< zurück zur übergeordneten Seite
Überarbeitung der Mustertabelle
Die Mustertabelle im Indizierungsdialog von DocFetcher Pro und die Mustertabelle im Indizierungsbereich von DocFetcher Server unterscheiden sich von der in DocFetcher in folgender Weise:
- Zusätzlich zu regulären Ausdrücken können Sie die weniger leistungsfähigen, aber auch viel einfacheren Platzhalter * und ? verwenden, um Übereinstimmungsregeln zu schreiben. Der Platzhalter * steht für null oder mehr Zeichen, während der Platzhalter ? für genau ein Zeichen steht.
- Eine neue Aktion „Einbeziehen“ zusätzlich zur Aktion „Ausschließen“.
- Die Aktion „MIME-Typ detektieren“ ist entfallen. Wenn Sie Dateien ohne Dateiendung als Textdateien indizieren möchten, verwenden Sie das Kontrollkästchen mit der gleichen Beschreibung unterhalb der Mustertabelle.
- Die Übereinstimmung kann wahlweise Groß- und Kleinschreibung berücksichtigen oder ignorieren. In DocFetcher hingegen wird die Groß- und Kleinschreibung immer berücksichtigt.
- Die Übereinstimmung kann nicht nur mit gewöhnlichen (nicht archivierten) Dateien, sondern auch mit Ordnern und Archivdateien durchgeführt werden.
- Unter Windows wird beim Abgleich von Regeln mit Dateipfaden in letzteren das Zeichen \ als Pfadtrennzeichen verwendet, nicht das Zeichen /. Beispiel: C:\Pfad\Zu\Datei.docx anstelle von C:/Pfad/Zu/Datei.docx.
Infolgedessen sieht die Mustertabelle in DocFetcher Pro so aus:
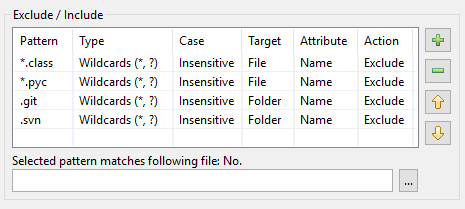
Die Mustertabelle in DocFetcher Server sieht genauso aus, aber das Test-Widget „Ausgewähltes Muster stimmt mit folgender Datei überein“ unterhalb der Tabelle ist derzeit nicht verfügbar. Server Not available in DocFetcher Server
Klicken Sie hier für eine detaillierte Erläuterung der Mustertabelle in DocFetcher, DocFetcher Pro und DocFetcher Server.
Hier wird erklärt, wie die Überarbeitung der Mustertabelle in DocFetcher Pro und DocFetcher Server zustande kam. Beginnen wir von vorne: Im Indizierungsdialog von DocFetcher gibt es eine Mustertabelle, mit der während der Indizierung bestimmte Aktionen für Dateien ausgeführt werden können, die bestimmten Mustern entsprechen:
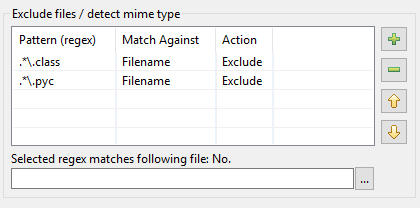
Die Muster müssen sogenannte reguläre Ausdrücke sein, und was die Aktionen betrifft, stehen in DocFetcher zwei zur Verfügung: Das Ausschließen der übereinstimmenden Datei von der Indizierung und die „MIME-Typ-Erkennung“, d.h. der Versuch, die richtige Art der Analyse der übereinstimmenden Datei basierend auf dem Inhalt der Datei und nicht auf ihrem Dateinamen zu erraten. Soweit, so gut. In der Praxis stellt sich jedoch heraus, dass die obige Implementierung eine Reihe von Problemen aufweist:
- Nur sehr wenige Menschen wissen, wie man reguläre Ausdrücke schreibt.
- Manchmal möchte man nur bestimmte Dateien indizieren und nicht unnötig Zeit für die Indizierung anderer Dateien verschwenden. Beispielsweise nur „txt“-Dateien indizieren und sonst nichts. DocFetcher kann das zwar, aber dazu sind einige fortgeschrittene Tricks mit regulären Ausdrücken erforderlich.
- Manchmal möchte man alle Dateien, die einem bestimmten Muster entsprechen, von der Indizierung ausschließen, außer allen Dateien, die einem bestimmten anderen Muster entsprechen. Beispielsweise alle PDF-Dateien von der Indizierung ausschließen, außer PDF-Dateien, deren Namen mit „bericht_“ beginnen. Auch hier erfordert dies in DocFetcher eine fortgeschrittene Verwendung von regulären Ausdrücken.
- Im Allgemeinen ist die MIME-Typ-Erkennung ziemlich nutzlos, weil: (1) Die Dateiendung ist fast immer korrekt und daher in den meisten Fällen alles, was benötigt wird, um das Dateiformat zu ermitteln. (2) Wenn die Dateiendung nicht korrekt ist und eine MIME-Typ-Erkennung erforderlich ist, stellt sich heraus, dass letztere ohnehin nicht besonders zuverlässig ist. (3) Niemand bemüht sich und/oder weiß, wie man Übereinstimmungsregeln für diese seltenen Fälle schreibt, in denen die MIME-Typ-Erkennung tatsächlich benötigt würde. Allerdings stellt sich im Zusammenhang mit DocFetcher heraus, dass die MIME-Typ-Erkennung doch einen wichtigen Anwendungsfall hat: Das Programm dazu zu bringen, Dateien ohne Dateiendung als einfache Textdateien zu behandeln, z.B. Dateien mit dem Namen README. Allerdings allerdings muss man dafür diesen obskuren regulären Ausdruck schreiben: [^.]*
- Die MIME-Typ-Erkennung kann daran scheitern, eine Datei als Klartext zu identifizieren, wenn die Datei binäre Daten enthält.
- Aufgrunddessen, dass die portable Version von DocFetcher auf allen unterstützten Plattformen laufen muss, verwenden die Dateipfade beim Abgleich mit Regeln immer das Zeichen / als Pfadtrennzeichen, auch unter Windows, was für die meisten Windows-Benutzer ziemlich kontraintuitiv ist.
Kurz gesagt, die Mustertabelle von DocFetcher ist ein heilloses Durcheinander, und die Neuimplementierung, die mit DocFetcher Pro kam, war eine gute Gelegenheit, alles aufzuräumen:
- Es wurden Platzhalter hinzugefügt und als Standard festgelegt, so dass jetzt auch normale Sterbliche Übereinstimmungsregeln schreiben können.
- Die Aktion „Einbeziehen“ deckt sowohl den Fall ab, in dem man nur eine bestimmte Art von Datei indizieren möchte, als auch den Fall, in dem man Ausnahmen von Übereinstimmungsregeln definieren möchte. Sogar Ausnahmen von Ausnahmen sind jetzt möglich.
- Die allgemein nutzlose Aktion „MIME-Typ detektieren“ ist verschwunden, und ihr Hauptanwendungsfall, die Indizierung von Dateien ohne Dateiendung als Textdateien, wird durch ein einfaches Kontrollkästchen unter der Mustertabelle abgedeckt. Und dieses Kontrollkästchen funktioniert auch, wenn die Datei einige binäre Daten enthält.
- Das Problem mit dem Windows-Pfadtrennzeichen ist behoben.
- Und einige andere Dinge (Groß- und Kleinschreibung und Übereinstimmung mit Dateien/Ordnern/Archiven) wurden zur Abrundung hinzugefügt.
Laden und Speichern von Indizierungseinstellungen
Hinweis: Diese Funktion ist derzeit nur in DocFetcher Pro verfügbar, nicht in DocFetcher Server. Server Not available in DocFetcher Server
Das Problem: In DocFetcher müssen Sie jedes Mal, wenn Sie einen neuen Index erstellen, alle Regeln in der Mustertabelle einzeln eingeben. Dies wird ziemlich mühsam, wenn Sie viele solcher Regeln haben. Es gibt einfach keine Möglichkeit, sie zu laden und zu speichern.
In DocFetcher Pro wird das obige Problem wie folgt gelöst: In der oberen rechten Ecke des Indizierungsdialogs von DocFetcher Pro befindet sich eine unscheinbare kleine Schaltfläche mit dem Symbol „Glas mit Dokument“. Ein Klick auf diese Schaltfläche öffnet ein Menü mit verschiedenen Aktionen zum Laden und Speichern von Indizierungseinstellungen:
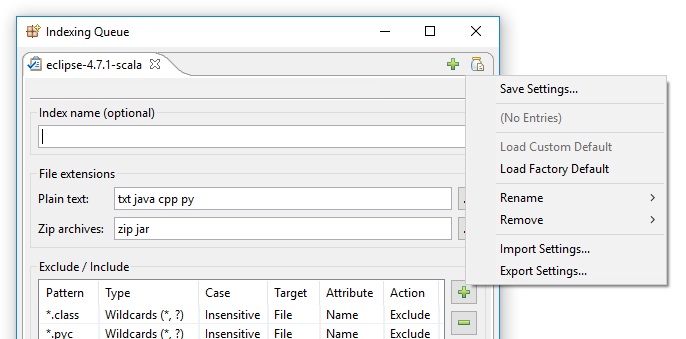
Ein Klick auf „Einstellungen speichern“ öffnet diesen Dialog:
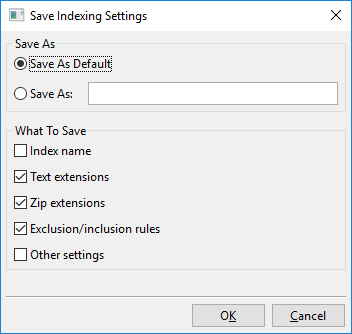
Im Wesentlichen können Sie mit diesem Dialog entweder die aktuell sichtbaren Indizierungseinstellungen unter einem Namen speichern, z.B. „Meine neuen Indizierungseinstellungen“, oder die aktuell sichtbaren Indizierungseinstellungen als neue Standardeinstellung festlegen.
Diese Standardeinstellung wird „Benutzerdefinierte Standardeinstellungen“ genannt und wird automatisch geladen, wenn neue Indizes erstellt werden. Es gibt auch „Werkseinstellungen“, die DocFetcher Pro standardmäßig verwendet. Die von Ihnen erstellten benannten Einstellungen, also „Benutzerdefinierte Standardeinstellungen“ und „Werkseinstellungen“, können alle über das oben gezeigte Menü geladen werden.
Um das Ganze abzurunden, ermöglicht das Menü auch den Import und Export all Ihrer Indizierungseinstellungen, so dass Sie sie bei der Einrichtung von DocFetcher Pro in einer neuen Umgebung wiederverwenden können.
Weitere wichtige Verbesserungen
FB2-Unterstützung: DocFetcher Pro und DocFetcher Server unterstützen das E-Book-Format FB2. ZIP-komprimierte FB2-Dateien mit der Dateiendung fb2.zip oder fbz werden „nativ“ unterstützt, d.h. DocFetcher Pro und DocFetcher Server behandeln jede solche Datei als eigenständige Datei und nicht als in ein ZIP-Archiv eingebettete Datei.
Experimentelle Mobipocket-Unterstützung: DocFetcher Pro und DocFetcher Server unterstützen das E-Book-Format Mobipocket mit der Dateiendung „mobi“. Beachten Sie jedoch, dass DocFetcher Pro und DocFetcher Server zwar insgesamt recht gut Text aus mobi-Dateien extrahieren, aber derzeit entweder einen kleinen Teil des Textes am Ende der Datei nicht extrahieren können oder in einigen Fällen vollständig scheitern. Daher ist die Mobipocket-Unterstützung vorerst als experimentell gekennzeichnet.
7z-Archivunterstützung für das aktuelle v0.4-Format: DocFetcher kann 7z-Archive bis zur Version v0.3 des 7z-Archivformats lesen. DocFetcher Pro und DocFetcher Server können auch 7z-Archive im aktuellen v0.4-Format lesen. Dieses v0.4-Format wurde mit 7-Zip 9.34 eingeführt, das am 23.11.2014 veröffentlicht wurde.
Erweiterte tar-Archivunterstützung: DocFetcher unterstützt die folgenden tar-Archiv-Erweiterungen: tar, tar.gz, tgz, tar.bz2, tb2, tbz. DocFetcher Pro und DocFetcher Server unterstützen zusätzlich die folgenden tar-Archiv-Erweiterungen: tbz2, tar.lzma, tlz, tar.xz, txz, tar.z, tz
Indizierung von Ordner- und Archivnamen: Im Gegensatz zu DocFetcher indizieren DocFetcher Pro und DocFetcher Server nicht nur reguläre Dateien, sondern auch Ordner und Archivdateien - oder genauer gesagt, die Namen von Ordnern und Archivdateien. Daher werden Ordner und Archivdateien in den Suchergebnissen von DocFetcher Pro und DocFetcher Server angezeigt. Es gibt auch einen Containertypen-Bereich auf der linken Seite des Hauptanwendungsfensters, um Ordner und/oder Archive von den Suchergebnissen auszuschließen.
macOS: Daemon für automatische Index-Aktualisierung: DocFetcher und DocFetcher Pro sind zur automatischen Index-Aktualisierung fähig, d.h. anstatt Index-Aktualisierungen manuell starten zu müssen, werden Index-Aktualisierungen vom Programm gestartet, sobald Dateiänderungen erkannt werden. Diese Funktionalität ist jedoch nur verfügbar, während die beiden Programme tatsächlich laufen. Wenn sie nicht laufen, wird ein separater Daemon-Prozess benötigt, um diese Lücke zu füllen. In DocFetcher ist der Daemon nur unter Windows und Linux verfügbar, während er in DocFetcher Pro auch unter macOS verfügbar ist. Für DocFetcher Server wird kein Daemon benötigt, da der Server für den kontinuierlichen Betrieb ausgelegt ist. Server Not available in DocFetcher Server
Intelligentere Dateinamenindizierung: Die Indizierung von Dateinamen in DocFetcher Pro und DocFetcher Server ist intelligenter als in DocFetcher. Wenn DocFetcher beispielsweise auf eine Datei mit dem Namen finde_diese_datei.pdf stößt, behandelt es „finde_diese_datei“ als ein einziges Wort, nicht als drei separate, aneinandergereihte Wörter. DocFetcher findet diese Datei also nur, wenn Sie in DocFetchers Suchfeld wörtlich „finde_diese_datei“ eingeben. DocFetcher Pro und DocFetcher Server hingegen finden die Datei, wenn Sie „finde_diese_datei“ oder eines der drei einzelnen Wörter eingeben. Allgemein ausgedrückt erkennen DocFetcher Pro und DocFetcher Server Zeichen wie den Unterstrich als potenzielle Worttrennzeichen.

Dateinamenindizierung im Fehlerfall: Wenn DocFetcher Pro und DocFetcher Server den Inhalt einer Datei aufgrund eines Fehlers oder eines Passwortschutzes nicht lesen können, wird der Dateiname trotzdem indiziert. In DocFetcher hingegen wird die Datei komplett übersprungen.
Keine Fehler bei tief verschachtelten Ordnerstrukturen: Beim Versuch, tief verschachtelte Ordnerstrukturen wie C:\ordner1\ordner2\...\ordner99\ordner100 zu indizieren, ist DocFetcher anfällig für einen Fehler „Ordnerhierarchie ist zu tief“. In Programmiererjargon wird dies als „Stack-Überlauf“ bezeichnet. DocFetcher Pro und DocFetcher Server hingegen sind völlig immun gegen diese Art von Fehler.
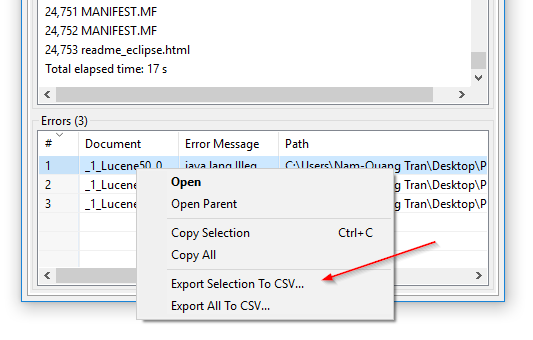
CSV-Export von Indizierungsfehlern: In DocFetcher Pro können Sie die Tabelle der Dateien, die das Programm während der Indizierung nicht lesen konnte, in eine CSV-Datei exportieren. Dies kann über das Kontextmenü der Fehlertabelle erfolgen, wie im folgenden Screenshot gezeigt. Diese Funktion ist derzeit nicht in DocFetcher Server verfügbar. Server Not available in DocFetcher Server
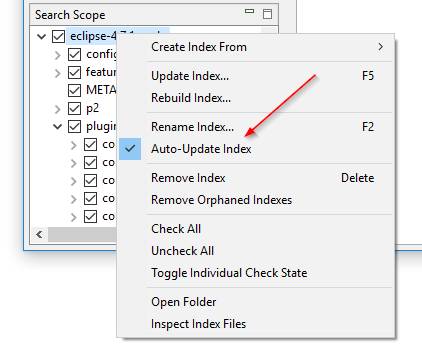
Ordnerüberwachung ein- und ausschalten ohne den Index neu zu erstellen: Die Einstellung „Automatische Detektion von Datei-Änderungen“ in DocFetcher, auch als Ordnerüberwachung bekannt, ist eine index-spezifische Einstellung, die, wenn sie aktiviert ist, das Programm veranlasst, den Index automatisch zu aktualisieren, wenn es Dateiänderungen im indizierten Ordner erkennt. Das Problem ist, dass wenn Sie diese Einstellung für einen bestimmten Index ein- oder ausschalten möchten, Sie den gesamten Index neu erstellen müssen. In DocFetcher Pro können Sie diese Einstellung ein- und ausschalten, ohne den Index neu zu erstellen, über das Kontextmenü des Suchbereichs. Außerdem wurde die Einstellung in „Index automatisch aktualisieren“ umbenannt. Ähnliche Funktionen gibt es in DocFetcher Server.
Gleichzeitiges Suchen und Neuerstellen von Indizes: In DocFetcher ist ein Index, wenn Sie sich entscheiden, ihn neu zu erstellen, während der Neuerstellung für die Suche nicht verfügbar. In DocFetcher Pro und DocFetcher Server hingegen bleibt der Index während der Neuerstellung durchsuchbar. (Genauer gesagt bleibt eine alte Kopie des Index durchsuchbar, während der eigentliche Index im Hintergrund neu erstellt wird.)
Windows: Verbesserte Behandlung von UNC-Pfaden: In DocFetcher ist die Behandlung von UNC-Pfaden unter Windows stark fehlerhaft und wurde in DocFetcher Pro von Grund auf neu konzipiert. Diese Neukonzeption wurde dann auf DocFetcher Server übertragen.
Nicht-modaler Indizierungsdialog: Im Gegensatz zum Indizierungsdialog von DocFetcher ist der Dialog in DocFetcher Pro „nicht-modal“, d.h. er ist nicht an das Hauptprogrammfenster gebunden und blockiert nicht die Eingabe in das Hauptprogrammfenster, während er geöffnet ist. Der Hauptvorteil dabei ist, dass Sie, während Indizierungsprozesse laufen, das Hauptprogrammfenster minimieren, aber den Indizierungsdialog sichtbar halten und zur Seite parken können. Dies ermöglicht es Ihnen, die Indizierungsprozesse im Auge zu behalten, während Sie in anderen Anwendungen arbeiten. Diese Funktion ist für DocFetcher Server nicht relevant. Server Not available in DocFetcher Server
Abspielen eines Tons nach der Indizierung: Standardmäßig spielt DocFetcher Pro nach der Indizierung einen „Fertig“-Ton ab. Diese Funktion kann in den Einstellungen deaktiviert werden. Diese Funktion ist derzeit nicht in DocFetcher Server verfügbar. Server Not available in DocFetcher Server
Indizierung japanischer Texte: DocFetcher verfügt über eine sogenannte „Wortsegmentierung“-Option, um brauchbare Suchergebnisse bei der Indizierung chinesischer Texte zu erhalten. DocFetcher Pro verfügt über eine zusätzliche Wortsegmentierungsoption für die Handhabung von japanischen Texten. Sowohl die chinesische als auch die japanische Wortsegmentierung sind derzeit in DocFetcher Server nicht verfügbar. Server Not available in DocFetcher Server