Cette page est un aperçu de toutes les fonctionnalités principales de DocFetcher Pro et DocFetcher Server, destinée à ceux qui ne connaissent pas DocFetcher. Si c’est votre cas, vous trouverez peut-être la page Comparaison et ses sous-pages plus utiles.
Toutes les captures d’écran ci-dessous montrent l’interface utilisateur de DocFetcher Pro. L’interface web de DocFetcher Server ressemble et est intégrée dans une fenêtre de navigateur.
L’interface utilisateur
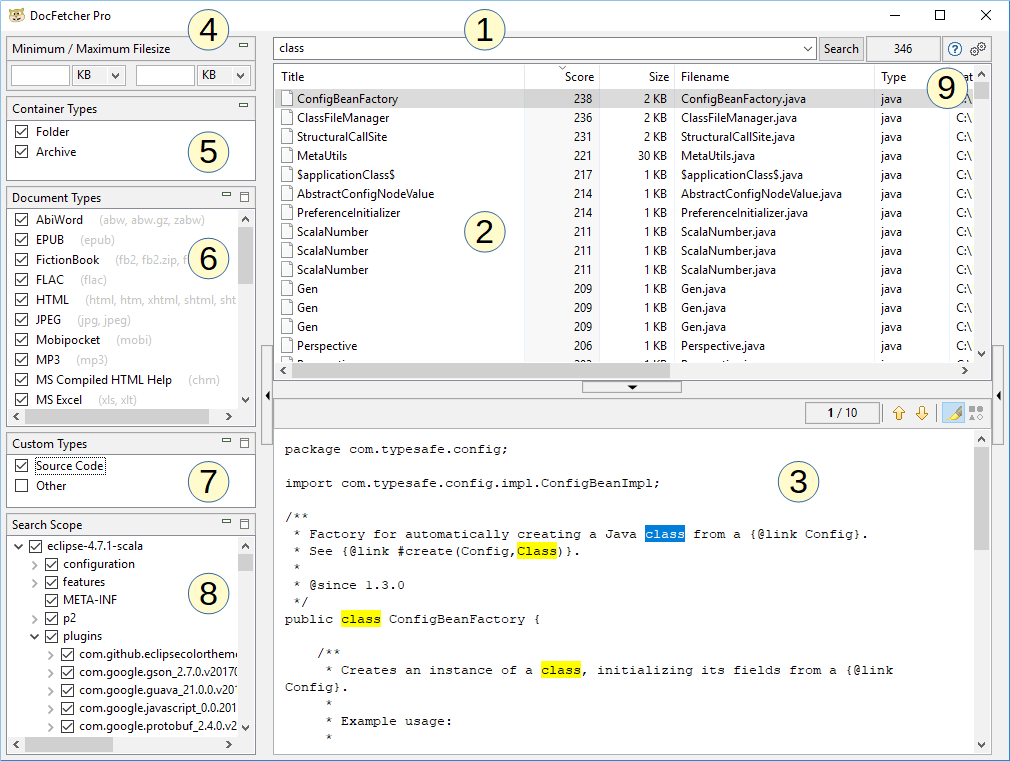
Comme le montre la capture d’écran ci-dessus, la fenêtre principale de DocFetcher Pro se compose des parties suivantes :
- Champ de recherche : Saisissez ici les mots à rechercher.
- Volet de résultats : Les résultats de recherche sont affichés ici. Il s’agit des fichiers, dossiers ou e-mails Outlook contenant les mots que vous avez saisis dans le champ de recherche.
- Volet de prévisualisation : Affiche un aperçu en texte seul du fichier ou de l’e-mail Outlook actuellement sélectionné dans le volet de résultats. Les correspondances dans le texte sont surlignées.
- Filtre Taille de fichier minimale/maximale : Les résultats de recherche peuvent être filtrés par taille de fichier minimale et/ou maximale ici. Free Available in the free DocFetcher Pro Available in DocFetcher Pro Server Not available in DocFetcher Server
- Volet Types de conteneurs : Définissez ici si les dossiers et archives doivent être inclus dans les résultats de recherche. Dans DocFetcher, les dossiers et archives ne sont pas inclus dans les résultats de recherche, seulement les fichiers et e-mails Outlook. Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Available in DocFetcher Server
- Volet Types de documents : Les résultats de recherche peuvent être filtrés par type de fichier ici.
- Volet Types personnalisés : Une alternative au volet Types de documents. Ici, vous pouvez définir vos propres types de fichiers pour filtrer les résultats de recherche. Les définitions sont basées sur la correspondance de motifs génériques ou d’expressions régulières avec les noms de fichiers. Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Not available in DocFetcher Server
- Volet Portée de la recherche : Ce volet a deux objectifs : filtrer les résultats de recherche par emplacement et gérer vos « index », qui sont expliqués ci-dessous. Les index peuvent être ajoutés, mis à jour et supprimés. Chaque index correspond à un emplacement recherchable sur votre ordinateur.
- Divers contrôles : Les trois contrôles à droite du bouton Rechercher sont : le nombre de résultats de recherche actuellement visibles, un bouton pour ouvrir le manuel de l’utilisateur et un bouton pour ouvrir les préférences du programme.
Syntaxe de requête puissante
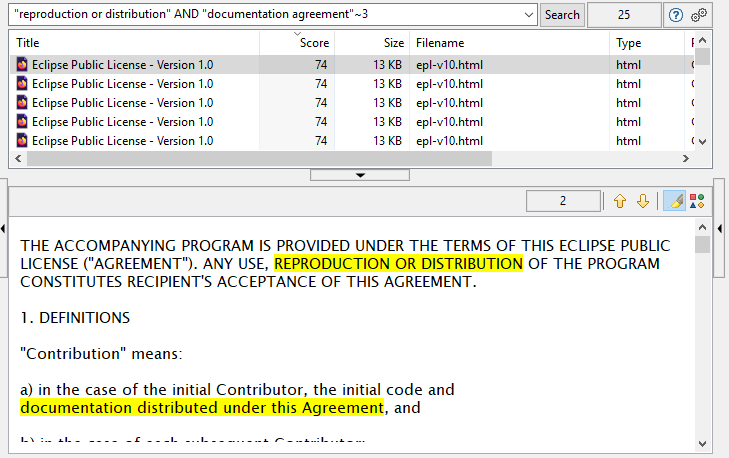
La capture d’écran ci-dessus montre un exemple des types de requêtes de recherche complexes que vous pouvez saisir dans DocFetcher, DocFetcher Pro et DocFetcher Server. L’exemple de requête signifie : Trouver tous les documents contenant (1) la phrase « reproduction or redistribution » et (2) les mots « documentation » et « agreement » à au plus trois mots d’intervalle.
La syntaxe de requête est alimentée par le moteur de recherche sous-jacent Apache Lucene. Voici un aperçu rapide de ses principales fonctionnalités :
- Opérateurs booléens : (chien OR chat) AND souris NOT cheval
- Recherche de phrase, c’est-à-dire trouver des mots dans un ordre spécifique : "chien chat souris"
- Termes requis : +chien +chat
- Caractères génériques : Caractères de remplacement * et ? pour correspondre respectivement à « zéro ou plusieurs » caractères et « exactement un » caractère. Exemples :
- luc? correspond à luce, luca, …
- luc* correspond à luc, luce, luck, lucene, …
- *ene* correspond à lucene, énergie, générateur, …
- Recherche approximative, c’est-à-dire trouver des mots similaires à un mot donné. Par exemple, rechercher roam~ fera apparaître des documents contenant des mots comme foam et roams.
- Recherche de proximité, c’est-à-dire trouver des mots qui ne sont pas à plus d’un certain nombre de mots d’intervalle. Exemple : "documentation agreement"~3
Recherche basée sur les index
Recherche basée sur les index : DocFetcher, DocFetcher Pro et DocFetcher Server recherchent des mots dans le nom de fichier et le contenu des fichiers, ainsi que dans les champs et le corps des e-mails Outlook. Cependant, pour des raisons d’efficacité, la recherche s’exécute sur des index plutôt que directement sur les fichiers et e-mails. Un index est essentiellement un dictionnaire où le programme peut rapidement rechercher pour tout mot donné quels fichiers ou e-mails contiennent ce mot.
Compromis : recherche rapide et création d’index : La recherche basée sur les index est une excellente idée car elle est plusieurs ordres de grandeur plus rapide que la recherche sans index : DocFetcher, DocFetcher Pro et DocFetcher Server peuvent généralement trouver des milliers de fichiers correspondants en moins d’une seconde. Le principal inconvénient est que les index doivent d’abord être créés — un processus connu sous le nom d’indexation — et cela peut prendre du temps selon le nombre total de fichiers et d’e-mails, et leurs tailles individuelles.
Indexation rapide et philosophie « indexer seulement ce dont vous avez besoin » : L’inconvénient d’avoir à créer un index est atténué par le fait que l’indexation dans DocFetcher, DocFetcher Pro et DocFetcher Server est assez rapide : 200 fichiers par minute est une vitesse d’indexation assez normale. De plus, les trois programmes suivent une philosophie « indexer seulement ce dont vous avez besoin » : Dès le départ, rien sur votre ordinateur n’est indexé, et il vous revient entièrement de décider ce qui sera indexé. Ceci contraste avec d’autres logiciels de recherche qui dès le départ gaspillent énormément de temps et de puissance informatique pour indexer pratiquement tout, car ils ne vous font pas confiance pour décider par vous-même. Sans parler des implications de confidentialité de cette approche « indexer tout »…
Création d’index vs. mise à jour d’index : Enfin, l’indexation d’un dossier particulier n’est généralement coûteuse en temps que la première fois, si elle l’est du tout. Par la suite, chaque fois que vous exécutez une mise à jour d’index, le programme sera assez intelligent pour indexer seulement les fichiers nouveaux et modifiés, en ignorant tout le reste. En pratique, généralement seul un nombre relativement petit de fichiers aura été ajouté ou modifié, donc une mise à jour d’index prend généralement peu de temps.
Création d’index
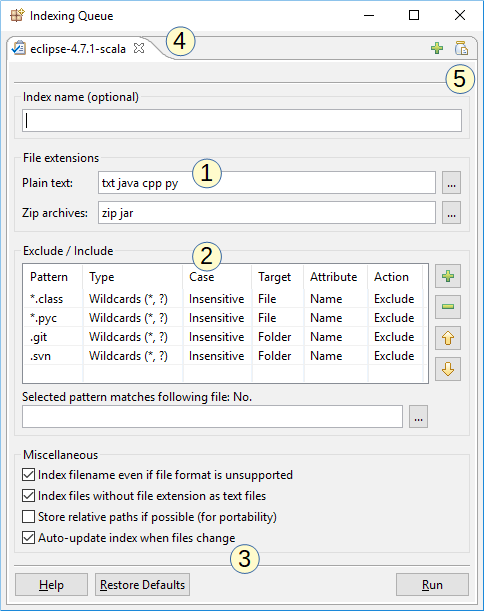
La capture d’écran ci-dessus montre le dialogue d’indexation de DocFetcher Pro. Il s’agit du dialogue de configuration que vous voyez lors de la création d’un nouvel index. Fonctionnalités notables :
- Extensions de texte brut et zip personnalisables : Les extensions de fichier par lesquelles le programme reconnaît les fichiers de texte brut et les archives zip peuvent être personnalisées. La personnalisation des extensions de fichier de texte brut est utile lors du traitement de code source.
- Règles d’inclusion et d’exclusion : Vous pouvez définir des règles pour inclure ou exclure certains fichiers basées sur la correspondance de motifs génériques ou d’expressions régulières. Ce tableau existe aussi dans DocFetcher, mais les motifs génériques et la règle d’inclusion ne sont disponibles que dans DocFetcher Pro et DocFetcher Server. Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Available in DocFetcher Server
- Mise à jour automatique des index : Si la case « Mise à jour automatique de l'index » est cochée, le programme surveillera le dossier indexé pour les changements de fichiers et mettra à jour l’index automatiquement lorsqu’un changement est détecté.
- File d’attente d’indexation : Plusieurs tâches d’indexation peuvent être mises en file d’attente, chaque tâche sur un onglet séparé.
- Sauvegarde et chargement des paramètres d’indexation : Ce bouton « pot » ouvre un menu pour sauvegarder et charger les paramètres d’indexation. Ceci est pratique si vous devez définir beaucoup de règles d’inclusion et d’exclusion. Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Not available in DocFetcher Server
Formats de documents pris en charge
- AbiWord (abw, abw.gz, zabw)
- EPUB (epub)
- FictionBook (fb2, fbz, fb2.zip) Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Available in DocFetcher Server
- FLAC metadata (flac)
- HTML (html, xhtml, …)
- JPEG Exif metadata (jpg, jpeg)
- MP3 metadata (mp3)
- Microsoft Compiled HTML Help (chm)
- Microsoft Office pre-2007 (doc, xls, ppt, …)
- Microsoft Office 2007 and newer (docx, xlsx, pptx, …)
- Microsoft Outlook OST (ost) * Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Available in DocFetcher Server
- Microsoft Outlook PST (pst) *
- Microsoft Visio (vsd, vss, vst, vsw)
- Mobipocket (mobi) — le support est actuellement expérimental Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Available in DocFetcher Server
- OpenDocument (odt, ods, odg, odp, …)
- Portable Document Format (pdf)
- Plain Text (customizable extensions)
- Rich Text Format (rtf)
- Scalable Vector Graphics (svg)
Pour tout format de fichier non inclus dans la liste ci-dessus, au moins le nom de fichier peut être indexé. De plus, tout format de fichier identifiable par une extension de fichier spécifique peut être forcé d’être indexé comme texte brut, car les extensions de fichier de texte brut sont personnalisables.
* Limitations du support des fichiers PST et OST
Pas de prévisualisation d’e-mail : Pour des raisons techniques, ni DocFetcher ni DocFetcher Pro ni DocFetcher Server ne peuvent ouvrir les e-mails dans les résultats de recherche avec Outlook. Les e-mails ne peuvent être affichés que dans le volet de prévisualisation en texte seul du programme. La capacité d’ouvrir les e-mails dans Outlook pourrait être ajoutée dans une future version majeure de DocFetcher Pro (v2.0 ou ultérieure). Elle ne peut pas être implémentée dans DocFetcher Server car l’instance Outlook de l’utilisateur et le fichier PST ou OST contenant l’e-mail résident sur des ordinateurs potentiellement différents.
Préférer PST à OST : Bien que DocFetcher Pro et DocFetcher Server puissent lire les fichiers OST dans une certaine mesure, soyez averti que les fichiers OST ne sont en fait que des fichiers de cache où Outlook stocke temporairement une partie des données d’un compte en ligne pour une utilisation hors ligne. Ainsi, si vous indexez des fichiers OST, vous découvrirez que de nombreux e-mails et pièces jointes que vous vous attendriez à voir ne sont tout simplement pas là. Les fichiers PST sont ce qu’Outlook utilise pour le stockage complet et à long terme des e-mails, donc préférez toujours indexer les fichiers PST plutôt que les fichiers OST lorsque c’est possible. Pour plus d’informations sur les fichiers PST et OST, et des instructions sur comment exporter vers des fichiers PST, consultez cette page de Microsoft.
Fichiers PST et OST volumineux : Pour indexer un fichier PST ou OST, l’application doit charger le fichier entier en RAM. Ainsi, l’indexation de fichiers PST ou OST plus volumineux que la quantité de RAM disponible (par ex., fichier PST de 30 Go vs. 16 Go de RAM) n’est pas prise en charge, et les tentatives de le faire planteront l’application. Pour traiter ce problème, vous pouvez soit exclure le gros fichier PST ou OST de l’indexation, soit améliorer votre RAM. En cas d’amélioration de RAM, notez que la quantité totale de RAM nécessaire est plus grande que le fichier PST ou OST, du fait que le système d’exploitation et d’autres processus occupent une partie de cette RAM.
Avertissement concernant l’indexation au mieux
Comme pratiquement tous les logiciels de recherche, DocFetcher, DocFetcher Pro et DocFetcher Server prennent en charge les divers formats de fichiers listés ci-dessus sur une base de meilleur effort. Cela signifie, par exemple, que si vous essayez d’indexer 10 000 fichiers, le logiciel pourrait réussir à indexer seulement 9 500 fichiers (c’est-à-dire 95 %), tout en échouant sur les 500 fichiers restants. Bien sûr, le taux de réussite réel dépend de votre jeu de données.
De plus, même si un fichier particulier est indexé avec succès, le logiciel peut échouer à extraire du texte dedans, surtout lors du traitement d’anciens formats de fichiers comme « doc » ou « xls ». Par exemple, il peut échouer à extraire certains commentaires de cellules ou métadonnées d’anciens fichiers Excel.
Dans tous les cas, DocFetcher Pro et DocFetcher Server feront très probablement un meilleur travail d’indexation des fichiers que l’ancien DocFetcher.
Si vous voyez un taux d’échec particulièrement élevé pendant l’indexation, n’hésitez pas à signaler le problème, avec quelques fichiers de test attachés. Cependant, il n’y a aucune garantie que le problème puisse être résolu.
Formats d’archives pris en charge
- Archives 7z (7z), jusqu’à la version v0.3 du format 7z
- Archives 7z (7z), jusqu’à la version v0.4 du format 7z (depuis 7-Zip 9.34, du 2014-11-23) Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Available in DocFetcher Server
- Archives Rar (rar) — le format RAR 5.0 n’est pas pris en charge
- Tar and Tar.* archives:
- tar, tar.gz, tgz, tar.bz2, tb2, tbz
- tbz2, tar.lzma, tlz, tar.xz, txz, tar.z, tz Free Not available in the free DocFetcher Pro Available in DocFetcher Pro Server Available in DocFetcher Server
- Archives Zip (extensions personnalisables)
Autres fonctionnalités notables
Multi-plateforme : DocFetcher, DocFetcher Pro et DocFetcher Server peuvent être exécutés sur Windows, Linux et macOS. De plus, DocFetcher Server peut être accédé depuis n’importe quel ordinateur de bureau avec une version à jour de Chrome, Firefox, Safari ou Edge installée.
Version portable : Les paquets DocFetcher Pro pour Windows, Linux et macOS sont chacun fournis en version portable et non portable. La version portable est utile en ce qu’elle vous permet de regrouper DocFetcher Pro portable, ses index et les documents indexés, pour être utilisés de diverses manières :
- Vous pouvez transporter ce paquet sur une clé USB.
- Vous pouvez l’archiver sur un support de sauvegarde.
- Vous pouvez le mettre dans un volume chiffré.
- Vous pouvez le mettre dans un lecteur cloud et le synchroniser entre ordinateurs.
Veuillez noter que redistribuer de tels paquets portables à d’autres utilisateurs n’est pas autorisé avec DocFetcher Pro, car chaque copie achetée est liée à un seul utilisateur. (Chaque utilisateur receveur devrait acheter sa propre copie.) La redistribution est autorisée avec le DocFetcher open source, cependant.
Support Unicode : DocFetcher, DocFetcher Pro et DocFetcher Server viennent avec un support Unicode solide comme le roc pour tous les formats majeurs, incluant Microsoft Office, OpenDocument, PDF, HTML, RTF et les fichiers de texte brut.
Indexation de lecteurs réseau : DocFetcher, DocFetcher Pro et DocFetcher Server peuvent indexer les lecteurs réseau ainsi que les lecteurs cloud. Plus généralement, si une structure de données peut être montée comme quelque chose qui ressemble à un système de fichiers dans l’OS, alors les trois programmes peuvent l’indexer.
Détection de paires HTML : Pendant l’indexation, DocFetcher, DocFetcher Pro et DocFetcher Server détectent les paires de fichiers HTML (par ex., un fichier nommé exemple.html et un dossier nommé exemple_files), et traitent chaque paire comme un seul document. Cette fonctionnalité peut sembler plutôt inutile au début, mais il s’est avéré que cela améliore considérablement la qualité des résultats de recherche lors du traitement de fichiers HTML, car tout le « fouillis » à l’intérieur des dossiers HTML disparaît des résultats.