche. De plus, le paramètre a été renommé en « Mise à jour automatique de l'index ». Une fonctionnalité similaire existe dans DocFetcher Server.
Recherche simultanée et reconstruction d’index : Dans DocFetcher, si vous choisissez de reconstruire un index, cet index devient indisponible pour la recherche pendant que la reconstruction est en cours. Dans DocFetcher Pro et DocFetcher Server d’autre part, l’index reste cherchable pendant la reconstruction. (Plus précisément, une ancienne copie de l’index reste cherchable pendant que l’index actuel est reconstruit en arrière-plan.)
Windows : Gestion corrigée des chemins UNC : Dans DocFetcher, la gestion des chemins UNC sous Windows est gravement cassée et a été repensée depuis zéro dans DocFetcher Pro. La refonte a ensuite été reportée vers DocFetcher Server.
Boîte de dialogue d’indexation non modale : Contrairement à la boîte de dialogue d’indexation de DocFetcher, celle de DocFetcher Pro est « non modale », ce qui signifie qu’elle n’est pas attachée à la fenêtre principale du programme et ne bloque pas la saisie vers la fenêtre principale du programme pendant qu’elle est ouverte. Le principal avantage de ceci est que pendant que les processus d’indexation sont en cours, vous pouvez minimiser la fenêtre principale du programme, mais garder la boîte de dialogue d’indexation visible et garée sur le côté. Cela vous permet de garder un œil sur les processus d’indexation tout en travaillant dans d’autres applications. Cette fonctionnalité ne s’applique pas à DocFetcher Server. Server Not available in DocFetcher Server
Jouer un son après l’indexation : Par défaut, DocFetcher Pro joue un son « terminé » après l’indexation. Cela peut être désactivé dans les préférences. Cette fonctionnalité n’est actuellement pas disponible dans DocFetcher Server. Server Not available in DocFetcher Server
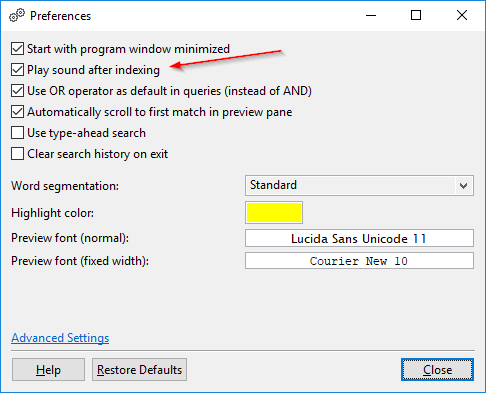
Indexation de texte japonais : DocFetcher a une option appelée « segmentation de mots » pour obtenir des résultats de recherche utilisables lors de l’indexation de texte chinois. DocFetcher Pro a une option de segmentation de mots supplémentaire pour gérer le texte japonais. La segmentation de mots chinoise et japonaise ne sont actuellement pas disponibles dans DocFetcher Server. Server Not available in DocFetcher Server