Modernisering af mønstertabel
Mønstertabellen i indekseringsdialogen i DocFetcher Pro og mønstertabellen i indekseringspanelet i DocFetcher Server adskiller sig fra den i DocFetcher på følgende måder:
- Ud over regulære udtryk kan du bruge de mindre kraftfulde, men også meget simplere jokertegn * og ? til at skrive matchende regler. Jokertegnet * er en pladsholder for nul eller flere tegn, mens jokertegnet ? er en pladsholder for præcis ét tegn.
- En ny »Indekludér« handling ud over »Udeluk« handlingen.
- »Detect mime type« handlingen er forsvundet. Hvis du ønsker at indeksere filer uden filendelse som tekstfiler, brug checkboxen med samme beskrivelse under mønstertabellen.
- Matching kan enten være forskel på store og små bogstaver (case-sensitive) eller uden forskel på store og små bogstaver (case-insensitive). I DocFetcher derimod er matching altid case-sensitive.
- Matching kan udføres ikke kun mod almindelige filer, men også mod mapper og arkivfiler.
- På Windows, når regler matches mod filstier, vil sidstnævnte bruge tegnet \ som sti-separator, ikke tegnet /. Eksempel: C:\Sti\Til\Fil.docx, i stedet for C:/Sti/Til/Fil.docx.
Som resultat ser mønstertabellen i DocFetcher Pro sådan ud:
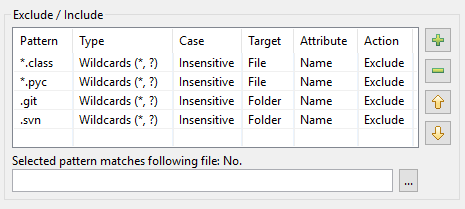
Mønstertabellen i DocFetcher Server ser ens ud, men »Valgte mønster matcher følgende fil« test-widgetten under tabellen er i øjeblikket ikke tilgængelig. Server Not available in DocFetcher Server
Klik her for en detaljeret diskussion af mønstertabellen i DocFetcher, DocFetcher Pro og DocFetcher Server.
Sådan kom moderniseringen af mønstertabellen i DocFetcher Pro og DocFetcher Server til. Lad os starte fra begyndelsen: I indekseringsdialogen i DocFetcher er der en mønstertabel til at udføre visse handlinger på filer, der matcher visse mønstre under indeksering:
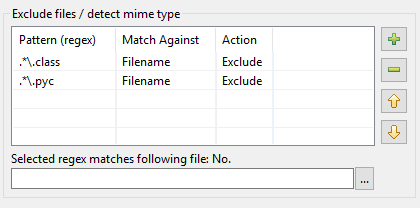
Mønstrene skal være såkaldte regulære udtryk, og hvad angår handlinger, er to tilgængelige i DocFetcher: Udelukkelse af den matchede fil fra indeksering, og »mime-type detektion«, dvs. forsøg på at gætte den korrekte måde at parse den matchede fil baseret på filens indhold snarere end baseret på dens filnavn. Så langt, så godt. I praksis viser det sig imidlertid, at ovenstående implementering har en række problemer:
- Meget få mennesker ved, hvordan man skriver regulære udtryk.
- Nogle gange ønsker man kun at indeksere kun bestemte filer og ikke unødigt spilde indekseringstid på noget andet. For eksempel indeksere kun »txt« filer og intet andet. DocFetcher kan faktisk gøre dette, men det involverer nogle ret avancerede regulære udtryk-tricks.
- Nogle gange ønsker man at udelukke fra indeksering alle filer, der matcher et bestemt mønster, undtagen alle filer, der matcher et bestemt andet mønster. For eksempel udelukke fra indeksering alle PDF-filer, undtagen PDF-filer, hvis navne starter med »rapport_«. Igen, i DocFetcher kræver dette avanceret brug af regulære udtryk.
- Generelt er mime-type detektion ret ubrugelig fordi: (1) Filendelsen er næsten altid korrekt og derfor i de fleste tilfælde alt, hvad der behøves for at finde ud af filformatet. (2) Når filendelsen ikke er korrekt og mime-type detektion er nødvendig, viser sidstnævnte sig ikke at være særlig pålidelig alligevel. (3) Ingen gider og/eller ved, hvordan man skriver matchende regler for de sjældne tilfælde, hvor mime-type detektion faktisk ville være nødvendig. Imidlertid viser det sig, at mime-type detektion har én vigtig anvendelse i forbindelse med DocFetcher: At få programmet til at behandle filer uden filendelse som almindelige tekstfiler, f.eks. filer navngivet README. Imidlertid imidlertid, for at opnå dette, skal man skrive dette obskure regulære udtryk: [^.]*
- Mime-type detektion kan fejle med at identificere en fil som ren tekst, hvis filen indeholder nogle binære data.
- På grund af det faktum, at den bærbare version af DocFetcher skal køre på alle understøttede platforme, når matchende regler mod filstier, bruger sidstnævnte altid tegnet / som sti-separator, selv på Windows, hvilket er ret kontraintuitivt for de fleste Windows-brugere.
Kort sagt, DocFetcher’s mønstertabel er et rod, og omskrivningen, der kom med DocFetcher Pro, var en god mulighed for at rydde det hele op:
- Jokertegn blev tilføjet og er sat som standard, så nu kan selv almindelige dødelige skrive matchende regler.
- »Indekludér« handlingen dækker både tilfældet, hvor man ønsker at indeksere kun en bestemt type fil, og tilfældet, hvor man ønsker at definere undtagelser til matchende regler. Selv undtagelser-til-undtagelser er nu mulige.
- Den generelt ubrugelige »Detect mime type« handling er forsvundet, og dens hovedanvendelse, indeksering af filer uden filendelse som tekstfiler, er dækket af en simpel checkbox under mønstertabellen. Og denne checkbox virker, selvom filen indeholder nogle binære data.
- Windows sti-separator problemet er løst.
- Og nogle andre ting (case sensitivity og matching mod filer/mapper/arkiver) blev kastet ind for god ordens skyld.
Indlæsning og gemning af indekseringsindstillinger
Bemærk: Denne funktion er i øjeblikket kun tilgængelig i DocFetcher Pro, ikke i DocFetcher Server. Server Not available in DocFetcher Server
Problemet: I DocFetcher skal du hver gang du opretter et nyt indeks indtaste alle regler i mønstertabellen en efter en. Dette bliver ret kedeligt, hvis du har mange sådanne regler. Der er bare ingen måde at indlæse og gemme dem.
I DocFetcher Pro er ovenstående problem løst som følger: I øverste højre hjørne af indekseringsdialogen i DocFetcher Pro sidder der en umærkelig lille »krukke med dokument« knap. Klik på denne knap åbner en menu, der indeholder forskellige handlinger til indlæsning og gemning af indekseringsindstillinger:
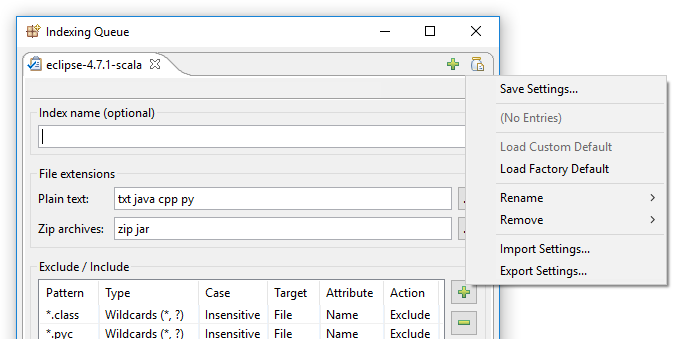
Klik på »Gem indstillinger« åbner denne dialog:
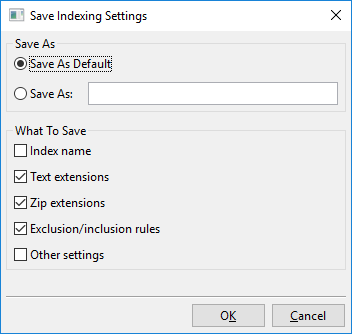
I det væsentlige kan du med denne dialog enten gemme de aktuelt synlige indekseringsindstillinger til et nyt navngivet slot, f.eks. »Mine nye indekseringsindstillinger«, eller gemme de aktuelt synlige indekseringsindstillinger som den nye standard.
Denne standard kaldes »Brugerdefineret standard« og vil blive indlæst automatisk, når der oprettes nye indekser. Der er også en »Fabrikstandard«, som er den standard, DocFetcher Pro bruger ud af boksen. De navngivne indstillinger, du oprettede, nemlig »Brugerdefineret standard« og »Fabrikstandard«, kan alle indlæses via menuen vist ovenfor.
For at afrunde tingene giver menuen dig også mulighed for at importere og eksportere alle dine indekseringsindstillinger, så du kan genbruge dem, når du opsætter DocFetcher Pro i et nyt miljø.
Andre bemærkelsesværdige forbedringer
FB2 support: DocFetcher Pro og DocFetcher Server har support for e-bog formatet FB2. Zip-komprimerede FB2-filer med filendelse fb2.zip eller fbz er understøttet »nativt«, dvs. DocFetcher Pro og DocFetcher Server ser hver sådan fil som en enkelt fil snarere end som en fil pakket ind i et zip-arkiv.
Eksperimentel Mobipocket support: DocFetcher Pro og DocFetcher Server har support for e-bog formatet Mobipocket med filendelse »mobi«. Bemærk dog, at mens DocFetcher Pro og DocFetcher Server generelt gør et ret godt stykke arbejde med at uddrage tekst fra mobi-filer, fejler de i øjeblikket enten med at uddrage en lille del af teksten i slutningen af filen, eller i nogle tilfælde fejler de helt. Derfor er Mobipocket support for nu mærket som eksperimentel.
7z arkiv support for det nuværende v0.4 format: DocFetcher kan læse 7z arkiver op til v0.3 af 7z arkiv formatet. DocFetcher Pro og DocFetcher Server kan også læse 7z arkiver i det nuværende v0.4 format. Dette v0.4 format blev introduceret med 7-Zip 9.34, udgivet 2014-11-23.
Udvidet tar arkiv support: DocFetcher understøtter følgende tar arkiv endelser: tar, tar.gz, tgz, tar.bz2, tb2, tbz. DocFetcher Pro og DocFetcher Server understøtter desuden følgende tar arkiv endelser: tbz2, tar.lzma, tlz, tar.xz, txz, tar.z, tz
Indeksering af mappe- og arkivnavne: I modsætning til DocFetcher indekserer DocFetcher Pro og DocFetcher Server ikke kun almindelige filer, men også mapper og arkivfiler — eller mere præcist, navnene på mapper og arkivfiler. Således vil mapper og arkivfiler dukke op i søgeresultaterne for DocFetcher Pro og DocFetcher Server. Der er også et Beholdertyper panel på venstre side af hovedapplikationsvinduet til at udelukke mapper og/eller arkiver fra søgeresultaterne.
MacOS: Dæmon til automatisk indeksopdatering: DocFetcher og DocFetcher Pro er i stand til automatisk indeksopdatering, dvs. i stedet for at skulle starte indeksopdateringer manuelt, startes indeksopdateringer af programmet, så snart filændringer opdages. Denne funktionalitet er dog kun tilgængelig, mens de to programmer faktisk kører. Når de ikke kører, kræves en separat dæmon-proces for at fylde hullet. I DocFetcher er dæmonen kun tilgængelig på Windows og Linux, hvorimod den i DocFetcher Pro også er tilgængelig på macOS. Hvad angår DocFetcher Server, er ingen dæmon nødvendig, da serveren er designet til at køre kontinuerligt. Server Not available in DocFetcher Server
Smartere filnavn indeksering: Indeksering af filnavne i DocFetcher Pro og DocFetcher Server er smartere end i DocFetcher. For eksempel, hvis DocFetcher støder på en fil navngivet find_denne_fil.pdf, ser den »find_denne_fil« som et enkelt ord, ikke som tre separate ord sammenkædet. Således vil DocFetcher kun finde denne fil, hvis du bogstaveligt talt skriver »find_denne_fil« i DocFetcher’s søgefelt. DocFetcher Pro og DocFetcher Server på den anden side vil finde filen, hvis du skriver »find_denne_fil« eller et af de tre individuelle ord. Generelt set genkender DocFetcher Pro og DocFetcher Server tegn som understregen som potentielle ordseparatorer.

Filnavn indeksering i tilfælde af fejl: Hvis DocFetcher Pro og DocFetcher Server fejler med at læse indholdet af en fil på grund af en fejl eller på grund af adgangskodebeskyttelse, bliver filnavnet stadig indekseret. I DocFetcher på den anden side bliver filen helt sprunget over.
Ingen fejl med dybt indlejrede mappestrukturer: Når man prøver at indeksere dybt indlejrede mappestrukturer, såsom C:\mappe1\mappe2\...\mappe99\mappe100, er DocFetcher tilbøjelig til at fejle med en »Mappehierarki er for dybt« fejl. I programmer jargon kaldes dette et »stack overflow«. DocFetcher Pro og DocFetcher Server på den anden side er helt immune over for denne type fejl.
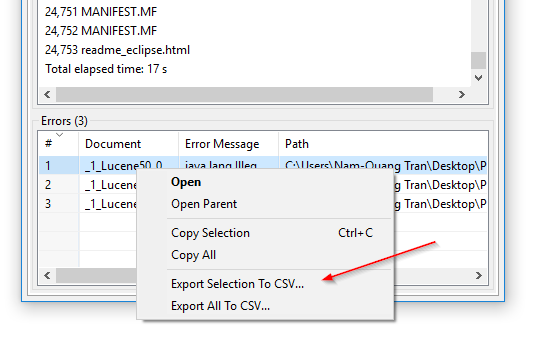
CSV eksport af indekseringsfejl: I DocFetcher Pro kan du eksportere tabellen over filer, som programmet ikke kunne læse under indeksering, til en CSV-fil. Dette kan gøres via kontekstmenuen for fejltabellen, som vist i følgende skærmbillede. Denne funktion er i øjeblikket ikke tilgængelig i DocFetcher Server. Server Not available in DocFetcher Server
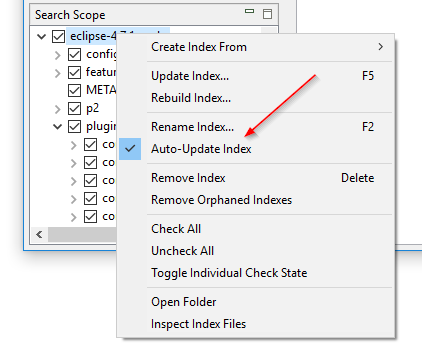
Tænding og slukning af mappeovervågning uden genopbygning af indekset: DocFetcher’s »Watch folders for file changes« indstilling, også kendt som mappeovervågning, er en pr-indeks indstilling, der når den er tændt får programmet til automatisk at opdatere indekset, når det opdager filændringer i den indekserede mappe. Problemet er, at hvis du vil tænde eller slukke for denne indstilling på et bestemt indeks, skal du genopbygge hele indekset. I DocFetcher Pro kan du tænde og slukke for denne indstilling uden at genopbygge indekset, via kontekstmenuen for Search Scope panelet. Desuden er indstillingen blevet omdøbt til »Opdater indeks automatisk«. Lignende funktionalitet findes i DocFetcher Server.
Samtidig søgning og indeks genopbygning: I DocFetcher, hvis du vælger at genopbygge et indeks, bliver det indeks utilgængeligt for søgning, mens genopbygningen er i gang. I DocFetcher Pro og DocFetcher Server på den anden side forbliver indekset søgbart under genopbygningen. (Mere præcist forbliver en gammel kopi af indekset søgbar, mens det faktiske indeks bliver genopbygget i baggrunden.)
Windows: Rettet håndtering af UNC-stier: I DocFetcher er håndteringen af UNC-stier på Windows slemt ødelagt og blev redesignet fra bunden i DocFetcher Pro. Redesignet blev derefter overført til DocFetcher Server.
Non-modal indekseringsdialog: I modsætning til DocFetcher’s indekseringsdialog er den i DocFetcher Pro »non-modal«, hvilket betyder, at den ikke er tilknyttet hovedprogramvinduet og ikke blokerer input til hovedprogramvinduet, mens den er åben. Den vigtigste fordel ved dette er, at mens indekseringsprocesser kører, kan du minimere hovedprogramvinduet, men holde indekseringsdialogen synlig og parkeret på siden. Dette giver dig mulighed for at holde øje med indekseringsprocesserne, mens du udfører arbejde i andre applikationer. Denne funktion er ikke anvendelig på DocFetcher Server. Server Not available in DocFetcher Server
Afspilning af lyd efter indeksering: Som standard afspiller DocFetcher Pro en »færdig« lyd efter indeksering. Dette kan slås fra i indstillingerne. Denne funktion er i øjeblikket ikke tilgængelig i DocFetcher Server. Server Not available in DocFetcher Server
Indeksering af japansk tekst: DocFetcher har en såkaldt »Ordsegmentering« mulighed for at få brugbare søgeresultater, når der indekseres kinesisk tekst. DocFetcher Pro har en ekstra ordsegmenteringsmulighed til håndtering af japansk tekst. Både kinesisk og japansk ordsegmentering er i øjeblikket ikke tilgængelige i DocFetcher Server. Server Not available in DocFetcher Server