Overhaul of Pattern Table
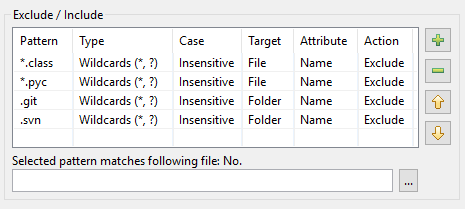
The pattern table on the indexing dialog of DocFetcher Pro and pattern table on the indexing pane of DocFetcher Server differ from the one in DocFetcher in the following ways:
- In addition to regular expressions, you can use the less powerful, but also much simpler wildcards
*and?to write matching rules. The wildcard*is a placeholder for zero or more characters, while the wildcard?is a placeholder for exactly one character. - A new “Include” action in addition to the “Exclude” action.
- The “Detect mime type” action is gone. If you want to index files without file extension as text files, use the checkbox of the same description below the pattern table.
- Matching can be either case-sensitive or case-insensitive. In DocFetcher on the other hand, matching is always case-sensitive.
- Matching can be performed not only against ordinary (non-archive) files, but also against folders and archive files.
- On Windows, when matching against file paths rather than filenames, the file paths will use
\as path separator, not/. Example:C:\Path\To\File.docx, instead ofC:/Path/To/File.docx.
As a result, this is what the pattern table in DocFetcher Pro looks like:
The pattern table in DocFetcher Server looks the same, but the “Selected pattern matches following file” test widget below the table is currently not available. Server
Click here for a detailed discussion of the pattern table in DocFetcher, DocFetcher Pro and DocFetcher Server.
Here’s how the overhaul of the pattern table in DocFetcher Pro and DocFetcher Server came about. Let’s start from the beginning: On the indexing dialog of DocFetcher, there’s a pattern table for performing certain actions on files matched by certain patterns during indexing:
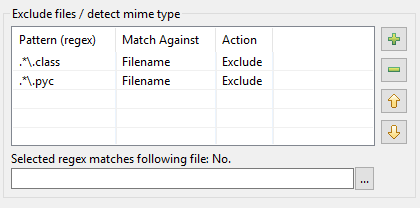
The patterns need to be so-called regular expressions, and as for actions, two are available in DocFetcher: Excluding the matched file from indexing, and “mime-type detection”, i.e., trying to guess the correct way to parse the matched file based on the file’s contents rather than based on its filename. So far, so good. However, in practice it turns out the above implementation has a number of issues:
- Very few people know how to write regular expressions.
- Sometimes one wants to index only certain files, and not needlessly waste indexing time on anything else. For instance, index only “txt” files and nothing else. DocFetcher can actually do this, but it involves some fairly advanced regular expression trickery.
- Sometimes one wants to exclude from indexing all files matching a certain pattern, except all files matching a certain other pattern. For instance, exclude from indexing all PDF files, except PDF files whose names start with “report_”. Again, in DocFetcher this requires advanced use of regular expressions.
- In general, mime-type detection is pretty useless because: (1) The file extension is almost always correct and therefore in most cases all that’s needed to figure out the file format. (2) When the file extension is not correct and mime-type detection is needed, the latter turns out to be not particularly reliable anyway. (3) Nobody bothers to and/or knows how to write matching rules for those rare case where mime-type detection would be actually needed. However, in the context of DocFetcher it turns out that mime-type detection does have one important use case: Making the program treat files without file extension as plain text files, e.g., files named
README. However however, to pull this off, one needs to write this obscure regular expression:[^.]* - Mime-type detection may fail to identify a file as plain text if the file contains some binary data.
- Due to an implementation quirk (the portable version of DocFetcher has to run on all supported platforms), when matching against file paths rather than filenames, the file paths always use
/as path separator, even on Windows, which is quite counter-intuitive for most Windows users.
Long story short, DocFetcher’s pattern table is a hot mess, and the rewrite that came with DocFetcher Pro was a good opportunity to clean it all up:
- Wildcards were added and are set as the default so that now even mere mortals can write matching rules.
- The “Include” action covers both the case where one wants to index only a specific kind of file, and the case where one wants to define exceptions to matching rules. Even exceptions-to-exceptions are now possible.
- The generally useless mime-type detection action is gone, and its main use case, indexing files without file extension as text files, is covered by a simple checkbox below the pattern table. And this checkbox works even if the file contains some binary data.
- The Windows path separator issue is fixed.
- And some other stuff (case sensitivity and matching against files/folders/archives) was thrown in for good measure.
Loading and Saving Indexing Settings
Note: This feature is currently only available in DocFetcher Pro, not in DocFetcher Server. Server
The problem: In DocFetcher, every time you create a new index, you have to enter all rules in the pattern table one by one. This becomes quite tedious if you have many such rules. There’s just no way to load and save them.
In DocFetcher Pro, the above problem is solved as follows: In the top right corner of the indexing dialog of DocFetcher Pro, there sits an inconspicuous little “jar with document” button. Clicking this button opens a menu containing various actions for loading and saving indexing settings:
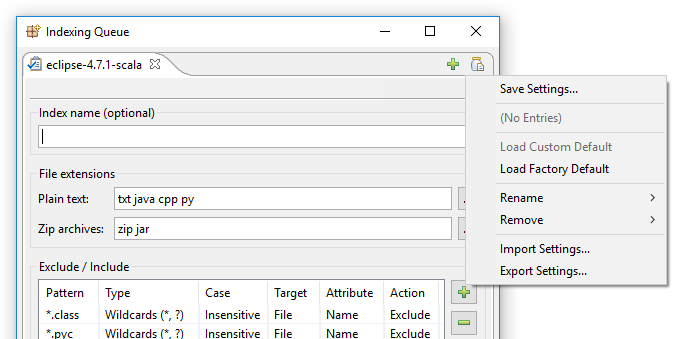
Clicking on “Save Settings…” opens this dialog:
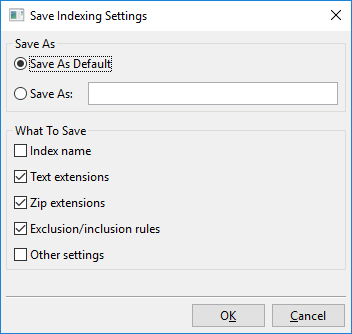
Essentially, what you can do with this dialog is either save the currently visible indexing settings to a new named slot, e.g., “My New Indexing Settings”, or save the currently visible indexing settings as the new default.
This default is called “Custom Default” and will be loaded automatically when creating new indexes. There’s also a “Factory Default”, which is the default DocFetcher Pro uses out of the box. The named settings you created, the Custom Default settings and the Factory Default settings can all be loaded via the menu shown above.
To round things off, the menu also allows you to import and export all of your indexing settings so you can reuse them when setting up DocFetcher Pro in a new environment.
Other Notable Improvements
FB2 support: DocFetcher Pro and DocFetcher Server have support for the e-book format FB2. Zip-compressed FB2 files, with file extension fb2.zip or fbz, are supported “natively”, i.e., DocFetcher Pro and DocFetcher Server see each such file as a single file rather than as a file wrapped in a zip archive.
Experimental Mobipocket support: DocFetcher Pro and DocFetcher Server have support for the e-book format Mobipocket, with file extension “mobi”. However, note that while DocFetcher Pro and DocFetcher Server overall do a pretty solid job of extracting text from mobi files, they currently either fail to extract a small portion of text at the end of the file, or in some cases fail completely. Hence, Mobipocket support is for now marked as experimental.
7z archive support for the current v0.4 format: DocFetcher can read 7z archives up to v0.3 of the 7z archive format. DocFetcher Pro and DocFetcher Server can also read 7z archives in the current v0.4 format. This v0.4 format was introduced with 7-Zip 9.34, released in 2014-11-23.
Expanded tar archive support: DocFetcher supports the following tar archive extensions: tar, tar.gz, tgz, tar.bz2, tb2, tbz. DocFetcher Pro and DocFetcher Server additionally support the following tar archive extensions: tbz2, tar.lzma, tlz, tar.xz, txz, tar.z, tz
Indexing folder and archive names: Unlike DocFetcher, DocFetcher Pro and DocFetcher Server index not only regular non-archive files, but also folders and archive files – or more precisely, the names of folders and archive files. Thus, folders and archive files will show up in the search results of DocFetcher Pro and DocFetcher Server. There’s also a Container Types pane on the left side of the main application window to exclude folders and/or archives from the search results.
MacOS: Daemon for automatic index updating: DocFetcher and DocFetcher Pro are capable of automatic index updating, i.e., instead of having to start index updates manually, index updates are started by the program as soon as file changes are detected. However, this functionality is only available while the two programs are actually running. When they aren’t running, a separate daemon process is needed to fill the gap. In DocFetcher, the daemon is only available on Windows and Linux, whereas in DocFetcher Pro, it is also available on macOS. As for DocFetcher Server, no daemon is needed since the server is expected to run continuously. Server
Smarter filename indexing: Indexing of filenames in DocFetcher Pro and DocFetcher Server is smarter than in DocFetcher. For instance, if DocFetcher encounters a file named find_this_file.pdf, it sees “find_this_file” as a single word, not as three separate words stringed together. Thus, DocFetcher will only find this file if you literally type in “find_this_file” in DocFetcher’s search field. DocFetcher Pro and DocFetcher Server on the other hand will find the file if you type in “find_this_file” or any of the three individual words. Generally speaking, what DocFetcher Pro and DocFetcher Server do is recognize characters like the underscore as potential word separators.

Filename indexing in case of errors: If DocFetcher Pro and DocFetcher Server fail to read the contents of a file due to some error or because of password protection, the filename still gets indexed. In DocFetcher on the other hand, the file is skipped altogether.
No errors with deeply nested folder structures: When trying to index deeply nested folder structures, such as C:\folder1\folder2\...\folder99\folder100, DocFetcher is prone to fail with a “Folder hierarchy is too deep” error. In programmer jargon, this is an instance of a “stack overflow”. DocFetcher Pro and DocFetcher Server on the other hand are completely immune to this kind of error.
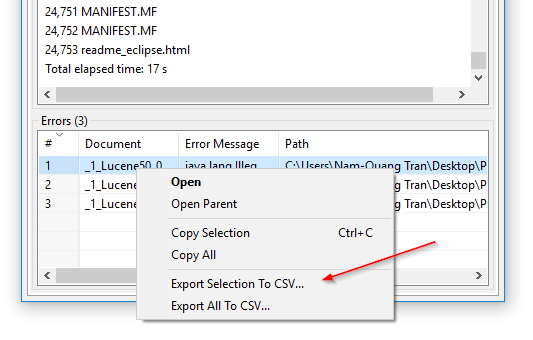
CSV export of indexing errors: In DocFetcher Pro, you can export the table of files the program failed to read during indexing to a CSV file. This can be done via the context menu of the error table, as shown in the following screenshot. This feature is currently not available in DocFetcher Server. Server
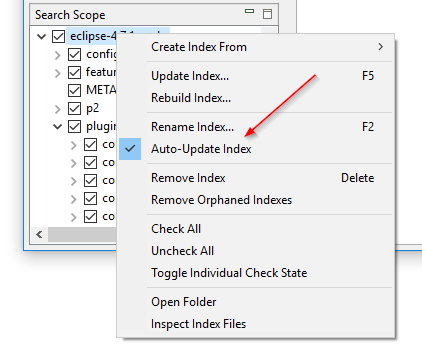
Turning folder watching on and off without rebuilding the index: DocFetcher’s “Watch folders for file changes” setting, also known as folder watching, is a per-index setting that when turned on makes the program auto-update the index whenever it detects file changes in the indexed folder. The problem is that if you want to turn this setting on or off on a particular index, you have to rebuild the entire index. In DocFetcher Pro, you can turn this setting on and off without rebuilding the index, via the context menu of the Search Scope pane. Also, the setting has been renamed to “Auto-Update Index”. Similar functionality exists in DocFetcher Server.
Simultaneous searching and index rebuilding: In DocFetcher, if you choose to rebuild an index, that index becomes unavailable for searching while the rebuilding is in progress. In DocFetcher Pro and DocFetcher Server on the other hand, the index remains searchable during the rebuild. (More precisely, an old copy of the index remains searchable while the actual index is being rebuilt in the background.)
Windows: Fixed handling of UNC paths: In DocFetcher, the handling of UNC paths on Windows is badly broken and was redesigned from scratch in DocFetcher Pro. The redesign was then carried over to DocFetcher Server.
Non-modal indexing dialog: In contrast to DocFetcher’s indexing dialog, the one in DocFetcher Pro is “non-modal”, meaning it’s not attached to the main program window and doesn’t block input to the main program window while it’s open. The main benefit of this is that while indexing processes are running, you can minimize the main program window, but keep the indexing dialog visible and parked on the side. This allows you to keep an eye on the indexing processes while doing work in other applications. This feature is not applicable to DocFetcher Server. Server
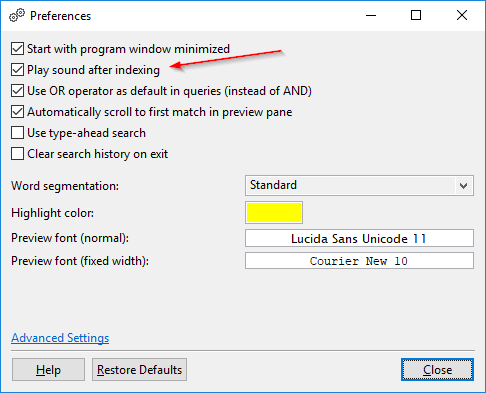
Playing a sound after indexing: By default, DocFetcher Pro plays a “finished” sound after indexing. This can be turned off in the preferences. This feature is currently not available in DocFetcher Server. Server